Presto 是由 Facebook 推出的一个基于Java开发的开源分布式SQL查询引擎,数据量支持GB到TB字节,presto本身不存数据,但是可以接入很多数据源,它使得用SQL访问任何数据源成为可能,而且支持跨数据源的级联查询。你可以使用Presto通过水平扩展查询处理的方式来查询大型数据集。
发展历史如下:
- 2012年秋季,Facebook启动Presto项目;
- 2013年冬季,Presto开源;
- 2017年11月,11888 commits,203 releases,198 contributors;
- 2019年1月,Presto分家,目前有 PrestoDB 和 PrestoSQL(Trino) 两个社区。
一、Presto 架构组成
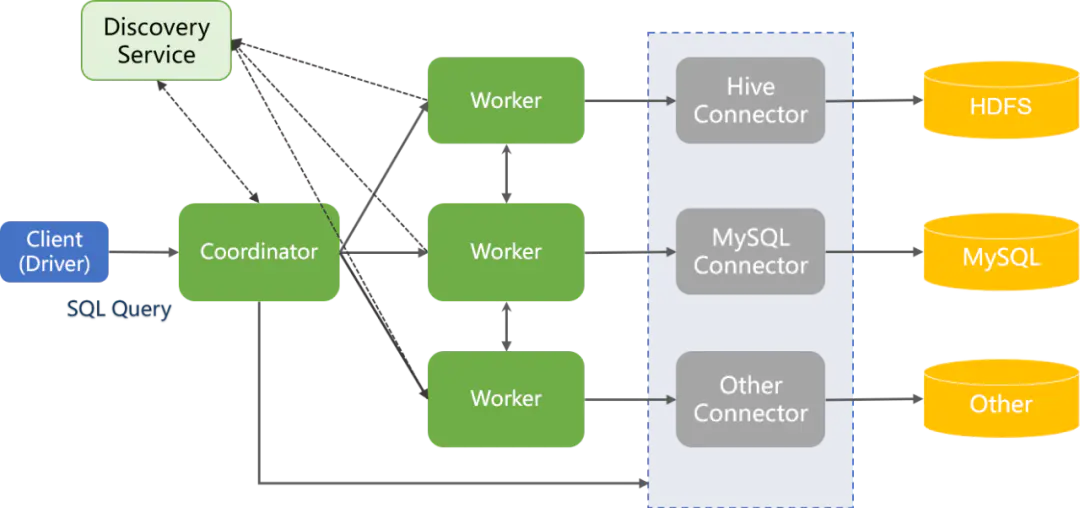
1.1 Presto 服务器类型
1.1.1 Coordinator
集群的管理节点
1)对外负责管理集群与客户端的连接,并接收客户端查询请求;
2)进行SQL的语法解析、查询计划生成和优化,并进行查询任务的调度;
3)Discovery Server节点,跟踪Worker节点的状态,通常内嵌于Coordinator节点中;
4)部署情况:一般作为单独节点部署在集群中;
5)通信方式:使用RESTful接口与客户端、Workers进行交互。
1.1.2 Worker
集群的工作节点
1)用于执行被分解后的查询任务(task)及与数据的读写交互;
2)部署情况:一般集群中部署多个worker节点;
3)通信方式:使用RESTful接口与Coordinator、其他Workers进行交互。
1.2 Presto 数据源
1.2.1 Connector
Presto通过connector可以访问多种不同的数据源,connector相当于数据库访问的驱动。每种connector通过实现Presto的SPI接口实现数据源的标准接入。
1.2.2 Catalog
Presto Catalog目录包含架构并通过连接器引用数据源。例如,您可以配置 JMX 目录以通过 JMX 连接器提供对 JMX 信息的访问。当您在 Presto 中运行 SQL 语句时,您是在针对一个或多个目录运行它。目录的其他示例包括用于连接到 Hive 数据源的 Hive 目录。
在 Presto 中寻址表时,完全限定的表名始终以目录为根。例如,一个完全合格的表名称hive.test_data.test将引用test表中 test_data的架构hive目录。
目录在存储在 Presto 配置目录中的属性文件中定义。
1.2.3 Schema
Schema是一种组织表格的方式。Catalog和Schema一起定义了一组可以查询的表。使用 Presto 访问 Hive 或关系数据库(例如 MySQL)时,Schema会转换为目标数据库中的database。其他类型的连接器可能会选择以对底层数据源有意义的方式将表组织成模式。
1.2.4 Table
数据表,与任何关系数据库中的概念类似。从源数据到表的映射由connector定义。
1.3 presto 查询模型
1.3.1 Statement
Statement:语句,其实就是输入的SQL;
1.3.2 Query
Query:根据SQL语句生成查询执行计划,进而生成可以执行的查询(Query),一个Query包含stages、tasks、splits、connectors等组件和相应的数据源这些概念;
1.3.3 Stage
