一、Flink local 模式
1.1 配置jdk环境
1 | [hadoop@hadoop1 ~]$ tar xf downloads/jdk-8u301-linux-x64.tar.gz |
1.2 部署flink
1 | [hadoop@hadoop1 ~/downloads]$ wget https://dlcdn.apache.org/flink/flink-1.14.0/flink-1.14.0-bin-scala_2.11.tgz |
1.3 访问 web 页面
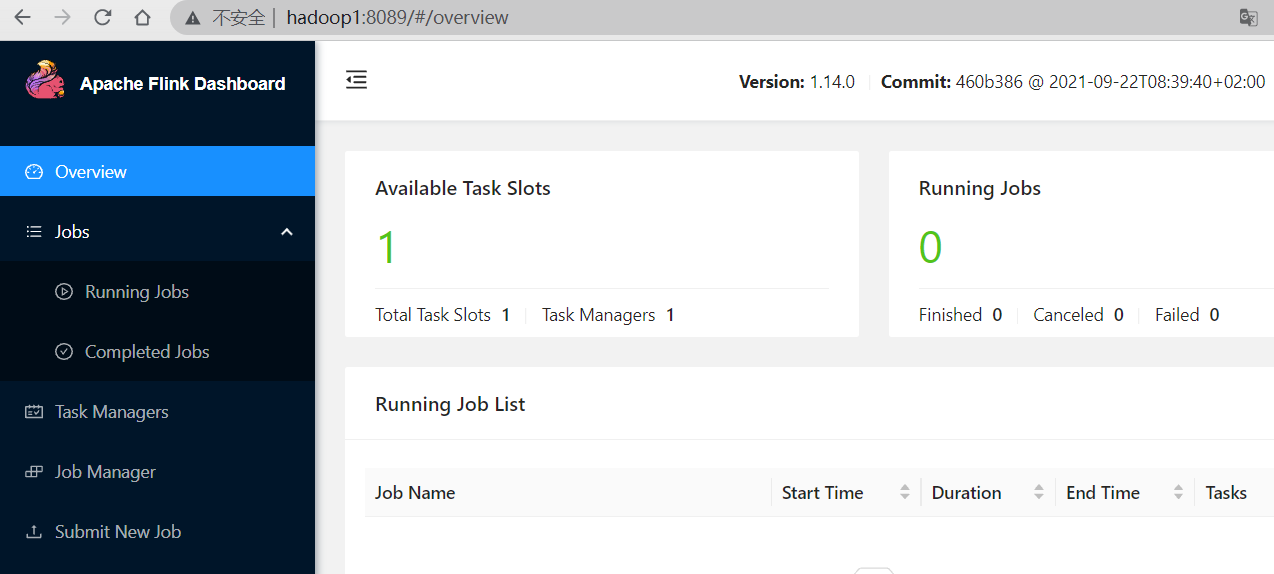
默认端口8081,端口冲突可以修改 conf/flink-conf.yaml 配置项 rest.port: 进行修改
1.4 提交作业(Job)
Flink 的 Releases 附带了许多的示例作业。可以任意选择一个,快速部署到已运行的集群上。
1 | [hadoop@hadoop1 ~/flink-1.14.0]$ ./bin/flink run examples/streaming/WordCount.jar |
flink run命令参数
-c,–class <classname>: Flink应用程序的入口
-C,–classpath <url>: 指定所有节点都可以访问到的url,可用于多个应用程序都需要的工具类加载
-d,–detached: 是否使用分离模式,就是提交任务,cli是否退出,加了-d参数,cli会退出
-n,–allowNonRestoredState: 允许跳过无法还原的savepoint。比如删除了代码中的部分operator
-p,–parallelism <parallelism>: 执行并行度
-s,–fromSavepoint: 从savepoint恢复任务
