一、概述
Apache Doris(原百度 Palo)是一款基于大规模并行处理(MPP)技术的联机分析处理查询(OLAP)系统,由百度在 2017 年开源,2018 年 8 月进入 Apache 孵化。
MPP ( Massively Parallel Processing,大规模并行处理),在数据库非共享集群中,每个节点都有独立的磁盘存储系统和内存系统,业务数据根据数据库模型和应用特点划分到各个节点上,每台数据节点通过专用网络或者商业通用网络互相连接,彼此协同计算,作为整体提供数据库服务。非共享数据库集群有完全的可伸缩性、高可用、高性能、优秀的性价比、资源共享等优势。简单来说,MPP 是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果 ( 与 Hadoop 相似 )。
OLAP(On-line Analytical Processing,联机分析处理)是在基于数据仓库多维模型的基础上实现的面向分析的各类操作的集合。
Apache Doris 仅需亚秒级响应时间即可获得查询结果,有效地支持实时数据分析。Apache Doris的分布式架构非常简洁,易于运维,并且可以支持10PB以上的超大数据集。Apache Doris可以满足多种数据分析需求,例如固定历史报表,实时数据分析,交互式数据分析和探索式数据分析等。让数据分析工作更加简单高效!
Doris 主要解决 PB 级别的数据量(如果高于 PB 级别,不推荐使用 Doris 解决,可以考虑用 Hive 等工具),解决结构化数据,查询时间一般在秒级或毫秒级。
二、Doris 架构
2.1 整体架构
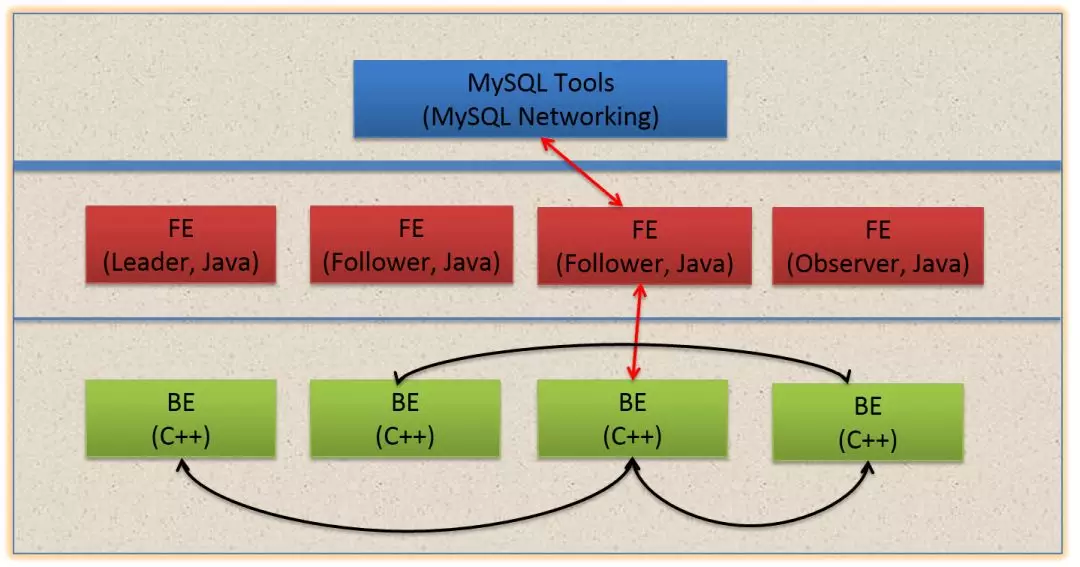
Doris 的架构很简洁,只设 FE(Frontend)、BE(Backend)两种角色,不依赖于外部组件,方便部署和运维。
- FE:Frontend,即 Doris 的前端节点。主要负责接收和返回客户端请求、元数据以及集群管理、查询计划生成等工作。
- BE:Backend,即 Doris 的后端节点。主要负责数据存储与管理、查询计划执行等工作。
在整个架构中FE,BE都可线性扩展。
FE 主要有有三个角色,一个是 leader,一个是 follower,还有一个 observer。leader 跟 follower,主要是用来达到元数据的高可用,保证单节点宕机的情况下,元数据能够实时地在线恢复,而不影响整个服务。
右边 observer 只是用来扩展查询节点,就是说如果在发现集群压力非常大的情况下,需要去扩展整个查询的能力,那么可以加 observer 的节点。observer 不参与任何的写入,只参与读取。
数据的可靠性由 BE 保证,BE 会对整个数据存储多副本或者是三副本。副本数可根据需求动态调整。
2.2 元数据
Doris 采用 Paxos 协议以及 Memory + Checkpoint + Journal 的机制来确保元数据的高性能及高可靠。元数据的每次更新,都首先写入到磁盘的日志文件中,然后再写到内存中,最后定期 checkpoint 到本地磁盘上。相当于是一个纯内存的一个结构,也就是说所有的元数据都会缓存在内存之中,从而保证 FE 在宕机后能够快速恢复元数据,而且不丢失元数据。Leader、follower 和 observer 它们三个构成一个可靠的服务,一般是部署一个 leader 两个 follower,在单机节点故障的时候其实基本上三个就够了,因为 FE 节点毕竟它只存了一份元数据,它的压力不大,所以如果 FE 太多的时候它会去消耗机器资源,所以多数情况下三个就足够了,可以达到一个很高可用的元数据服务。
在百度内部,一个包含2500张表,100万个分片(300万副本)的集群,元数据在内存中仅占用约 2GB。(当然,查询所使用的中间对象、各种作业信息等内存开销,需要根据实际情况估算。但总体依然维持在一个较低的内存开销范围内。)
同时,元数据在内存中整体采用树状的层级结构存储,并且通过添加辅助结构,能够快速访问各个层级的元数据信息。
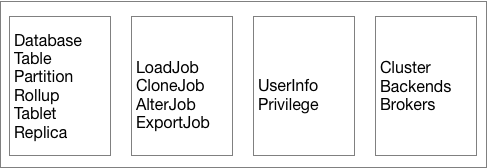
如上图,Doris 的元数据主要存储4类数据:
- 用户数据信息。包括数据库、表的 Schema、分片信息等。
- 各类作业信息。如导入作业,Clone 作业、SchemaChange 作业等。
- 用户及权限信息。
- 集群及节点信息。
2.3 数据流
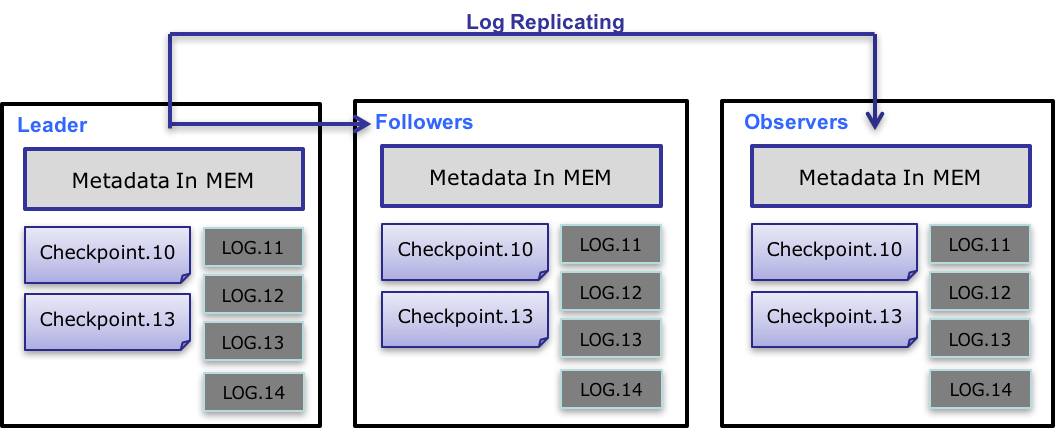
元数据的数据流具体过程如下:
- 只有 leader FE 可以对元数据进行写操作。写操作在修改 leader 的内存后,会序列化为一条log,按照 key-value 的形式写入 bdbje。其中 key 为连续的整型,作为 log id,value 即为序列化后的操作日志。
- 日志写入 bdbje 后,bdbje 会根据策略(写多数/全写),将日志复制到其他 non-leader 的 FE 节点。non-leader FE 节点通过对日志回放,修改自身的元数据内存镜像,完成与 leader 节点的元数据同步。
- leader 节点的日志条数达到阈值后(默认 10w 条),会启动 checkpoint 线程。checkpoint 会读取已有的 image 文件,和其之后的日志,重新在内存中回放出一份新的元数据镜像副本。然后将该副本写入到磁盘,形成一个新的 image。之所以是重新生成一份镜像副本,而不是将已有镜像写成 image,主要是考虑写 image 加读锁期间,会阻塞写操作。所以每次 checkpoint 会占用双倍内存空间。
- image 文件生成后,leader 节点会通知其他 non-leader 节点新的 image 已生成。non-leader 主动通过 http 拉取最新的 image 文件,来更换本地的旧文件。
- bdbje 中的日志,在 image 做完后,会定期删除旧的日志。
bdbje:Oracle Berkeley DB Java Edition (opens new window)。在 Doris 中,使用 bdbje 完成元数据操作日志的持久化、FE 高可用等功能。
2.3 实现细节
2.3.1 元数据目录
- 元数据目录通过 FE 的配置项
meta_dir指定。 bdb/目录下为 bdbje 的数据存放目录。image/目录下为 image 文件的存放目录。image.[logid]是最新的 image 文件。后缀logid表明 image 所包含的最后一条日志的 id。image.ckpt是正在写入的 image 文件,如果写入成功,会重命名为image.[logid],并替换掉旧的 image 文件。VERSION文件中记录着cluster_id。cluster_id唯一标识一个 Doris 集群。是在 leader 第一次启动时随机生成的一个 32 位整型。也可以通过 fe 配置项cluster_id来指定一个 cluster id。ROLE文件中记录的 FE 自身的角色。只有FOLLOWER和OBSERVER两种。其中FOLLOWER表示 FE 为一个可选举的节点。(注意:即使是 leader 节点,其角色也为FOLLOWER)
2.3.2 启动流程
FE 第一次启动,如果启动脚本不加任何参数,则会尝试以 leader 的身份启动。在 FE 启动日志中会最终看到