Stage:当Presto执行Query时,会将query拆分成具有层次关系的多个stages。一个Query的stages之间是树形的层次结构,每一个Query都有一个Root stage,用于聚合所有其他Stages的输出数据。Stage只是coordinator用于分布式查询计划(query plan)建模的逻辑概念,本身并不会执行在Presto Workers上;
1.3.4 Exchange
Exchange:Exchange用于不同Presto节点间查询的不同stages数据交换。Task生产数据放入输出Buffer中,也可以通过exchange客户端从其他task消费数据
1.3.5 Task
Task:Presto是通过Task来运行的,一个分布式查询计划(query plan)被拆解成一些列的stage,一个stage分解成一系列并行执行的task,每个task被分解成一个或多个并行的driver,每个driver作用于一系列splist上,每个task都有对应的输入输出;
1.3.6 Driver
Driver:Drivers处理数据,并由task聚合后传给下游stage的一个task。一个Driver就是作用于一个split上的一系列operator的集合。Driver是Presto架构最底层的并行处理单元。每个Driver都有一个输入和一个输出。
1.3.7 Operator
Operator:一个operator代表对一个split的一种操作,一个Operator依次读取一个Split中的数据,将Operator所代表的计算和操作应用于该split上,并产生输出。
1.3.8 Split
Split:分片,一个分片就是一个大的数据集中的一个小的子集,位于分布式query plan中较低层次的stages从数据源获取splits,位于较高层次的中间stages则从其他stages获取数据。
二、Presto 其它特性
2.1 presto SQL执行步骤
1)客户端通过http发送一个查询语句给presto集群的coordinator;
2)coordinator接收到客户端的查询语句,对语句进行解析,生成查询执行计划,并根据生成的执行计划生成stage和task,并将task分发到需要处理数据的worker上进行分析;
3)worker执行task,task通过connector从数据源中读取需要的数据;
4)上游stage输出的结果给到下游stage作为输入,每个Stage的每个task在worker内存中进行计算和处理;
5)client从提交查询后,就一直监听coordinator中的查询结果,一有结果就立即输出,直到轮询所有的结果都返回,则本次查询结束。
2.2 Presto 低延时查询原理
- 得益于 YARN 调度的慢。YARN 的定位是一个通用的资源管理系统。但是无论是 Hive 采用 MR、TEZ 何种引擎,执行 SQL时,每个执行算子都在 Yarn Container 中运行,而 Yarn 拉起 Container 性能特别低(秒级)。这犹如应用程序在拉起进程和开启多线程一样。线程更轻量级,简单的运算开启线程的速度更快,加速更明显;而启用进程则要笨重的多,还容易受到操作系统限制。而 Presto 调度的确就是用了线程,而不是进程。
- Presto 的Coordinator/Worker 架构更像 Spark Standalone 模式,只在两个进程和服务中完成。但是Spark更多侧重于 SparkRDD之间依赖关系,Stage失败线性恢复等功能导致有较大开销。Spark Input也直接依赖Hadoop InputFormat API,导致SparkSQL在运行时,并不能把 SQL 优化细节传导到 InputFormat。Presto 弃用 Hadoop InputFormat,但采用类似的数据分区技术,并且可以把 SQL 经过解析后,把Where 条件生成 TupleDomain 传递给 Connector。Connector 能根据字段元数据采用一定程度的索引下推,利用底层系统的索引能力,大大减少数据扫描区间和参与计算的数据量。