-sae,–shutdownOnAttachedExit: 以attached模式提交,客户端退出的时候关闭集群
flink yarn-cluster: 模式
yarn-cluster模式
-d,–detached: 是否使用分离模式
-m,–jobmanager <arg>: 指定提交的jobmanager
-yat,–yarnapplicationType <arg>: 设置yarn应用的类型
-yD <property=value>: 使用给定属性的值
-yd,–yarndetached: 使用yarn分离模式
-yh,–yarnhelp: yarn session的帮助
-yid,–yarnapplicationId <arg>: 挂到正在运行的yarnsession上
-yj,–yarnjar <arg>: Flink jar文件的路径
-yjm,–yarnjobManagerMemory <arg>: jobmanager的内存(单位M)
-ynl,–yarnnodeLabel <arg>: 指定 YARN 应用程序 YARN 节点标签
-ynm,–yarnname <arg>: 自定义yarn应用名称
-yq,–yarnquery: 显示yarn的可用资源
-yqu,–yarnqueue <arg>: 指定yarn队列
-ys,–yarnslots <arg>: 指定每个taskmanager的slots数
-yt,–yarnship <arg>: 在指定目录中传输文件
-ytm,–yarntaskManagerMemory <arg>: 每个taskmanager的内存
-yz,–yarnzookeeperNamespace <arg>: 用来创建ha的zk子路径的命名空间
-z,–zookeeperNamespace <arg>: 用来创建ha的zk子路径的命名空间
通用CLI模式