transfer from UNKNOWN to MASTER。FE 第一次启动,如果启动脚本中指定了
-helper参数,并且指向了正确的 leader FE 节点,那么该 FE 首先会通过 http 向 leader 节点询问自身的角色(即 ROLE)和 cluster_id。然后拉取最新的 image 文件。读取 image 文件,生成元数据镜像后,启动 bdbje,开始进行 bdbje 日志同步。同步完成后,开始回放 bdbje 中,image 文件之后的日志,完成最终的元数据镜像生成。注1:使用
-helper参数启动时,需要首先通过 mysql 命令,通过 leader 来添加该 FE,否则,启动时会报错。注2:
-helper可以指向任何一个 follower 节点,即使它不是 leader。注2:bdbje 在同步日志过程中,fe 日志会显示
xxx detached, 此时正在进行日志拉取,属于正常现象。FE 非第一次启动,如果启动脚本不加任何参数,则会根据本地存储的 ROLE 信息,来确定自己的身份。同时根据本地 bdbje 中存储的集群信息,获取 leader 的信息。然后读取本地的 image 文件,以及 bdbje 中的日志,完成元数据镜像生成。(如果本地 ROLE 中记录的角色和 bdbje 中记录的不一致,则会报错。)
FE 非第一次启动,且启动脚本中指定了
-helper参数。则和第一次启动的流程一样,也会先去询问 leader 角色。但是会和自身存储的 ROLE 进行比较。如果不一致,则会报错。
元数据读写与同步
用户可以使用 mysql 连接任意一个 FE 节点进行元数据的读写访问。如果连接的是 non-leader 节点,则该节点会将写操作转发给 leader 节点。leader 写成功后,会返回一个 leader 当前最新的 log id。之后,non-leader 节点会等待自身回放的 log id 大于回传的 log id 后,才将命令成功的消息返回给客户端。这种方式保证了任意 FE 节点的 Read-Your-Write 语义。
注:一些非写操作,也会转发给 leader 执行。比如
SHOW LOAD操作。因为这些命令通常需要读取一些作业的中间状态,而这些中间状态是不写 bdbje 的,因此 non-leader 节点的内存中,是没有这些中间状态的。(FE 之间的元数据同步完全依赖 bdbje 的日志回放,如果一个元数据修改操作不写 bdbje 日志,则在其他 non-leader 节点中是看不到该操作修改后的结果的。)leader 节点会启动一个 TimePrinter 线程。该线程会定期向 bdbje 中写入一个当前时间的 key-value 条目。其余 non-leader 节点通过回放这条日志,读取日志中记录的时间,和本地时间进行比较,如果发现和本地时间的落后大于指定的阈值(配置项:
meta_delay_toleration_second。写入间隔为该配置项的一半),则该节点会处于不可读的状态。此机制解决了 non-leader 节点在长时间和 leader 失联后,仍然提供过期的元数据服务的问题。各个 FE 的元数据只保证最终一致性。正常情况下,不一致的窗口期仅为毫秒级。我们保证同一 session 中,元数据访问的单调一致性。但是如果同一 client 连接不同 FE,则可能出现元数据回退的现象。(但对于批量更新系统,该问题影响很小。)
2.4 宕机恢复
- leader 节点宕机后,其余 follower 会立即选举出一个新的 leader 节点提供服务。
- 当多数 follower 节点宕机时,元数据不可写入。当元数据处于不可写入状态下,如果这时发生写操作请求,目前的处理流程是 FE 进程直接退出。后续会优化这个逻辑,在不可写状态下,依然提供读服务。
- observer 节点宕机,不会影响任何其他节点的状态。也不会影响元数据在其他节点的读写。
2.5 核心特性
MySQL协议兼容
Doris提供兼容MySQL协议的连接接口,使得用户不必再单独部署新的客户端库或者工具,可以直接使用MySQL的相关库或者工具;由于提供了MySQL接口,也容易与上层应用兼容;用户学习曲线降低,方便用户上手使用。
大查询高吞吐
利用MPP架构的优势,使得查询能够分布式的在多个节点并行执行,充分利用集群整体计算资源,提高大查询的吞吐能力。
高并发小查询
通过使用分区裁剪、预聚合,谓词下推,向量化执行、异步RPC等技术,Doris可以支持高并发点查询场景。100台集群可达10w QPS。
数据更新
Doris 支持按主键删除和更新数据。能够方便的从 MySQL 等事务数据库中同步实时更新的数据。
高可用和高可靠
Doris中的数据和元数据都默认使用3副本存储(Leader Node节点和Compute Node节点需各自大于等于3)。在少数节点宕机的情况下,依然可以保证数据的可靠性。 Doris会自动检查和修复损坏的数据,并将请求自动路由到健康的节点,7*24 小时保证数据的可用性。
水平扩展和数据均衡
Leader Node节点和Compute Node节点都可以进行横向扩展。用户可以根据计算和存储需要,灵活的对节点进行扩展。其中Compute Node节点在扩展后,Doris会自动根据节点间的负载情况,进行数据分片的自动均衡,无需人工干预。
物化视图和预聚合引擎
Doris支持通过物化视图或上卷表的形式对数据预聚合计算后的结果进行存储,从而加速部分聚合类场景的查询效率。同时,Doris能够保证物化视图和基础表之间的数据一致性,从而使得物化视图会查询和导入完全透明。Doris内部会自动根据用户的查询语句,选择合适的物化视图进行数据摄取。
丰富的数据导入功能和导入事务保证
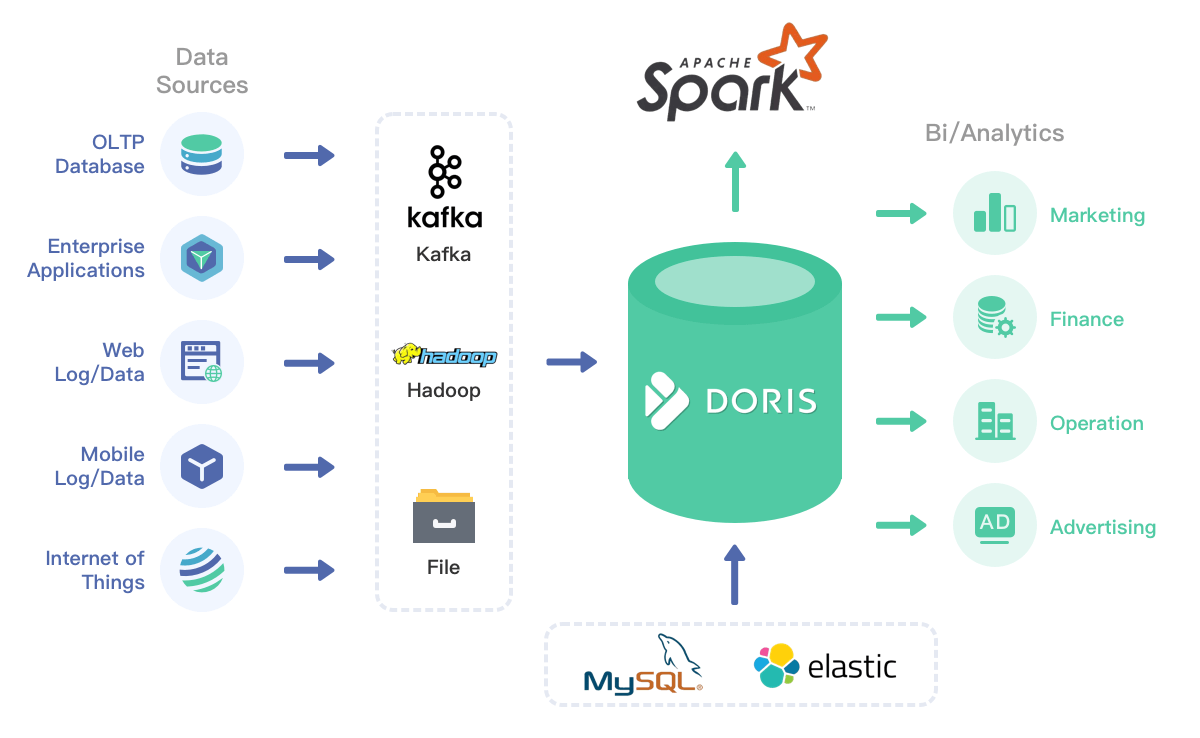
Doris支持多种导入方式。不仅支持近实时的流式导入,也支持大批量的数据导入。同时还可以直接订阅和消费kafka中的数据。Doris自身提供导入事务支持,配合导入Label机制,可以保证导入数据的不丢不重和原子一致性。
高效的列式存储引擎
Doris采用自研的列式存储格式来提升OLAP领域的查询效率。存储采用字典编码、RLE等多种编码方式,配合列式存储的特点,提供了非常高的数据压缩比,帮助用户节省存储空间。同时,存储格式上提供包括Min/Max智能索引、稀疏索引、布隆过滤器、bitmap倒排索引等多种查询加速技术,进一步提升了查询效率。
在线表结构修改
支持在已导入数据的情况下修改表结构,包括增加列、删除列、修改列类型和改变列顺序等操作。变更操作不会影响当前数据库的查询和写入操作。
丰富的生态
Doris可以方便的导入存储在对象存储、HDFS或Kafka中的数据。用户也可以通过Spark来直接查询Doris中存储的数据。而Doris也可以通过ODBC读取包括MySQL、PostgreSQL、SQLServer、Oracle等外部数据源的数据。同时,Doris也可以读取Elasticsearch中存储的数据,为Elasticsearch提供强大的分布式SQL查询层。
三、Doris 编译与部署
不想编译的话可以下载 Baidu Doris 团队基于 Apache Doris 的百度开源版本
3.1 编译
使用 Docker 开发镜像编译(推荐)
3.1.1 下载 Docker 镜像