- Presto 是完全基于内存的并行计算,他不像 Hive MR/TEZ 需要把中间数据写盘、Spark 需要把溢出的数据写盘,Presto 是完全假设数据能有效的放入内存。再者,得益于Presto流水线式的作业计算能力,在很多 SQL 执行时通过分析SQL的执行计划,能把立即展现的数据立即返回。这也是给用户一种很快的“假象”。但这种“假象”也是无可厚非的,我们即便是从一个结果中提取大量数据,也是遍历游标,等到我们遍历到那个位置,后续的结果数据已经源源不断的计算完成,并不影响我们获得结果
2.3 Presto 的优点与不足
2.3.1 presto 优点
1)多数据源:Presto支持MySQL、PostgreSQL、Cassandra、Hive、Kafka、JMX等,多数据源及多数据源之间混合计算;
2)支持 ANSI SQL:Presto支持ANSI SQL,并提供了一个SQL Shell给用户,用户可以直接使用ANSI SQL进行数据查询和计算;
3)扩展性:Presto有很好的扩展性,开发人员可以很容易地开发出适用于自己特定数据源的Connector,并且可以使用SQL语句查询和分析自定义Connector中的数据;
4)混合计算:在数据库中每种类型的数据源都对应于一种特定类型的Connector,用户可以根据业务需要在Presto中针对于一种类型的Connector配置一个或者多个Catalog并查询其中的数据,用户可以混合多个Catalog进行join查询和计算;
5)高性能:低延迟高并发的内存计算引擎,相对hive,无论是mr还是tez还是spark执行引擎,至少提升10倍以上 ;
6)流水线:presto是基于pipeline进行设计,在进行少量数据处理的过程中,用户无需等到所有数据计算完成才能看到结果,一旦开始计算就可产生一部分结果返回,后续的计算结果以多个page返回给终端用户(Driver)。
2.3.2 Presto 不足
通过 Presto 执行流程的架构,可以看出 Presto 在查询上也存在一些不足:
1)没有容错能力:当一个 query 分发到多个 Worker 去执行时,当有一个 Worker 因为各种原因查询失败,Master 感知到之后,整个 query 也会失败。
2)内存限制:由于 Presto 是纯内存计算,所以当内存不够时,Presto 并不会将结果 dump 到磁盘上,所以查询也就失败了。
3)并行查询:因为所有的 task 都是并行执行,如果其中一台 Worker 因为各种原因查询很慢,那么整个 query 就会变得很慢。
4)并发限制:因为全内存操作+内存限制,能同时处理的数据量有限,因而导致并发能力不足。
2.4 Presto 应用场景
1)实时计算:Presto 性能优越,实时查询工具上的重要选择;
2)Ad-Hoc查询:数据分析应用、Presto 根据特定条件的查询返回结果和生成报表;
3)ETL:因支持的数据源广泛、可用于不同数据库之间迁移,转换 和 完成 ETL 清洗的能力;
4)实时数据流分析:Presto-Kafka Connector 使用 SQL对Kafka的数据流进行清洗、分析;
5)作为MPP:Presto Connector 有非常好的扩展性,可进行扩展开发,可支持其他异构非SQL查询引擎转为SQL,支持索引下推。