-D <property=value>:允许指定多个常规配置选项。有关可用选项,请访问 https://nightlies.apache.org/flink/flink-docs-stable/ops/config.html
-e,–executor <arg>:不推荐:请改用-t选项,该选项在”Application Mode”中也可用。用于执行给定作业的执行器的名称,相当于“execution.target”配置选项。当前可用的执行器有:”remote”, “local”, “kubernetes-session”, “yarn-per-job”, “yarn-session”。
-t,–target <arg>:给定应用程序的部署目标,相当于”execution.target”配置选项。对于“run”操作,当前可用的目标有:”remote”, “local”, “kubernetes-session”,”yarn-per-job”, “yarn-session”。对于”run-application”操作,当前可用的有:”kubernetes-application”,”yarn-application”。
通过web查看运行情况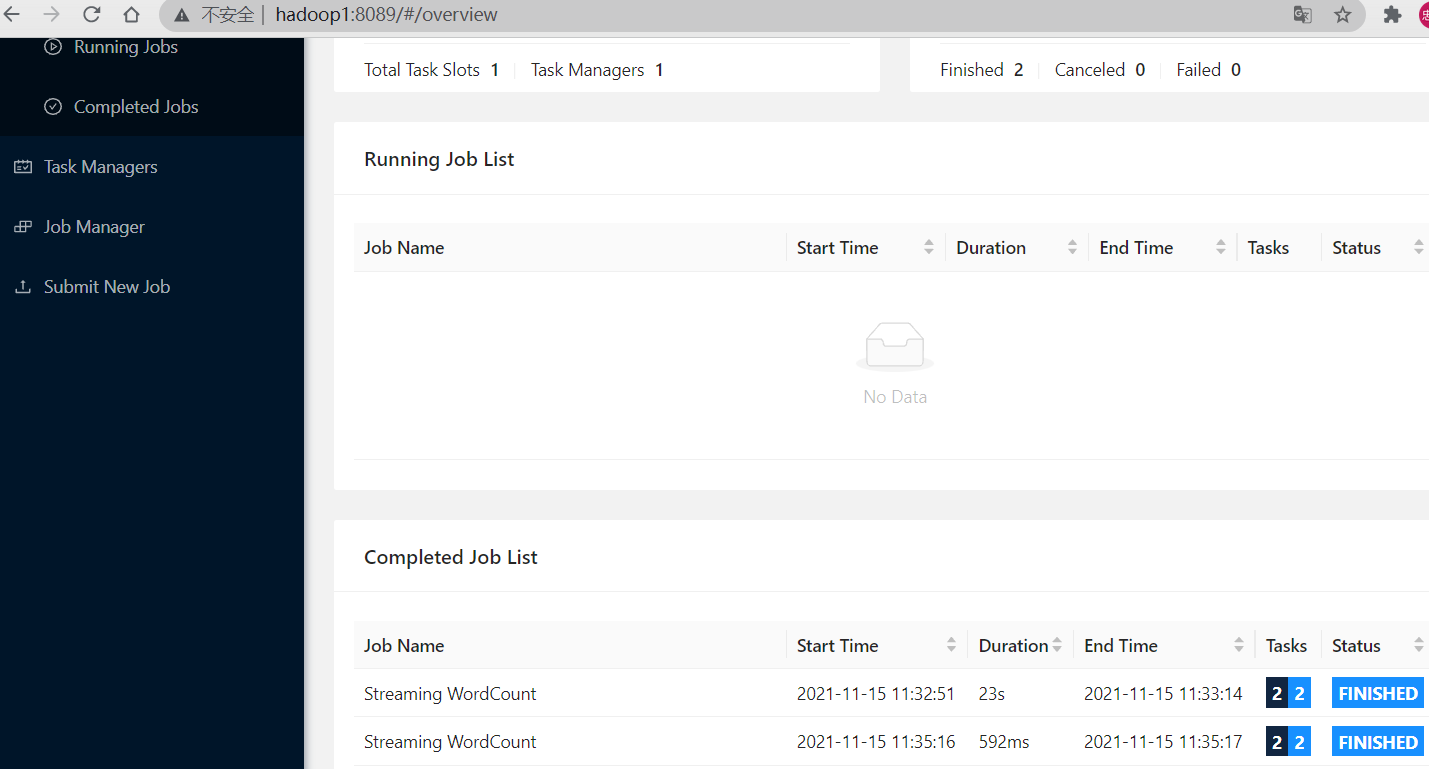
查看运行日志
1 | [hadoop@hadoop1 ~/flink-1.14.0]$ tail log/flink-hadoop-taskexecutor-0-hadoop1.out |
二、Flink Standalone 集群
服务规划
| 主机名 | Flink角色 | 其它依赖 |
|---|---|---|
| hadoop1 | jobManager(Master) | JDK1.8 |
| hadoop2 | taskManager(Worker) | JDK1.8 |