1 | docker pull apache/incubator-doris:build-env-1.4.2 |
注:针对不同的 Doris 版本,需要下载对应的镜像版本
| 镜像版本 | commit id | doris 版本 |
|---|---|---|
| apache/incubator-doris:build-env | before ff0dd0d(opens new window) | 0.8.x, 0.9.x |
| apache/incubator-doris:build-env-1.1 | ff0dd0d(opens new window) | 0.10.x, 0.11.x |
| apache/incubator-doris:build-env-1.2 | 4ef5a8c(opens new window) | 0.12.x - 0.14.0 |
| apache/incubator-doris:build-env-1.3.1 | ad67dd3(opens new window) | 0.14.x |
| apache/incubator-doris:build-env-1.4.1 | 24d3861 (opens new window)or later | 0.15.x(releasing) |
| apache/incubator-doris:build-env-1.4.2 | a81f4da (opens new window)or later | 0.15.x(releasing) |
注意:
- doris 0.14.0 版本仍然使用apache/incubator-doris:build-env-1.2 编译,之后的代码将使用apache/incubator-doris:build-env-1.3.1。
- 在 build-env-1.3.1 的docker镜像中,同时包含了 OpenJDK 8 和 OpenJDK 11,并且默认使用 OpenJDK 11 编译。请确保编译使用的 JDK 版本和运行时使用的 JDK 版本一致,否则会导致非预期的运行错误。你可以使用在进入编译镜像的容器后,使用以下命令切换默认 JDK 版本:
切换到 JDK 8:
2
3
alternatives --set javac java-1.8.0-openjdk.x86_64
export JAVA_HOME=/usr/lib/jvm/java-1.8.0切换到 JDK 11:
2
3
alternatives --set javac java-11-openjdk.x86_64
export JAVA_HOME=/usr/lib/jvm/java-11
3.1.2 运行镜像
1 | docker run -it apache/incubator-doris:build-env-1.4.2 |
建议以挂载本地 Doris 源码目录的方式运行镜像,这样编译的产出二进制文件会存储在宿主机中,不会因为镜像退出而消失。
同时,建议同时将镜像中 maven 的 .m2 目录挂载到宿主机目录,以防止每次启动镜像编译时,重复下载 maven 的依赖库。
1 | docker run -it -v /your/local/.m2:/root/.m2 -v /your/local/incubator-doris-DORIS-x.x.x-release/:/root/incubator-doris-DORIS-x.x.x-release/ apache/incubator-doris:build-env-1.4.2 |
3.1.3 下载源码
启动镜像后,你应该已经处于容器内。可以通过以下命令下载 Doris 源码(已挂载本地源码目录则不用):
1 | wget https://dist.apache.org/repos/dist/dev/incubator/doris/xxx.tar.gz |
3.1.4 编译 Doris
编译FE,BE
1 | sh build.sh |
注意:
如果你使用的是
build-env-1.4.1这个环境,第一次编译的时候要使用如下命令:
这是因为1.4.1 版本镜像升级了 thrift(0.9 -> 0.13),需要通过 –clean 命令强制使用新版本的 thrift 生成代码文件,否则会出现不兼容的代码。
编译完成后,产出文件在 output/ 目录中。
编译Broker
1 | cd fs_brokers/apache_hdfs_broker/ |
编译完成后,产出文件在 output/ 目录中。
3.2 群集部署
3.2.1 官方建议配置
Linux 操作系统版本需求
| Linux 系统 | 版本 |
|---|---|
| CentOS | 7.1 及以上 |
| Ubuntu | 16.04 及以上 |
软件需求
| 软件 | 版本 |
|---|---|
| Java | 1.8 及以上 |
| GCC | 4.8.2 及以上 |
开发测试环境
| 模块 | CPU | 内存 | 磁盘 | 网络 | 实例数量 |
|---|---|---|---|---|---|
| Frontend | 8核+ | 8GB+ | SSD 或 SATA,10GB+ * | 千兆网卡 | 1 |
| Backend | 8核+ | 16GB+ | SSD 或 SATA,50GB+ * | 千兆网卡 | 1-3 * |
生产环境
| 模块 | CPU | 内存 | 磁盘 | 网络 | 实例数量(最低要求) |
|---|---|---|---|---|---|
| Frontend | 16核+ | 64GB+ | SSD 或 RAID 卡,100GB+ * | 万兆网卡 | 1-5 * |
| Backend | 16核+ | 64GB+ | SSD 或 SATA,100G+ * | 万兆网卡 | 10-100 * |
注1:
- FE 的磁盘空间主要用于存储元数据,包括日志和 image。通常从几百 MB 到几个 GB 不等。
- BE 的磁盘空间主要用于存放用户数据,总磁盘空间按用户总数据量 * 3(3副本)计算,然后再预留额外 40% 的空间用作后台 compaction 以及一些中间数据的存放。
- 一台机器上可以部署多个 BE 实例,但是只能部署一个 FE。如果需要 3 副本数据,那么至少需要 3 台机器各部署一个 BE 实例(而不是1台机器部署3个BE实例)。多个FE所在服务器的时钟必须保持一致(允许最多5秒的时钟偏差)
- 测试环境也可以仅适用一个 BE 进行测试。实际生产环境,BE 实例数量直接决定了整体查询延迟。
- 所有部署节点关闭 Swap。
注2:FE 节点的数量
- FE 角色分为 Follower 和 Observer,(Leader 为 Follower 组中选举出来的一种角色,以下统称 Follower,具体含义见 元数据设计文档)。
- FE 节点数据至少为1(1 个 Follower)。当部署 1 个 Follower 和 1 个 Observer 时,可以实现读高可用。当部署 3 个 Follower 时,可以实现读写高可用(HA)。
- Follower 的数量必须为奇数,Observer 数量随意。
- 根据以往经验,当集群可用性要求很高时(比如提供在线业务),可以部署 3 个 Follower 和 1-3 个 Observer。如果是离线业务,建议部署 1 个 Follower 和 1-3 个 Observer。