Ad-Hoc:即席查询(Ad Hoc)是用户根据自己的需求,灵活的选择查询条件,系统能够根据用户的选择生成相应的统计报表。即席查询与普通应用查询最大的不同是普通的应用查询是定制开发的,而即席查询是由用户自定义查询条件的。
ETL:(Extract-Transform-Load )用来描述将数据从来源端经过萃取(Extract)、转置(Transform)、加载(Load)至目的端的过程。
MPP:Massively Parallel Processor,翻译过来就是大规模并行处理。
2.5 presto 和hive 的对比
hive和presto是针对不同使用场景的。presto虽然查询很快,但是也不是适用于所有的查询场景。
比如做多张大表的关联查询,由于presto是基于内存查询的。做大表关联查询时,数据要加载到内存中,假如使用presto查询超过了几分钟才会有返回。且严重影响集群的性能。这就违背了presto交互式查询的初衷,交互式就是要做到近实时查询与返回。所以,presto不适合做多张大表的join操作或者ETL操作。这种情况就该使用hive了。
虽然能够处理 PB 级别的海量数据分析,但不是代表 Presto 把 PB 级别都放在内存中计算的。而是根据场景,如 count,avg 等聚合运算,是边读数据边计算,再清内存,再读数据再计算,这种耗的内存并不高。但是连表查,就可能产生大量的临时数据,因此速度会变慢,反而 Hive此时会更擅长。
另外,hive只能做hdfs查询(es等需要插件支持),而presto支持了mysql,pg,kafka,redis等。presto是支持多数据源的查询利器。
三、Presto的优化
Presto 的优化是一个非常有水平的问题,大致总结下,分如下几个类别
3.1数据存储
想要使用 Presto 更高效地查询数据,需要在数据存储方面利用一些优化手段。
3.1.1 合理设置分区
与 Hive 类似,Presto 会根据元数据信息读取分区数据,合理地设置分区能减少 Presto 数据读取量,提升查询性能。
3.1.2 使用 ORC 格式存储
Presto 对 ORC文件 读取进行了特定优化,因此,在 Hive 中创建 Presto 使用的表时,建议采用 ORC 格式存储。相对于 Parquet 格式,Presto 对 ORC 格式支持得更好。
3.1.3 使用压缩
数据压缩可以减少节点间数据传输对 IO 带宽的压力,对于即席查询需要快速解压,建议采用 Snappy压缩。
3.1.4 预先排序
对于已经排序的数据,在查询的数据过滤阶段,ORC格式支持跳过读取不必要的数据。比如对于经常需要过滤的字段可以预先排序。
1 | INSERT INTO table nation_orc partition(p) SELECT * FROM nation SORT BY n_name; |
如果需要过滤 n_name 字段,则性能将提升。
1 | SELECT count(*) FROM nation_orc WHERE n_name=’AUSTRALIA’; |
3.2 SQL查询
想要使用 Presto更高效地查询数据,需要在编写查询SQL语句方面利用一些优化手段。
3.2.1 只选择需要的字段
由于采用列式存储,所以只选择需要的字段可加快字段的读取速度,减少数据量。避免采用 * 读取所有字段。
1 | [GOOD]: SELECT time,user,host FROM tbl[BAD]: SELECT * FROM tbl |
3.2.2 过滤条件必须加上分区字段
对于有分区的表,where语句中优先使用分区字段进行过滤。acct_day 是分区字段,visit_time 是具体访问时间。