| hadoop3 | taskManager(Worker) | JDK1.8 |
2.1 准备工作
服务器免密登录
1 | [dev@hadoop1 ~]# su - hadoop |
配置jdk 1.8环境
1 | [hadoop@hadoop1 ~]$ tar xf downloads/jdk-8u301-linux-x64.tar.gz |
2.2 修改 flink 配置
1 | 下载flink |
修改 flink-conf.yaml 配置文件
1 | [hadoop@hadoop1 ~/flink-1.14.0]$ grep -Ev "^$|#" conf/flink-conf.yaml |
修改 masters 配置文件
1 | [hadoop@hadoop1 ~/flink-1.14.0]$ vim conf/masters |
修改 workers 配置文件
1 | [hadoop@hadoop1 ~/flink-1.14.0]$ vim conf/workers |
2.3 分发 flink 配置
1 | [hadoop@hadoop1 ~]$ rsync -av flink-1.14.0 hadoop@hadoop2:~/ |
2.4 启动 flink 集群
1 | [hadoop@hadoop1 ~/flink-1.14.0]$ ./bin/start-cluster.sh |
默认端口8081,端口冲突可以修改 conf/flink-conf.yaml 配置项 rest.port: 进行修改
访问web页面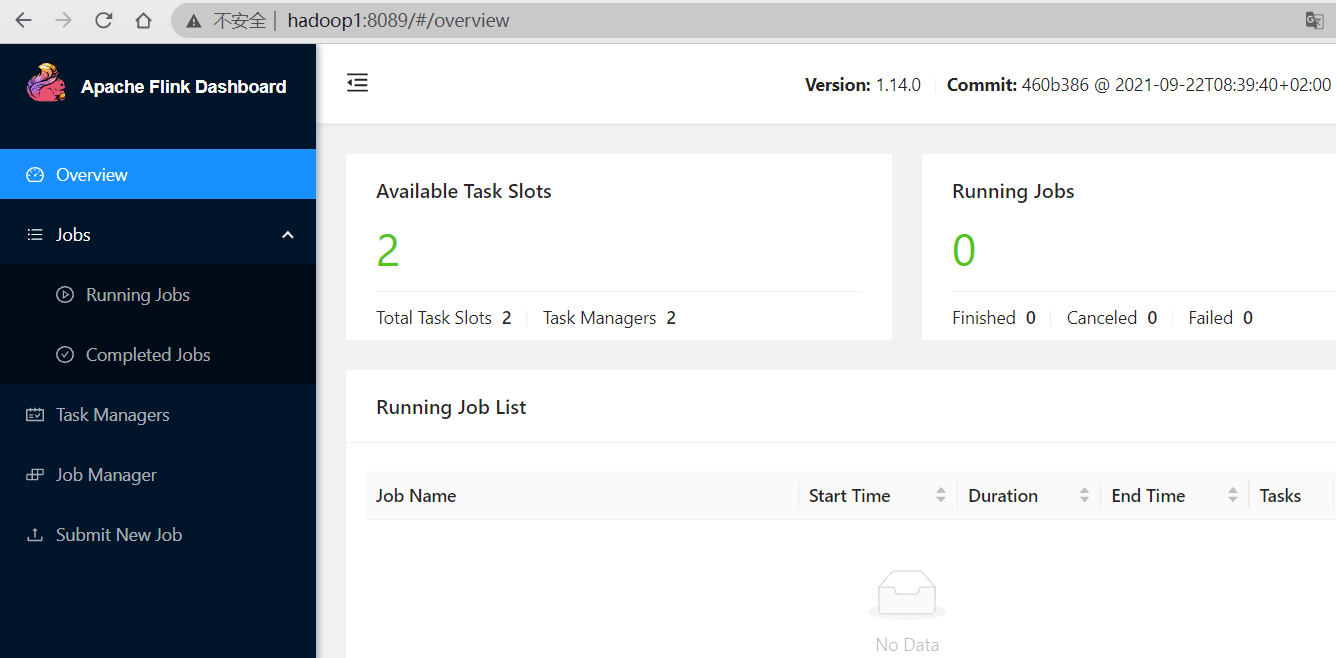
2.5 提交示例作业
1 | [hadoop@hadoop1 ~/flink-1.14.0]$ ./bin/flink run examples/streaming/WindowJoin.jar |