- 通常我们建议 10 ~ 100 台左右的机器,来充分发挥 Doris 的性能(其中 3 台部署 FE(HA),剩余的部署 BE)
- 当然,Doris的性能与节点数量及配置正相关。在最少4台机器(一台 FE,三台 BE,其中一台 BE 混部一个 Observer FE 提供元数据备份),以及较低配置的情况下,依然可以平稳的运行 Doris。
- 如果 FE 和 BE 混部,需注意资源竞争问题,并保证元数据目录和数据目录分属不同磁盘。
3.2.2 网络需求
Doris 各个实例直接通过网络进行通讯。以下表格展示了所有需要的端口
| 实例名称 | 端口名称 | 默认端口 | 通讯方向 | 说明 |
|---|---|---|---|---|
| BE | be_port | 9060 | FE –> BE | BE 上 thrift server 的端口,用于接收来自 FE 的请求 |
| BE | webserver_port | 8040 | BE <–> BE | BE 上的 http server 的端口 |
| BE | heartbeat_service_port | 9050 | FE –> BE | BE 上心跳服务端口(thrift),用于接收来自 FE 的心跳 |
| BE | brpc_port* | 8060 | FE<–>BE, BE <–> BE | BE 上的 brpc 端口,用于 BE 之间通讯 |
| FE | http_port * | 8030 | FE <–> FE,用户 | FE 上的 http server 端口 |
| FE | rpc_port | 9020 | BE –> FE, FE <–> FE | FE 上的 thrift server 端口,每个fe的配置需要保持一致 |
| FE | query_port | 9030 | 用户 | FE 上的 mysql server 端口 |
| FE | edit_log_port | 9010 | FE <–> FE | FE 上的 bdbje 之间通信用的端口 |
| Broker | broker_ipc_port | 8000 | FE –> Broker, BE –> Broker | Broker 上的 thrift server,用于接收请求 |
注:
- 当部署多个 FE 实例时,要保证 FE 的 http_port 配置相同。
- 部署前请确保各个端口在应有方向上的访问权限。
3.2.3 服务规划
服务规划
| 主机名 | doris角色 | 依赖服务 |
|---|---|---|
| hadoop1 | FE(Frontend)、BE(Backend) | JDK1.8、GCC4.8.2 及以上 |
| hadoop2 | BE(Backend) | JDK1.8、GCC4.8.2 及以上 |
| hadoop3 | BE(Backend) | JDK1.8、GCC4.8.2 及以上 |
前置条件
JDK和GCC是可用的
3.2.4 IP 绑定
因为有多网卡的存在,或因为安装过 docker 等环境导致的虚拟网卡的存在,同一个主机可能存在多个不同的 ip。当前 Doris 并不能自动识别可用 IP。所以当遇到部署主机上有多个 IP 时,必须通过 priority_networks 配置项来强制指定正确的 IP。
priority_networks 是 FE 和 BE 都有的一个配置,配置项需写在 fe.conf 和 be.conf 中。该配置项用于在 FE 或 BE 启动时,告诉进程应该绑定哪个IP。示例如下:
1 | priority_networks=10.1.3.0/24 |
这是一种 CIDR (opens new window)的表示方法。FE 或 BE 会根据这个配置项来寻找匹配的IP,作为自己的 localIP。
注意:当配置完 priority_networks 并启动 FE 或 BE 后,只是保证了 FE 或 BE 自身的 IP 进行了正确的绑定。而在使用 ADD BACKEND 或 ADD FRONTEND 语句中,也需要指定和 priority_networks 配置匹配的 IP,否则集群无法建立。举例:
BE 的配置为:priority_networks=10.1.3.0/24
但是在 ADD BACKEND 时使用的是:ALTER SYSTEM ADD BACKEND "192.168.0.1:9050";
则 FE 和 BE 将无法正常通信。
这时,必须 DROP 掉这个添加错误的 BE,重新使用正确的 IP 执行 ADD BACKEND。
FE 同理。
BROKER 当前没有,也不需要 priority_networks 这个选项。Broker 的服务默认绑定在 0.0.0.0 上。只需在 ADD BROKER 时,执行正确可访问的 BROKER IP 即可。
3.2.5 FE 部署
拷贝 FE 部署文件到指定节点
将源码编译生成的 output 下的 fe 文件夹拷贝到 FE 的节点指定部署路径下并进入该目录。
配置 FE
配置文件为 conf/fe.conf。其中注意:meta_dir是元数据存放位置。默认值为 ${DORIS_HOME}/doris-meta。需手动创建该目录。
注意:生产环境强烈建议单独指定目录不要放在Doris安装目录下,最好是单独的磁盘(如果有SSD最好),测试开发环境可以使用默认配置
fe.conf 中 JAVA_OPTS 默认 java 最大堆内存为 4GB,建议生产环境调整至 8G 以上。
启动FE
1 | [hadoop@hadoop1 ~/doris]$ sh fe/bin/start_fe.sh --daemon |
FE进程启动进入后台执行。日志默认存放在 log/ 目录下。如启动失败,可以通过查看 log/fe.log 或者 log/fe.out 查看错误信息。
查看 FE 进程
如果成功的话,可以通过jps查看到进程
1 | [hadoop@hadoop1 ~/doris]$ jps |grep PaloFe |
如需部署多 FE,请参见后面的 FE 扩容和缩容 部分
3.2.6 BE 部署
拷贝 BE 部署文件到所有要部署 BE 的节点
将源码编译生成的 output 下的 be 文件夹拷贝到 BE 的节点的指定部署路径下。
修改所有 BE 的配置
修改 be/conf/be.conf。主要是配置 storage_root_path:数据存放目录。默认在be/storage下,需要手动创建该目录。多个路径之间使用英文状态的分号 ; 分隔(最后一个目录后不要加 ;)。可以通过路径区别存储目录的介质,HDD或SSD。可以添加容量限制在每个路径的末尾,通过英文状态逗号,隔开。
示例1如下:
注意:如果是SSD磁盘要在目录后面加上
.SSD,HDD磁盘在目录后面加.HDDstorage_root_path=/home/disk1/doris.HDD,50;/home/disk2/doris.SSD,10;/home/disk2/doris
说明
/home/disk1/doris.HDD, 50,表示存储限制为50GB, HDD;
/home/disk2/doris.SSD 10, 存储限制为10GB,SSD;
/home/disk2/doris,存储限制为磁盘最大容量,默认为HDD。
示例2如下:
注意:不论HHD磁盘目录还是SSD磁盘目录,都无需添加后缀,storage_root_path参数里指定medium即可
storage_root_path=/home/disk1/doris,medium:hdd,capacity:50;/home/disk2/doris,medium:ssd,capacity:50
说明
/home/disk1/doris,medium:hdd,capacity:10,表示存储限制为10GB, HHD;
/home/disk2/doris,medium:ssd,capacity:50,表示存储限制为50GB, SSD;
BE webserver_port端口配置
如果 be 部署在 hadoop 集群中,注意调整 be.conf 中的 webserver_port = 8040 ,以免造成端口冲突
在 FE 中添加所有 BE 节点
BE 节点需要先在 FE 中添加,才可加入集群。可以使用 mysql-client(下载MySQL 5.7 (opens new window)) 连接到 FE:
1 | ./mysql-client -h host -P port -uroot |
其中 host 为 FE 所在节点 ip;port 为 fe/conf/fe.conf 中的 query_port;默认使用 root 账户,无密码登录。
登录后,执行以下命令来添加每一个 BE:
1 | ALTER SYSTEM ADD BACKEND "host:port"; |
其中 host 为 BE 所在节点 ip;port 为 be/conf/be.conf 中的 heartbeat_service_port。
启动 BE
1 | [hadoop@hadoop1 ~/doris]$ sh be/bin/start_be.sh --daemon |
BE 进程将启动并进入后台执行。日志默认存放在 be/log/ 目录下。如启动失败,可以通过查看 be/log/be.log 或者 be/log/be.out 查看错误信息。
查看BE状态
使用 mysql-client 连接到 FE,并执行 SHOW PROC '/backends'; 查看 BE 运行情况。如一切正常,Alive 列应为 true。

访问 FE UI 查询页面 fe.conf 配置的 http_port端口
3.2.7 FS_Broker 部署(可选)
Broker 以插件的形式,独立于 Doris 部署。如果需要从第三方存储系统导入数据,需要部署相应的 Broker,默认提供了读取 HDFS 和百度云 BOS 的 fs_broker。fs_broker 是无状态的,建议每一个 FE 和 BE 节点都部署一个 Broker。
拷贝源码 fs_broker 的 output 目录下的相应 Broker 目录到需要部署的所有节点上。建议和 BE 或者 FE 目录保持同级。
修改相应 Broker 配置
在相应 broker/conf/ 目录下对应的配置文件中,可以修改相应配置。启动 Broker
sh bin/start_broker.sh --daemon启动 Broker。添加 Broker
要让 Doris 的 FE 和 BE 知道 Broker 在哪些节点上,通过 sql 命令添加 Broker 节点列表。
使用 mysql-client 连接启动的 FE,执行以下命令:ALTER SYSTEM ADD BROKER broker_name "host1:port1","host2:port2",...;
其中 host 为 Broker 所在节点 ip;port 为 Broker 配置文件中的 broker_ipc_port。查看 Broker 状态
使用 mysql-client 连接任一已启动的 FE,执行以下命令查看 Broker 状态:SHOW PROC "/brokers";
注:在生产环境中,所有实例都应使用守护进程启动,以保证进程退出后,会被自动拉起,如 Supervisor。如需使用守护进程启动,在 0.9.0 及之前版本中,需要修改各个 start_xx.sh 脚本,去掉最后的 & 符号。从 0.10.0 版本开始,直接调用 sh start_xx.sh 启动即可。也可参考 这里
四、扩容缩容
Doris 可以很方便的扩容和缩容 FE、BE、Broker 实例。
4.1 FE 扩容和缩容
可以通过将 FE 扩容至 3 个以上节点来实现 FE 的高可用。
用户可以通过 mysql 客户端登陆 Master FE。通过:
1 | SHOW PROC '/frontends'; |
来查看当前 FE 的节点情况。
也可以通过前端页面连接:http://fe_hostname:fe_http_port/frontend 或者 http://fe_hostname:fe_http_port/system?path=//frontends 来查看 FE 节点的情况。
以上方式,都需要 Doris 的 root 用户权限。
FE 节点的扩容和缩容过程,不影响当前系统运行。
4.1.1 增加 FE 节点
FE 分为 Leader,Follower 和 Observer 三种角色。 默认一个集群,只能有一个 Leader,可以有多个 Follower 和 Observer。其中 Leader 和 Follower 组成一个 Paxos 选择组,如果 Leader 宕机,则剩下的 Follower 会自动选出新的 Leader,保证写入高可用。Observer 同步 Leader 的数据,但是不参加选举。如果只部署一个 FE,则 FE 默认就是 Leader。
第一个启动的 FE 自动成为 Leader。在此基础上,可以添加若干 Follower 和 Observer。
添加 Follower 或 Observer。使用 mysql-client 连接到已启动的 FE,并执行:
1 | ALTER SYSTEM ADD FOLLOWER "host:port"; |
或
1 | ALTER SYSTEM ADD OBSERVER "host:port"; |
其中 host 为 Follower 或 Observer 所在节点 ip,port 为其配置文件 fe.conf 中的 edit_log_port。
配置及启动 Follower 或 Observer。Follower 和 Observer 的配置同 Leader 的配置。第一次启动时,需执行以下命令:
1 | ./bin/start_fe.sh --helper host:port --daemon |
其中 host 为 Leader 所在节点 ip, port 为 Leader 的配置文件 fe.conf 中的 edit_log_port。--helper 参数仅在 follower 和 observer 第一次启动时才需要。
查看 Follower 或 Observer 运行状态。使用 mysql-client 连接到任一已启动的 FE,并执行:SHOW PROC '/frontends'; 可以查看当前已加入集群的 FE 及其对应角色。
FE 扩容注意事项:
- Follower FE(包括 Leader)的数量必须为奇数,建议最多部署 3 个组成高可用(HA)模式即可。