1 | [GOOD]: SELECT time,user,host FROM tbl where acct_day=20171101[BAD]: SELECT * FROM tbl where visit_time=20171101 |
3.2.3 Group By语句优化
合理安排 Group by语句中字段顺序对性能有一定提升。将 Group By 语句中字段按照每个字段 distinct 数据多少进行降序排列。
1 | [GOOD]: SELECT GROUP BY uid, gender |
3.2.4 Order by时使用Limit
Order by 需要扫描数据到单个 worker 节点进行排序,导致单个worker需要大量内存。如果是查询 Top N 或者 Bottom N,使用 limit 可减少排序计算和内存压力。
1 | [GOOD]: SELECT * FROM tbl ORDER BY time LIMIT 100[BAD]: SELECT * FROM tbl ORDER BY time |
3.2.5 使用近似聚合函数
Presto有一些近似聚合函数,对于允许有少量误差的查询场景,使用这些函数对查询性能有大幅提升。比如使用approx_distinct()函数比Count(distinct x)有大概2.3%的误差。
1 | SELECT approx_distinct(user_id) FROM access |
3.2.6 用regexp_like代替多个like语句
Presto查询优化器没有对多个 like 语句进行优化,使用regexp_like对性能有较大提升。
1 | [GOOD]: SELECT ...FROM accessWHERE regexp_like(method, 'GET|POST|PUT|DELETE') |
3.2.7 使用Join语句时将大表放在左边
Presto中 join 的默认算法是broadcast join,即将 join 左边的表分割到多个 worker ,然后将join 右边的表数据整个复制一份发送到每个worker进行计算。如果右边的表数据量太大,则可能会报内存溢出错误。
1 | [GOOD]: SELECT ... FROM large_table l join small_table s on l.id = s.id |
3.2.8 使用Rank函数代替row_number函数来获取Top N
在进行一些分组排序场景时,使用rank函数性能更好
1 | [GOOD]: SELECT checksum(rnk)FROM ( SELECT rank() OVER (PARTITION BY l_orderkey, l_partkey ORDER BY l_shipdate DESC) AS rnk FROM lineitem) tWHERE rnk = 1 |
3.3 注意事项
ORC和Parquet 都支持列式存储,但是ORC对Presto支持更好(Parquet对Impala支持更好)
对于列式存储而言,存储文件为二进制的,对于经常增删字段的表,建议不要使用列式存储(修改文件元数据代价大)。对比数据仓库,DWD层建议不要使用ORC,而DM层则建议使用。
3.3.1 字段名引用
避免和关键字冲突:MySQL对字段加反引号`、Presto对字段加双引号分割;当然,如果字段名称不是关键字,可以不加这个双引号。
3.3.2 时间函数
对于Timestamp,需要进行比较的时候,需要添加Timestamp关键字,而MySQL中对Timestamp可以直接进行比较。