在web查看任务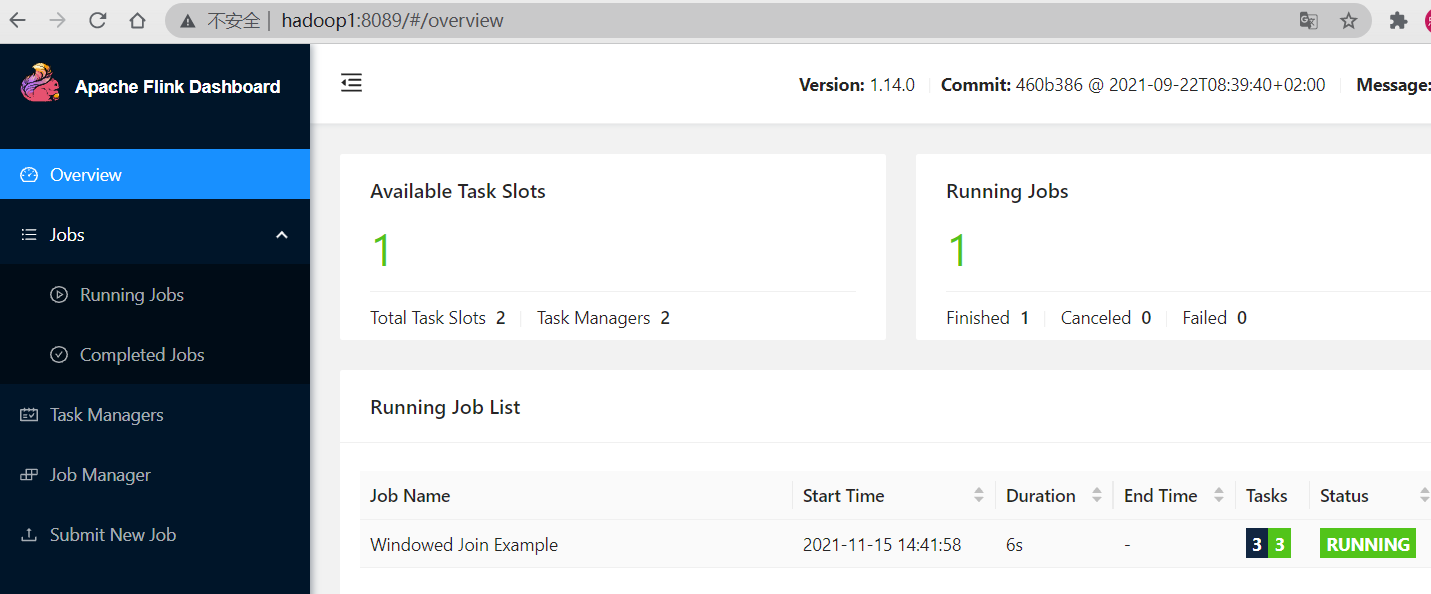
三、Flink Standalone 高可用
服务规划
| 主机名 | Flink角色 | 其它依赖 |
|---|---|---|
| hadoop1 | jobManager | JDK1.8、zookeeper |
| hadoop2 | jobManager、taskManager | JDK1.8、zookeeper |
| hadoop3 | taskManager | JDK1.8、zookeeper |
前置条件
Flink Standalone、zookeeper集群是可用的
3.1 修改 flink 配置
修改 flink-conf.yaml 配置文件,增加以下配置
1 | [hadoop@hadoop1 ~/flink-1.14.0]$ vim conf/flink-conf.yaml |
修改 masters 配置文件
1 | [hadoop@hadoop1 ~/flink-1.14.0]$ vim conf/masters |
3.2 下载 Hadoop 附加组件
在Flink1.8版本后,Flink官方提供的安装包里没有整合HDFS的jar,需要额外下载jar包并放在Flink的lib目录下,使Flink能够支持对Hadoop的操作
前往官网 https://flink.apache.org/downloads.html ,找到 Additional Components 选项,下载相应Hadoop版本的包
1 | [hadoop@hadoop1 ~/flink-1.14.0]$ wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/2.7.5-10.0/flink-shaded-hadoop-2-uber-2.7.5-10.0.jar |