- 当 FE 处于高可用部署时(1个 Leader,2个 Follower),我们建议通过增加 Observer FE 来扩展 FE 的读服务能力。当然也可以继续增加 Follower FE,但几乎是不必要的。
- 通常一个 FE 节点可以应对 10-20 台 BE 节点。建议总的 FE 节点数量在 10 个以下。而通常 3 个即可满足绝大部分需求。
- helper 不能指向 FE 自身,必须指向一个或多个已存在并且正常运行中的 Master/Follower FE。
4.1.2 删除 FE 节点
使用以下命令删除对应的 FE 节点:
1 | ALTER SYSTEM DROP FOLLOWER[OBSERVER] "fe_host:edit_log_port"; |
FE 缩容注意事项:
- 删除 Follower FE 时,确保最终剩余的 Follower(包括 Leader)节点为奇数。
4.2 BE 扩容和缩容
用户可以通过 mysql-client 登陆 Leader FE。通过:
1 | SHOW PROC '/backends'; |
来查看当前 BE 的节点情况。
也可以通过前端页面连接:http://fe_hostname:fe_http_port/backend 或者 http://fe_hostname:fe_http_port/system?path=//backends 来查看 BE 节点的情况。
以上方式,都需要 Doris 的 root 用户权限。
BE 节点的扩容和缩容过程,不影响当前系统运行以及正在执行的任务,并且不会影响当前系统的性能。数据均衡会自动进行。根据集群现有数据量的大小,集群会在几个小时到1天不等的时间内,恢复到负载均衡的状态。集群负载情况,可以参见 Tablet 负载均衡文档。
4.2.1 增加 BE 节点
BE 节点的增加方式同 BE 部署 一节中的方式,通过 ALTER SYSTEM ADD BACKEND "host:port"; 命令增加 BE 后 sh be/bin/start_be.sh --daemon 启动节点。
BE 扩容注意事项:
- BE 扩容后,Doris 会自动根据负载情况,进行数据均衡,期间不影响使用。
4.2.2 删除 BE 节点
删除 BE 节点有两种方式:DROP 和 DECOMMISSION
DROP 语句如下:
1 | ALTER SYSTEM DROP BACKEND "be_host:be_heartbeat_service_port"; |
注意:DROP BACKEND 会直接删除该 BE,并且其上的数据将不能再恢复!!!所以我们强烈不推荐使用 DROP BACKEND 这种方式删除 BE 节点。当你使用这个语句时,会有对应的防误操作提示。
DECOMMISSION 语句如下:
1 | ALTER SYSTEM DECOMMISSION BACKEND "be_host:be_heartbeat_service_port"; |
DECOMMISSION 命令说明:
- 该命令用于安全删除 BE 节点。命令下发后,Doris 会尝试将该 BE 上的数据向其他 BE 节点迁移,当所有数据都迁移完成后,Doris 会自动删除该节点。
- 该命令是一个异步操作。执行后,可以通过
SHOW PROC '/backends';看到该 BE 节点的 isDecommission 状态为 true。表示该节点正在进行下线。- 该命令不一定执行成功。比如剩余 BE 存储空间不足以容纳下线 BE 上的数据,或者剩余机器数量不满足最小副本数时,该命令都无法完成,并且 BE 会一直处于 isDecommission 为 true 的状态。
- DECOMMISSION 的进度,可以通过
SHOW PROC '/backends';中的 TabletNum 查看,如果正在进行,TabletNum 将不断减少。- 该操作可以通过:
CANCEL DECOMMISSION BACKEND "be_host:be_heartbeat_service_port";
命令取消。取消后,该 BE 上的数据将维持当前剩余的数据量。后续 Doris 重新进行负载均衡
对于多租户部署环境下,BE 节点的扩容和缩容,请参阅 多租户设计文档。
4.3 Broker 扩容缩容
Broker 实例的数量没有硬性要求。通常每台物理机部署一个即可。Broker 的添加和删除可以通过以下命令完成:
1 | ALTER SYSTEM ADD BROKER broker_name "broker_host:broker_ipc_port"; |
Broker 是无状态的进程,可以随意启停。当然,停止后,正在其上运行的作业会失败,重试即可。
五、最佳实践
5.1 建表
5.1.1 数据模型选择
Doris 数据模型上目前分为三类: AGGREGATE KEY, UNIQUE KEY, DUPLICATE KEY。三种模型中数据都是按KEY进行排序。
5.1.1.1 AGGREGATE KEY
AGGREGATE KEY相同时,新旧记录进行聚合,目前支持的聚合函数有SUM, MIN, MAX, REPLACE。
AGGREGATE KEY模型可以提前聚合数据, 适合报表和多维分析业务。
1 | CREATE TABLE site_visit |
5.1.1.2 UNIQUE KEY
UNIQUE KEY 相同时,新记录覆盖旧记录。目前 UNIQUE KEY 实现上和 AGGREGATE KEY 的 REPLACE 聚合方法一样,二者本质上相同。适用于有更新需求的分析业务。
1 | CREATE TABLE sales_order |
5.1.1.3 DUPLICATE KEY
只指定排序列,相同的行不会合并。适用于数据无需提前聚合的分析业务。
1 | CREATE TABLE session_data |
5.1.2 大宽表与 Star Schema
业务方建表时, 为了和前端业务适配, 往往不对维度信息和指标信息加以区分, 而将 Schema 定义成大宽表。对于 Doris 而言, 这类大宽表往往性能不尽如人意:
- Schema 中字段数比较多, 聚合模型中可能 key 列比较多, 导入过程中需要排序的列会增加。
- 维度信息更新会反应到整张表中,而更新的频率直接影响查询的效率。
使用过程中,建议用户尽量使用 Star Schema 区分维度表和指标表。频繁更新的维度表也可以放在 MySQL 外部表中。而如果只有少量更新, 可以直接放在 Doris 中。在 Doris 中存储维度表时,可对维度表设置更多的副本,提升 Join 的性能。
5.1.3 分区和分桶
Doris 支持两级分区存储, 第一层为分区(partition),目前支持 RANGE 分区和 LIST 分区两种类型, 第二层为 HASH 分桶(bucket)。
5.1.3.1 分区(partition)
分区用于将数据划分成不同区间, 逻辑上可以理解为将原始表划分成了多个子表。可以方便的按分区对数据进行管理,例如,删除数据时,更加迅速。
5.1.3.1.1 RANGE分区
业务上,多数用户会选择采用按时间进行partition, 让时间进行partition有以下好处:
- 可区分冷热数据;
- 可用上Doris分级存储(SSD + SATA)的功能。
5.1.3.1.2 LIST分区
业务上,用户可以选择城市或者其他枚举值进行partition。
5.1.3.2 HASH分桶(bucket)
根据hash值将数据划分成不同的 bucket。