1 | /*MySQL的写法*/ |
3.3.3 不支持INSERT OVERWRITE语法
Presto中不支持 insert overwrite 语法,只能先 delete,然后 insert into。
3.3.4 PARQUET格式
Presto目前支持Parquet格式,支持查询,但不支持insert。
四、Presto 部署
4.1 Presto 单节点部署
4.1.1 下载 presto
1 | [hadoop@hadoop1 ~/downloads]$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.265.1/presto-server-0.265.1.tar.gz |
4.1.2 配置 presto
配置 node.properties
1 | [hadoop@hadoop1 ~]$ tar xf downloads/presto-server-0.265.1.tar.gz |
node.environment:环境名称。群集中的所有Presto节点必须具有相同的环境名称;
node.id:唯一的标识符 每个节点的node.id 需要不一样;
node.data-dir:数据目录的位置。Presto将在此处存储日志和其他数据。
配置 jvm.config
1 | [hadoop@hadoop1 ~/presto-server-0.265.1]$ vim etc/jvm.config |
配置 config.properties
1 | [hadoop@hadoop1 ~/presto-server-0.265.1]$ vim etc/config.properties |
coordinator:允许这个 Presto 实例充当协调器(接受来自客户端的查询并管理查询执行)。
node-scheduler.include-coordinator:允许在协调器上安排工作。对于较大的集群,协调器上的处理工作会影响查询性能,因为机器的资源无法用于调度、管理和监控查询执行的关键任务。
http-server.http.port: 指定 HTTP 服务器的端口。Presto 使用 HTTP 进行所有内部和外部通信。
query.max-memory:查询可以使用的最大分布式内存量。
query.max-memory-per-node:查询可以在任何一台机器上使用的最大用户内存量。
query.max-total-memory-per-node:查询在任何一台机器上可能使用的最大用户和系统内存量,其中系统内存是读取器、写入器和网络缓冲区等在执行过程中使用的内存。
discovery-server.enabled:Presto 使用 Discovery 服务查找集群中的所有节点。每个 Presto 实例都会在启动时向 Discovery 服务注册自己。为了简化部署并避免运行额外的服务,Presto 协调器可以运行一个嵌入式版本的 Discovery 服务。它与 Presto 共享 HTTP 服务器,因此使用相同的端口。
discovery.uri:发现服务器的 URI。因为我们在 Presto 协调器中启用了 Discovery 的嵌入式版本,所以这应该是 Presto 协调器的 URI。替换example.net:8080以匹配 Presto 协调器的主机和端口。此 URI 不得以斜杠结尾。
配置 log.properties
1 | [hadoop@hadoop1 ~/presto-server-0.265.1]$ vim etc/log.properties |
4.1.3 运行 presto