或者添加 HADOOP_CLASSPATH 环境变量,也是可以的
1 | [hadoop@hadoop1 ~]$ vim .bash_profile |
3.3 颁发 flink 配置
1 | [hadoop@hadoop1 ~]$ rsync -av flink-1.14.0 hadoop@hadoop2:~/ |
除此之外,需要将master2上 flink-conf.yaml 配置中的监听地址修改为master2所在机器
1 | [hadoop@hadoop2 ~/flink-1.14.0]$ vim conf/flink-conf.yaml |
3.4 启动 flink 集群
1 | [hadoop@hadoop1 ~/flink-1.14.0]$ ./bin/start-cluster.sh |
3.5 验证高可用
通过 zookeeper 查看当前集群的master是那台节点
1 | [hadoop@hadoop1 ~/zookeeper-3.4.8]$ ./bin/zkCli.sh |
关闭当前的master进程
1 | [hadoop@hadoop1 ~/flink-1.14.0]$ jps |grep StandaloneSessionClusterEntrypoint |
提交示例作业
1 | [hadoop@hadoop2 ~/flink-1.14.0]$ ./bin/flink run examples/streaming/WordCount.jar |
在另一台master web查看作业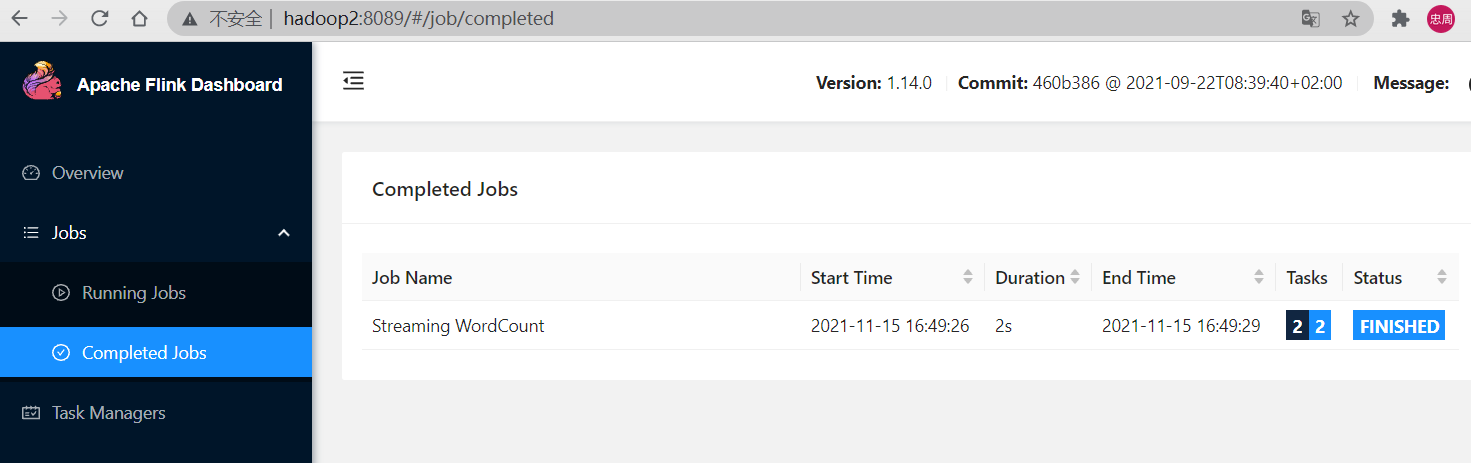
四、Flink On Yarn 模式
在YARN上使用Flink有3种模式:Per-Job模式、Session模式和Application模式。
前置条件
Hadoop,Yarn集群是可用的