- 建议采用区分度大的列做分桶, 避免出现数据倾斜;
- 为方便数据恢复, 建议单个 bucket 的 size 不要太大, 保持在 10GB 以内, 所以建表或增加 partition 时请合理考虑 bucket 数目, 其中不同 partition 可指定不同的 buckets 数。
5.1.4 稀疏索引和 Bloom Filter
Doris对数据进行有序存储, 在数据有序的基础上为其建立稀疏索引,索引粒度为 block(1024行)。
稀疏索引选取 schema 中固定长度的前缀作为索引内容, 目前 Doris 选取 36 个字节的前缀作为索引。
- 建表时建议将查询中常见的过滤字段放在 Schema 的前面, 区分度越大,频次越高的查询字段越往前放。
- 这其中有一个特殊的地方,就是 varchar 类型的字段。varchar 类型字段只能作为稀疏索引的最后一个字段。索引会在 varchar 处截断, 因此 varchar 如果出现在前面,可能索引的长度可能不足 36 个字节。具体可以参阅 数据模型、ROLLUP 及前缀索引。
- 除稀疏索引之外, Doris还提供bloomfilter索引, bloomfilter索引对区分度比较大的列过滤效果明显。 如果考虑到varchar不能放在稀疏索引中, 可以建立bloomfilter索引。
5.1.5 物化视图(rollup)
Rollup 本质上可以理解为原始表(Base Table)的一个物化索引。建立 Rollup 时可只选取 Base Table 中的部分列作为 Schema。Schema 中的字段顺序也可与 Base Table 不同。
下列情形可以考虑建立 Rollup:
5.1.5.1 Base Table 中数据聚合度不高
这一般是因 Base Table 有区分度比较大的字段而导致。此时可以考虑选取部分列,建立 Rollup。
如对于 site_visit 表:
1 | site_visit(siteid, city, username, pv) |
siteid 可能导致数据聚合度不高,如果业务方经常根据城市统计pv需求,可以建立一个只有 city, pv 的 Rollup:
1 | ALTER TABLE site_visit ADD ROLLUP rollup_city(city, pv); |
5.1.5.2 Base Table 中的前缀索引无法命中
这一般是 Base Table 的建表方式无法覆盖所有的查询模式。此时可以考虑调整列顺序,建立 Rollup。
如对于 session_data 表:
1 | session_data(visitorid, sessionid, visittime, city, province, ip, brower, url) |
如果除了通过 visitorid 分析访问情况外,还有通过 brower, province 分析的情形,可以单独建立 Rollup。
1 | ALTER TABLE session_data ADD ROLLUP rollup_brower(brower,province,ip,url) DUPLICATE KEY(brower,province); |
5.2 Schema Change
Doris中目前进行 Schema Change 的方式有三种:Sorted Schema Change,Direct Schema Change, Linked Schema Change。
2.1. Sorted Schema Change
改变了列的排序方式,需对数据进行重新排序。例如删除排序列中的一列, 字段重排序。
1 | ALTER TABLE site_visit DROP COLUMN city; |
2.2. Direct Schema Change: 无需重新排序,但是需要对数据做一次转换。例如修改列的类型,在稀疏索引中加一列等。
1 | ALTER TABLE site_visit MODIFY COLUMN username varchar(64); |
2.3. Linked Schema Change: 无需转换数据,直接完成。例如加列操作。
1 | ALTER TABLE site_visit ADD COLUMN click bigint SUM default '0'; |
建表时建议考虑好 Schema,这样在进行 Schema Change 时可以加快速度。
六、权限管理
Doris 新的权限管理系统参照了 Mysql 的权限管理机制,做到了表级别细粒度的权限控制,基于角色的权限访问控制,并且支持白名单机制。
6.1 名词解释
用户标识 user_identity
在权限系统中,一个用户被识别为一个 User Identity(用户标识)。用户标识由两部分组成:username 和 userhost。其中 username 为用户名,由英文大小写组成。userhost 表示该用户链接来自的 IP。user_identity 以 username@'userhost' 的方式呈现,表示来自 userhost 的 username。
user_identity 的另一种表现方式为 username@['domain'],其中 domain 为域名,可以通过 DNS 或 BNS(百度名字服务)解析为一组 ip。最终表现为一组 username@'userhost',所以后面我们统一使用 username@'userhost' 来表示。权限 Privilege
权限作用的对象是节点、数据库或表。不同的权限代表不同的操作许可。
角色 Role
Doris可以创建自定义命名的角色。角色可以被看做是一组权限的集合。新创建的用户可以被赋予某一角色,则自动被赋予该角色所拥有的权限。后续对角色的权限变更,也会体现在所有属于该角色的用户权限上。
用户属性 user_property
用户属性直接附属于某一用户,而不是用户标识。即 cmy@'192.%' 和 cmy@['domain'] 都拥有同一组用户属性,该属性属于用户 cmy,而不是 cmy@'192.%' 或 cmy@['domain']。
用户属性包括但不限于: 用户最大连接数、导入集群配置等等。
6.2 支持的操作
- 创建用户:CREATE USER
- 删除用户:DROP USER
- 授权:GRANT
- 撤权:REVOKE
- 创建角色:CREATE ROLE
- 删除角色:DROP ROLE
- 查看当前用户权限:SHOW GRANTS
- 查看所有用户权限:SHOW ALL GRANTS
- 查看已创建的角色:SHOW ROLES
- 查看用户属性:SHOW PROPERTY
关于以上命令的详细帮助,可以通过 mysql 客户端连接 Doris 后,使用 help + command 获取帮助。如 HELP CREATE USER。
6.3 权限类型
Doris 目前支持以下几种权限
Node_priv
节点变更权限。包括 FE、BE、BROKER 节点的添加、删除、下线等操作。目前该权限只能授予 Root 用户。
Grant_priv
权限变更权限。允许执行包括授权、撤权、添加/删除/变更 用户/角色 等操作。
Select_priv
对数据库、表的只读权限。
Load_priv
对数据库、表的写权限。包括 Load、Insert、Delete 等。
Alter_priv