1 | [hadoop@hadoop1 ~/presto-server-0.265.1]$ ./bin/launcher start |
bin/launcher start 作为守护进程后台运行
bin/launcher run 则是在前台运行
4.1.4 访问 WEB UI
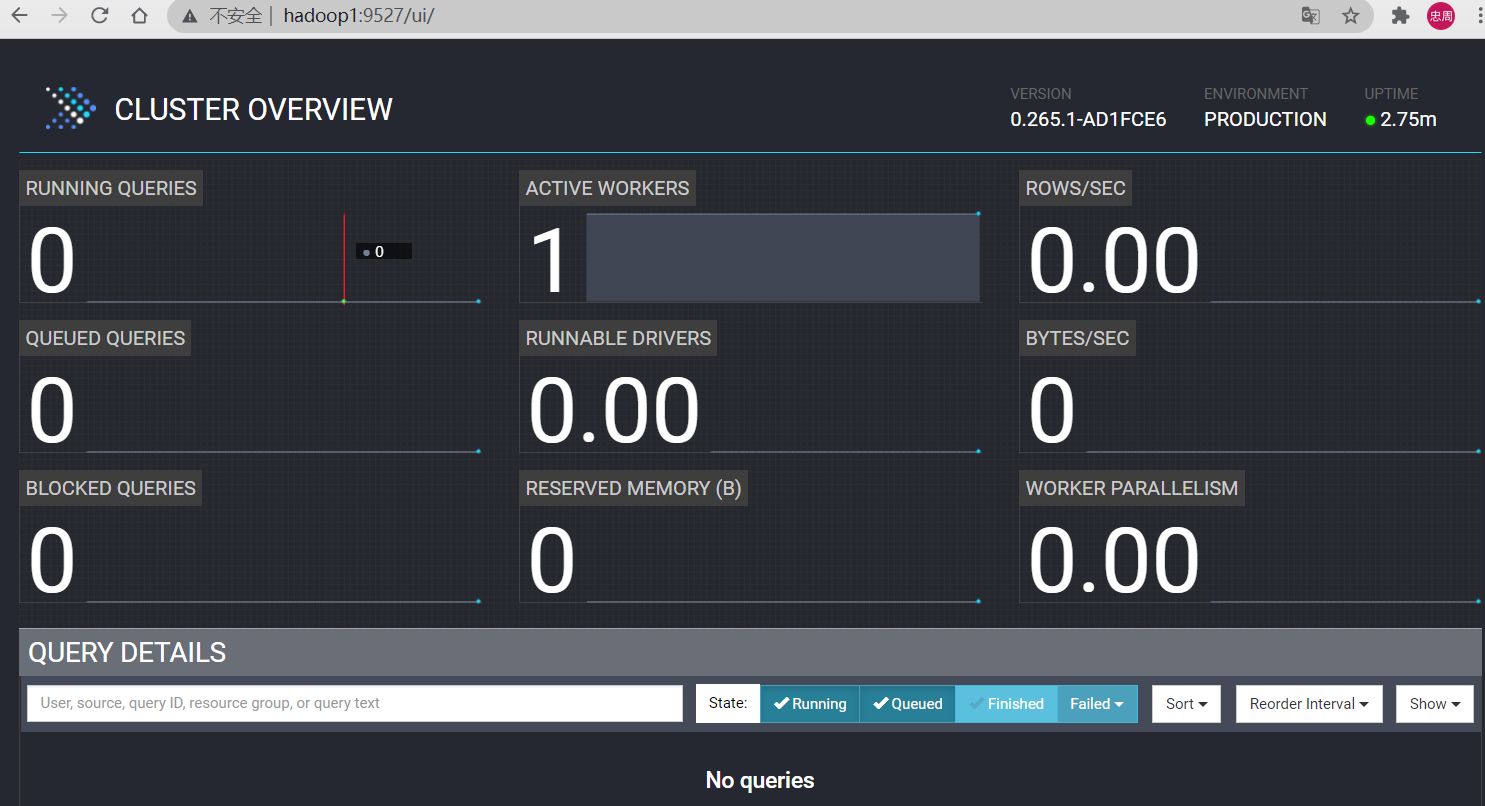
4.2 Presto 集群部署
服务规划
| 主机名 | Presto角色 |
|---|---|
| hadoop1 | Coordinator |
| hadoop2 | Worker |
| hadoop3 | Worker |
4.2.1 Coordinator 节点配置
下载 presto
1 | [hadoop@hadoop1 ~/downloads]$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.265.1/presto-server-0.265.1.tar.gz |
配置 presto
配置 node.properties
1 | [hadoop@hadoop1 ~]$ tar xf downloads/presto-server-0.265.1.tar.gz |
配置 jvm.config
1 | [hadoop@hadoop1 ~/presto-server-0.265.1]$ vim etc/jvm.config |
配置 config.properties
每台Presto服务器都可以充当协调器和工作器。但是专用于一台计算机仅执行协调工作的服务器可以在较大的群集上提供最佳性能。
1 | [hadoop@hadoop1 ~/presto-server-0.265.1]$ vim etc/config.properties |
配置 log.properties
1 | [hadoop@hadoop1 ~/presto-server-0.265.1]$ vim etc/log.properties |
4.2.2 Worker 节点配置
将Coordinator 的presto分发到其它 Worker节点
1 | [hadoop@hadoop1 ~/presto-server-0.265.1]$ rsync -av presto-server-0.265.1 hadoop@hadoop2:~/ |
修改 node.properties 配置文件,中的 node.id 配置项,每个节点应该是唯一的
1 | [hadoop@hadoop2 ~/presto-server-0.265.1]$ vim etc/node.properties |
修改 config.properties 配置文件
1 | [hadoop@hadoop2 ~/presto-server-0.265.1]$ vim etc/config.properties |
4.2.3 运行 presto
集群启动方式与单点的一样,每台都启动起来即可使用。
1 | [hadoop@hadoop1 ~/presto-server-0.265.1]$ ./bin/launcher start |
4.2.4 访问 WEB UI
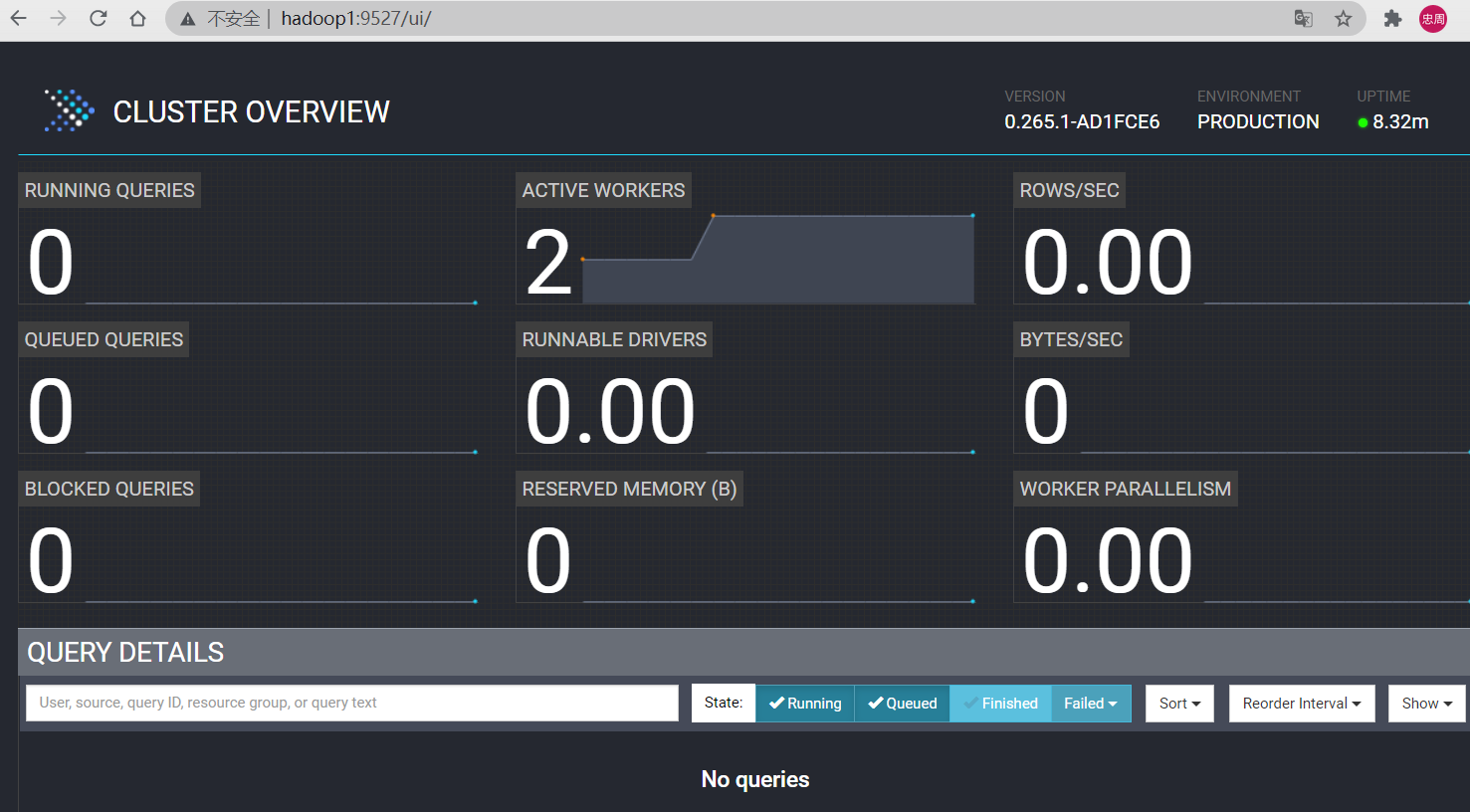
4.3 Prest 添加MySQL数据源
要配置MySQL连接器,请在etc/catalog命名中创建目录属性文件
1 | [hadoop@hadoop1 ~/presto-server-0.265.1]$ mkdir etc/catalog |
配置 mysql Connector,在所有节点上配置