配置好 HADOOP_HOME 环境变量
4.1 Session 模式
启动flink集群
1 | [hadoop@hadoop1 ~/flink-1.14.0]$ ./bin/yarn-session.sh -n 3 -s 3 -nm yarn-session1 |
yarn-session.sh 参数说明
-n,–container <arg>: 表示分配容器的数量(也就是 TaskManager 的数量)。
-D <arg>: 动态属性。
-d,–detached: 在后台独立运行。
-jm,–jobManagerMemory <arg>:设置 JobManager 的内存,单位是 MB。
-nm,–name:在 YARN 上为一个自定义的应用设置一个名字。
-q,–query:显示 YARN 中可用的资源(内存、cpu 核数)。
-qu,–queue <arg>:指定 YARN 队列。
-s,–slots <arg>:每个 TaskManager 使用的 Slot 数量。
-tm,–taskManagerMemory <arg>:每个 TaskManager 的内存,单位是 MB。
-z,–zookeeperNamespace <arg>:针对 HA 模式在 ZooKeeper 上创建 NameSpace。
-id,–applicationId <yarnAppId>:指定 YARN 集群上的任务 ID,附着到一个后台独立运行的 yarn session 中
查看yarn UI界面,可以看到提交的application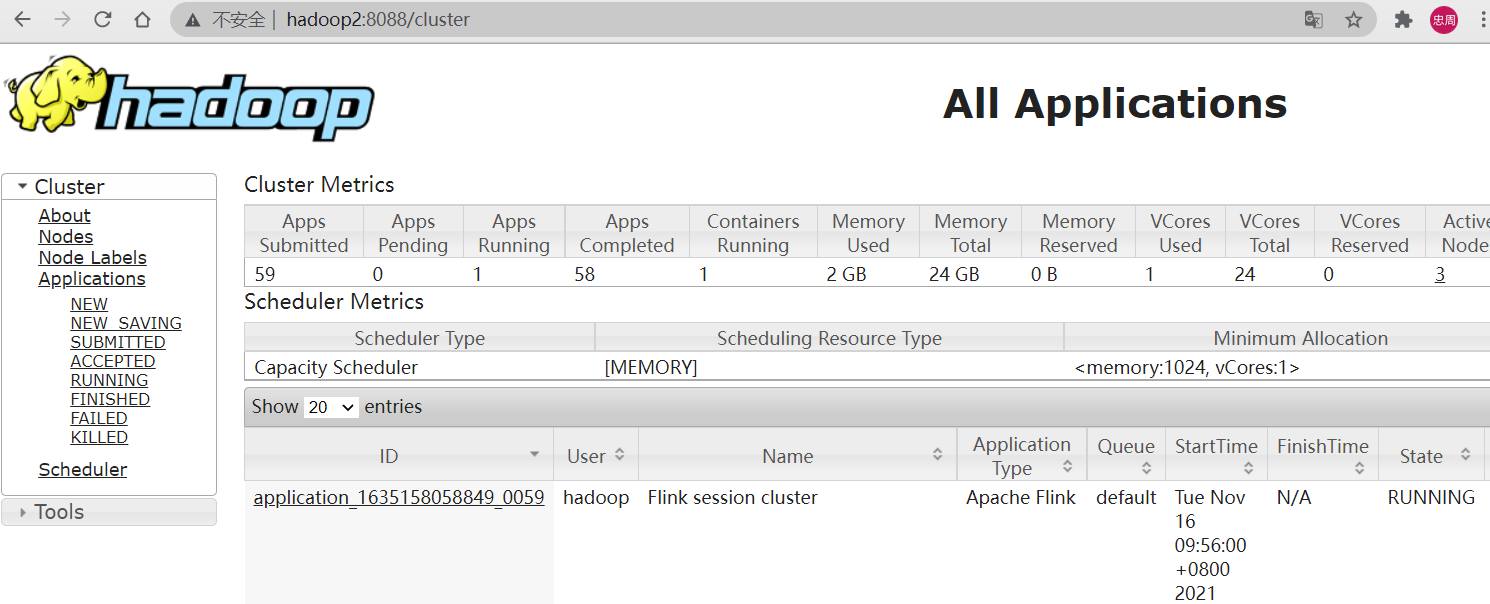
使用flink run提交示例作业
1 | [hadoop@hadoop1 ~/flink-1.14.0]$ ./bin/flink run -t yarn-session \ |