对数据库、表的更改权限。包括重命名 库/表、添加/删除/变更 列、添加/删除 分区等操作。
Create_priv
创建数据库、表、视图的权限。
Drop_priv
删除数据库、表、视图的权限。
Usage_priv
资源的使用权限。
6.4 权限层级
同时,根据权限适用范围的不同,我们将库表的权限分为以下三个层级:
- GLOBAL LEVEL:全局权限。即通过 GRANT 语句授予的
*.*上的权限。被授予的权限适用于任意数据库中的任意表。 - DATABASE LEVEL:数据库级权限。即通过 GRANT 语句授予的
db.*上的权限。被授予的权限适用于指定数据库中的任意表。 - TABLE LEVEL:表级权限。即通过 GRANT 语句授予的
db.tbl上的权限。被授予的权限适用于指定数据库中的指定表。
将资源的权限分为以下两个层级:
- GLOBAL LEVEL:全局权限。即通过 GRANT 语句授予的
*上的权限。被授予的权限适用于资源。 - RESOURCE LEVEL: 资源级权限。即通过 GRANT 语句授予的
resource_name上的权限。被授予的权限适用于指定资源。
6.5 ADMIN/GRANT 权限说明
ADMIN_PRIV 和 GRANT_PRIV 权限同时拥有授予权限的权限,较为特殊。这里对和这两个权限相关的操作逐一说明。
- CREATE USER
- 拥有 ADMIN 权限,或任意层级的 GRANT 权限的用户可以创建新用户。
- DROP USER
- 只有 ADMIN 权限可以删除用户。
- CREATE/DROP ROLE
- 只有 ADMIN 权限可以创建角色。
- GRANT/REVOKE
- 拥有 ADMIN 权限,或者 GLOBAL 层级 GRANT 权限的用户,可以授予或撤销任意用户的权限。
- 拥有 DATABASE 层级 GRANT 权限的用户,可以授予或撤销任意用户对指定数据库的权限。
- 拥有 TABLE 层级 GRANT 权限的用户,可以授予或撤销任意用户对指定数据库中指定表的权限。
- SET PASSWORD
- 拥有 ADMIN 权限,或者 GLOBAL 层级 GRANT 权限的用户,可以设置任意用户的密码。
- 普通用户可以设置自己对应的 UserIdentity 的密码。自己对应的 UserIdentity 可以通过
SELECT CURRENT_USER();命令查看。 - 拥有非 GLOBAL 层级 GRANT 权限的用户,不可以设置已存在用户的密码,仅能在创建用户时指定密码。
6.6 一些说明
Doris 初始化时,会自动创建如下用户和角色:
- operator 角色:该角色拥有 Node_priv 和 Admin_priv,即对Doris的所有权限。后续某个升级版本中,我们可能会将该角色的权限限制为 Node_priv,即仅授予节点变更权限。以满足某些云上部署需求。
- admin 角色:该角色拥有 Admin_priv,即除节点变更以外的所有权限。
- root@'%':root 用户,允许从任意节点登陆,角色为 operator。
- admin@'%':admin 用户,允许从任意节点登陆,角色为 admin。
不支持删除或更改默认创建的角色或用户的权限。
operator 角色的用户有且只有一个。admin 角色的用户可以创建多个。
一些可能产生冲突的操作说明
域名与ip冲突:
假设创建了如下用户:
CREATE USER cmy@['domain'];
并且授权:
GRANT SELECT_PRIV ON *.* TO cmy@['domain']
该 domain 被解析为两个 ip:ip1 和 ip2
假设之后,我们对 cmy@'ip1' 进行一次单独授权:
GRANT ALTER_PRIV ON . TO cmy@'ip1';
则 cmy@'ip1' 的权限会被修改为 SELECT_PRIV, ALTER_PRIV。并且当我们再次变更 cmy@['domain'] 的权限时,cmy@'ip1' 也不会跟随改变。
重复ip冲突:
假设创建了如下用户:
CREATE USER cmy@'%' IDENTIFIED BY "12345";
CREATE USER cmy@'192.%' IDENTIFIED BY "abcde";
在优先级上,'192.%' 优先于 '%',因此,当用户 cmy 从 192.168.1.1 这台机器尝试使用密码 '12345' 登陆 Doris 会被拒绝。
忘记密码
如果忘记了密码无法登陆 Doris,可以在 Doris FE 节点所在机器,使用如下命令无密码登陆 Doris:
mysql-client -h 127.0.0.1 -P query_port -uroot登陆后,可以通过 SET PASSWORD 命令重置密码。
任何用户都不能重置 root 用户的密码,除了 root 用户自己。
ADMIN_PRIV 权限只能在 GLOBAL 层级授予或撤销。
拥有 GLOBAL 层级 GRANT_PRIV 其实等同于拥有 ADMIN_PRIV,因为该层级的 GRANT_PRIV 有授予任意权限的权限,请谨慎使用。
current_user()和user()用户可以通过
SELECT current_user();和SELECT user();分别查看current_user和user。其中current_user表示当前用户是以哪种身份通过认证系统的,而user则是用户当前实际的user_identity。举例说明:假设创建了
user1@'192.%'这个用户,然后以为来自 192.168.10.1 的用户 user1 登陆了系统,则此时的current_user为user1@'192.%',而user为user1@'192.168.10.1'。所有的权限都是赋予某一个
current_user的,真实用户拥有对应的current_user的所有权限。
6.7 最佳实践
这里举例一些 Doris 权限系统的使用场景。
场景一
Doris 集群的使用者分为管理员(Admin)、开发工程师(RD)和用户(Client)。其中管理员拥有整个集群的所有权限,主要负责集群的搭建、节点管理等。开发工程师负责业务建模,包括建库建表、数据的导入和修改等。用户访问不同的数据库和表来获取数据。
在这种场景下,可以为管理员赋予 ADMIN 权限或 GRANT 权限。对 RD 赋予对任意或指定数据库表的 CREATE、DROP、ALTER、LOAD、SELECT 权限。对 Client 赋予对任意或指定数据库表 SELECT 权限。同时,也可以通过创建不同的角色,来简化对多个用户的授权操作。
场景二
一个集群内有多个业务,每个业务可能使用一个或多个数据。每个业务需要管理自己的用户。在这种场景下。管理员用户可以为每个数据库创建一个拥有 DATABASE 层级 GRANT 权限的用户。该用户仅可以对用户进行指定的数据库的授权。
黑名单
Doris 本身不支持黑名单,只有白名单功能,但我们可以通过某些方式来模拟黑名单。假设先创建了名为
user@'192.%'的用户,表示允许来自192.*的用户登录。此时如果想禁止来自192.168.10.1的用户登录。则可以再创建一个用户cmy@'192.168.10.1'的用户,并设置一个新的密码。因为192.168.10.1的优先级高于192.%,所以来自192.168.10.1将不能再使用旧密码进行登录。