1 | [hadoop@hadoop1 ~/presto-server-0.265.1]$ vim etc/catalog/mysql.properties |
重启presto服务,重启所有节点的presto服务
1 | [hadoop@hadoop1 ~/presto-server-0.265.1]$ ./bin/launcher stop |
客户端工具连接presto,使用dbeaver客户端连接presto
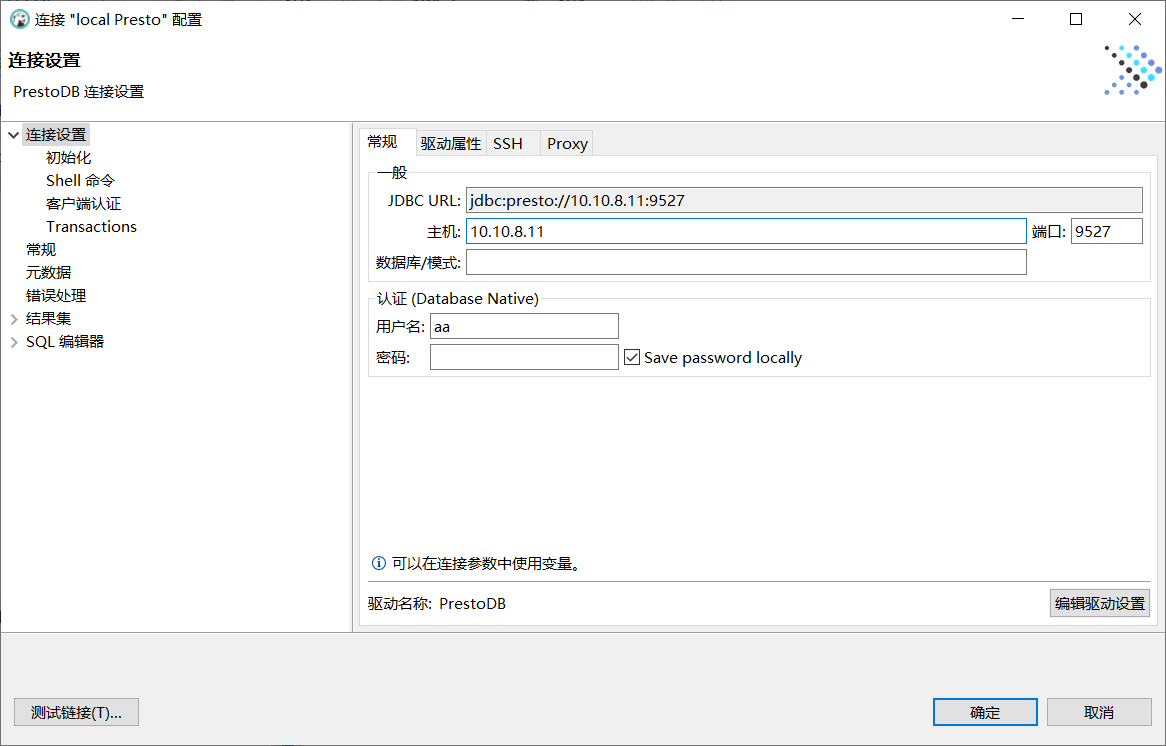
4.4 Presto 添加 Hive数据源
配置 hive Connector
1 | [hadoop@hadoop1 ~/presto-server-0.265.1]$ vim etc/catalog/hive.properties |
对于基本设置,Presto 会自动配置 HDFS 客户端,不需要任何配置文件。在某些情况下,例如使用联合 HDFS 或 NameNode 高可用性时,需要指定额外的 HDFS 客户端选项才能访问您的 HDFS 集群。为此,添加hive.config.resources属性以引用您的 HDFS 配置文件。
如果presto运行在非hadoop节点上,则需要将hadoop的core-site.xml 和 hdfs-site.xml配置文件拷贝到所有presto节点上。
1 | [hadoop@hadoop1 ~/presto-server-0.265.1]$ cp /home/hadoop/hadoop-2.7.2/etc/hadoop/{core,hdfs}-site.xml etc/cluster/ |
重启所有节点presto服务
1 | [hadoop@hadoop1 ~/presto-server-0.265.1]$ ./bin/launcher stop |
4.5 Presto 基于文件的用户管理配置(不完整,待补充)
启用密码文件身份认证,设置 etc/config.properties 中的密码验证类型
1 | =PASSWORD |
添加 etc/password-authenticator.properties 配置文件,使用file身份验证器名称在协调器上创建一个文件
1 | [hadoop@hadoop1 ~/presto-server-0.265.1]$ vim etc/password-authenticator.properties |
可用的配置属性有
file.password-file密码文件的路径。 file.refresh-period重新加载密码文件的频率。默认为 5s.file.auth-token-cache.max-size缓存的已验证密码的最大数量。默认为 1000.
创建密码文件
添加用于hive认证的用户
1 | 创建密码文件 |
配置基于文件的系统访问控制
1 | [hadoop@hadoop1 ~/presto-server-0.265.1]$ vim etc/access-control.properties |
配置hive用户访问权限规则
例如,如果你想只允许用户admin访问 mysql和hive目录,允许所有用户访问hive 目录,允许用户hive2用户访问mysql目录,可以使用以下规则
1 | [hadoop@hadoop1 ~/presto-server-0.265.1]$ vim etc/rules.json |
以上只能对访问的用户进行权限绑定,至于账户密码认证需要做一些开发上的修改,可以参考:https://blog.csdn.net/a80090023/article/details/119616321