之后可以通过yarn找到相应的 application 中的 ApplicationMaster 进入flink管理页面查看任务运行情况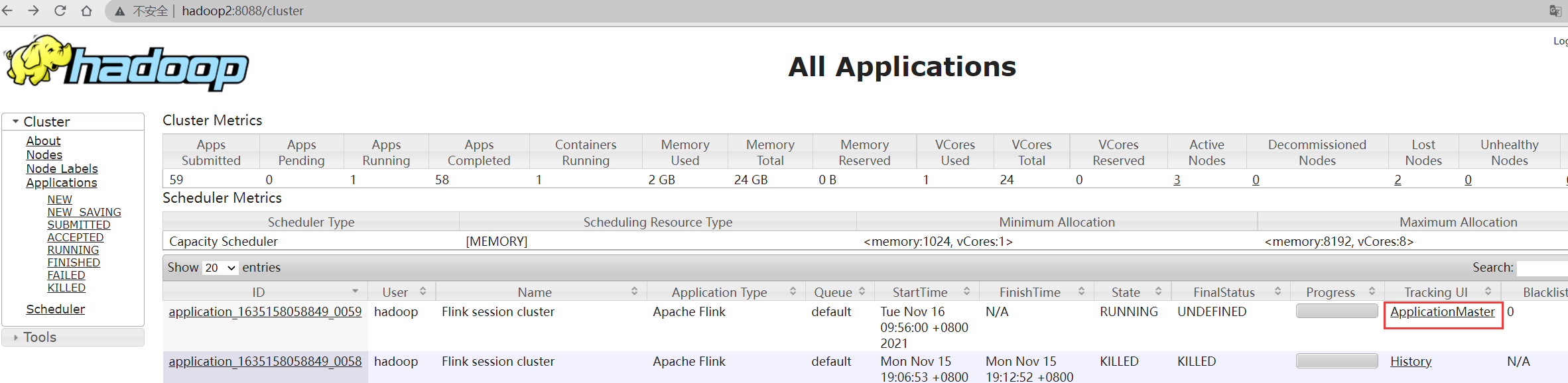
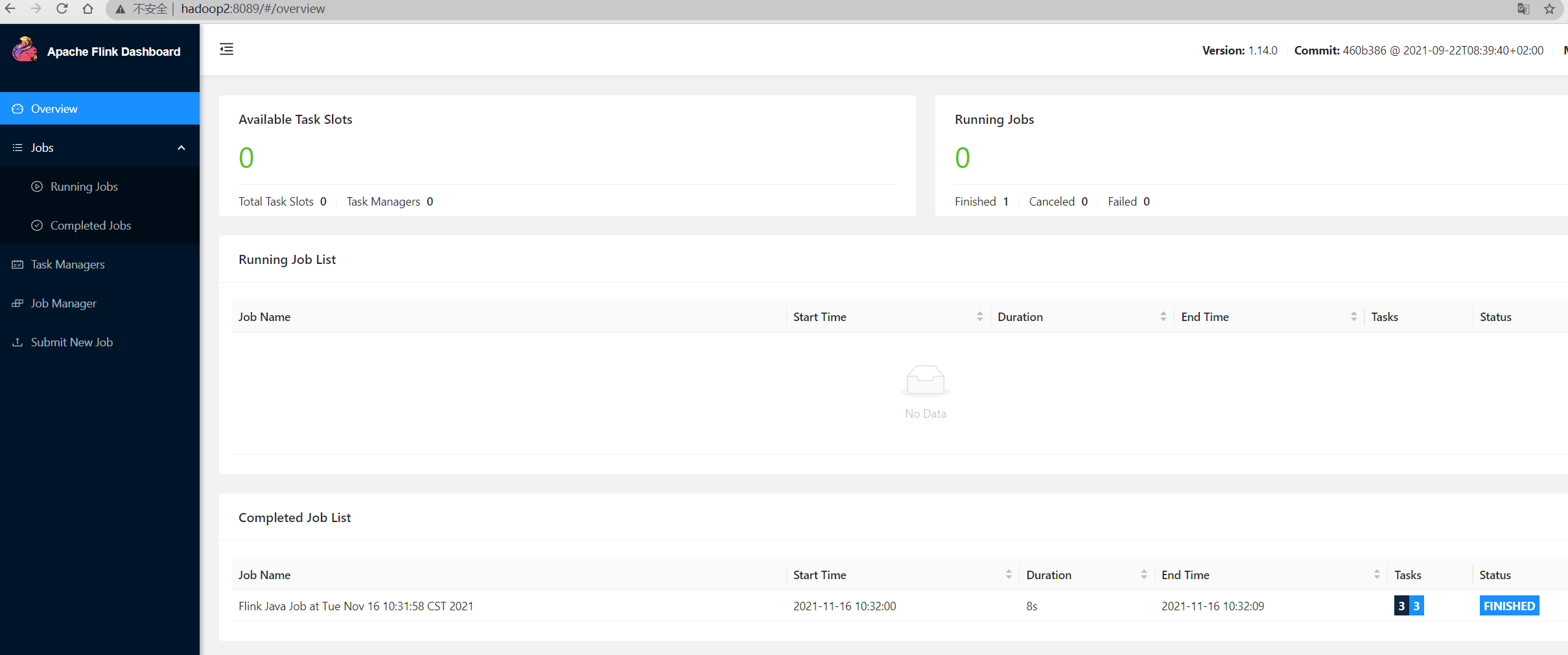
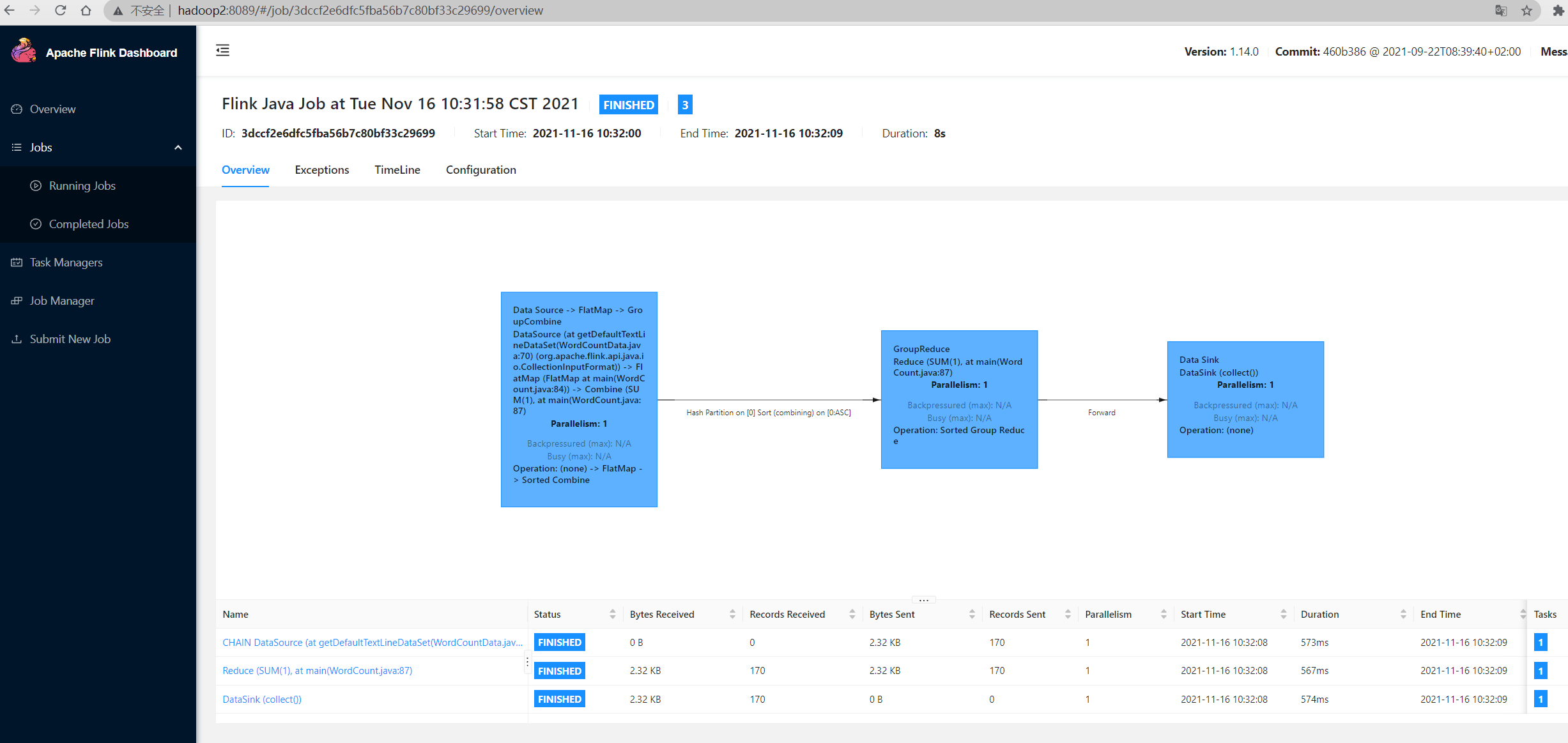
关闭yarn-session
1 | [hadoop@hadoop1 ~/flink-1.14.0]$ yarn application -kill application_1635158058849_0059 |
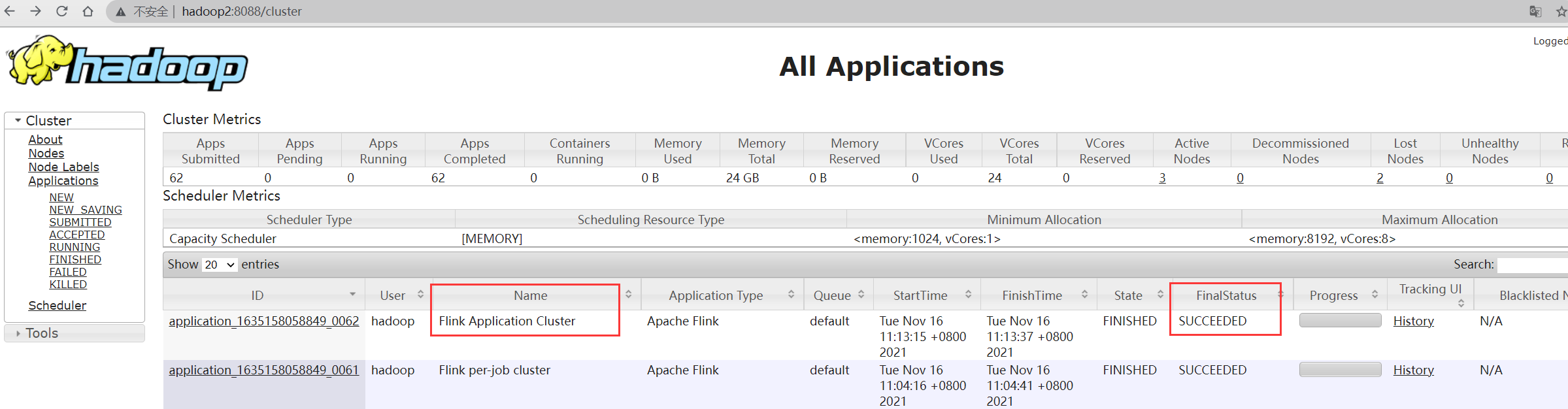
查看yarn UI中的application状态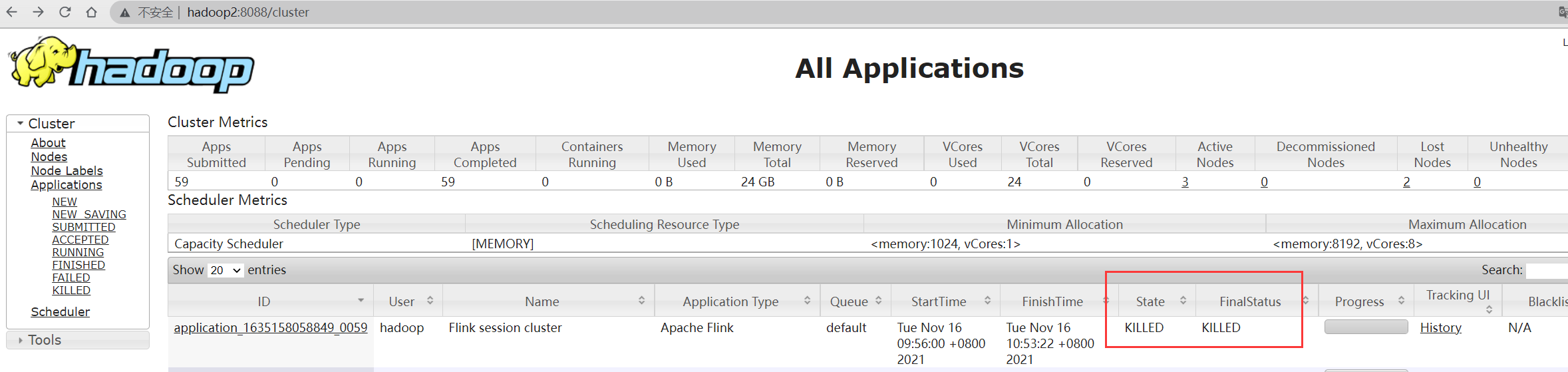
session模式将在 /tmp/.yarn-properties-<username> 中创建一个隐藏文件,在提交作业时,命令行界面将拾取该文件进行集群发现。
4.2 Per-Job模式
直接提交作业
1 | [hadoop@hadoop1 ~/flink-1.14.0]$ ./bin/flink run -t yarn-per-job \ |
在yarn UI中查看application执行状态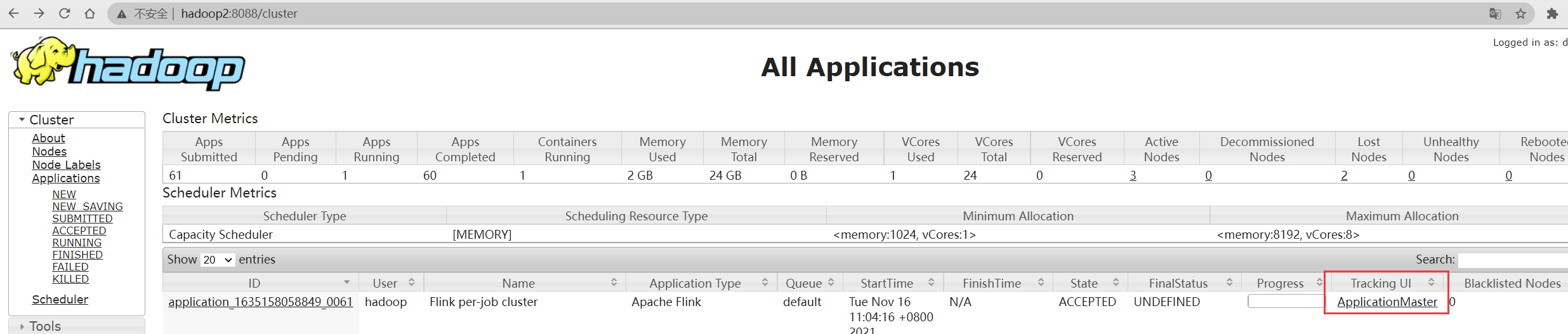
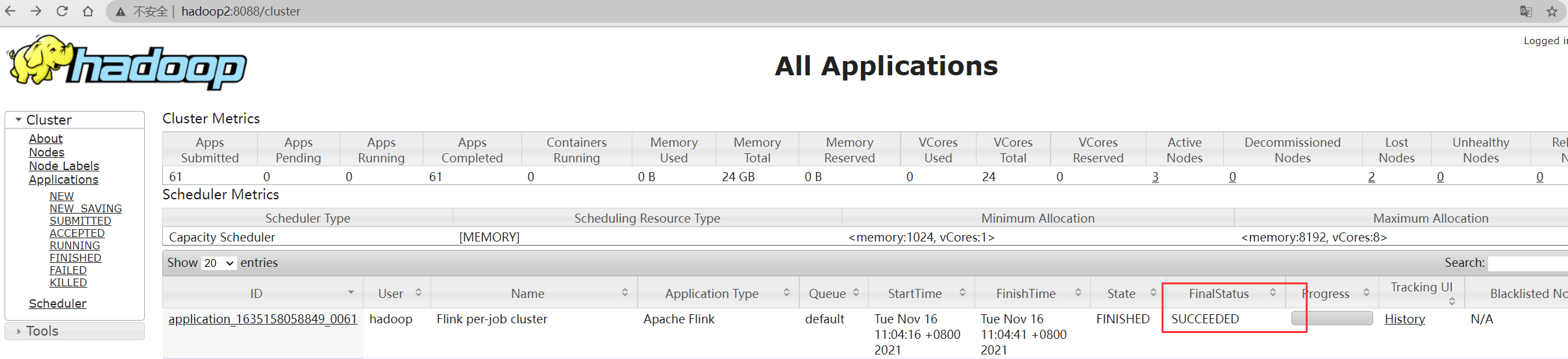
4.3 Application 模式
直接提交作业
1 | [hadoop@hadoop2 ~/flink-1.14.0]$ ./bin/flink run-application -t yarn-application \ |
在yarn UI中查看application执行状态