一、有限数据集和无限数据集
有限数据集:数据大小有限(固定大小,比如固定的文件),用于批处理,这一类数据主要用于mr,hive,pig,spark等批计算引擎。
无限数据集:数据持续增长(属于无限大小,比如kafka中的日志数据,总是有新数据进入,并且不知道什么时候结束或者是永远不结束),用于流式处理,这一类数据主要用于storm,spark streaming,flink等一些流式计算引擎。
二、apache计算引擎的发展关系
在apche中的三篇论文鉴定大数据的基础其中mr收到其中一篇论文的启发创造了mapreduce,同时随着时代的发展也出现了其他的技术技术。
2.1 第一代计算引擎 mapreduce
mapreduce 作为第一个计算引擎,用于批处理,是计算引擎的先驱,内部支持机器学习但是现在机器学习库不在更新,并且mapreduce 编写十分的耗时,开发效率低,开发时间成本太大,所以很少有企业写mapreduce 来跑程序。
2.2 第二代计算引擎 pig/hive
- 作为第二代引擎pig/hive 对hadoop(如果不知道hadoop的话,建议不要看了。。。。。)进行了嵌套,其存储基于hdfs,计算基于mr,hive/pig在处理任务时首先会把本身的代码解析为一个个m/r任务,这样就大大的降低了mr的编写编写成本;
- pig 有自己的脚本语言属于,比hive更加的灵活;
- hive 属于类sql语法,虽然没有pig灵活,但是对于现在程序员都会sql的世界来说大家更喜欢使用hive;
- pig/hive 只支持批处理,且支持机器学习 (hivemall)。
2.3 第三代计算引擎 spark/storm
随着时代的发展,企业对数据实时处理的需求愈来愈大,所以就出现了storm/spark
- 这两者有着自己的计算模式;
- storm属于真正的流式处理,低延迟(ms级延迟),高吞吐,且每条数据都会触发计算;
- spark属于批处理转化为流处理即将流式数据根据时间切分成小批次进行计算,对比与storm而言延迟会高于0.5s(s级延迟),但是性能上的消耗低于storm。
流式计算是批次计算的特例(流式计算是拆分计算的结果)。
2.4 第四代计算引擎 flink
- flink2015年出现在apache,后来又被阿里巴巴技术团队进行优化(这里我身为国人为之自豪)为blink,flink支持流式计算也支持的批次处理;
- flink为流式计算而生属于每一条数据触发计算,在性能的消耗低于storm,吞吐量高于storm,延时低于storm,并且比storm更加易于编写。因为storm如果要实现窗口需要自己编写逻辑,但是flink中有窗口方法;
- flink内部支持多种函数,其中包括窗口函数和各种算子(这一点和spark很像,但是在性能和实时上spark是没有办法比较的);
- flink支持仅一次语义保证数据不丢失;
- flink支持通过envent time来控制窗口时间,支持乱序时间和时间处理(这点我觉得很厉害);
- 对于批次处理flink的批处理可以理解为 “批次处理是流式处理的特例”(批次计算是流式计算的合并结果)。
三、三种流式计算基本原理
3.1 Apache Storm
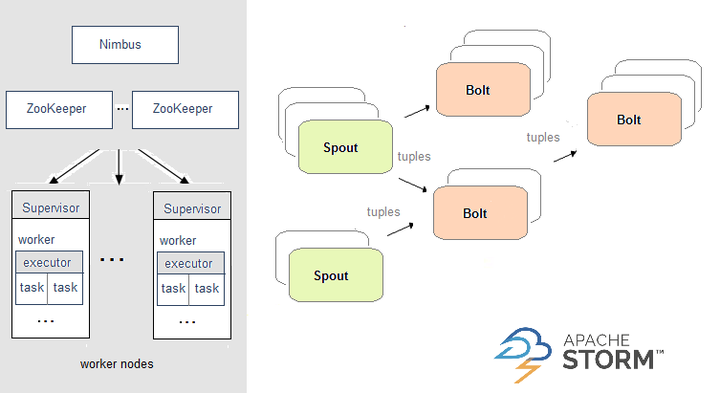
在Storm中,需要先设计一个实时计算结构,我们称之为拓扑(topology)。之后,这个拓扑结构会被提交给集群,其中主节点(master node)负责给工作节点(worker node)分配代码,工作节点负责执行代码。在一个拓扑结构中,包含spout和bolt两种角色。数据在spouts之间传递,这些spouts将数据流以tuple元组的形式发送;而bolt则负责转换数据流。
3.2 Apache Spark
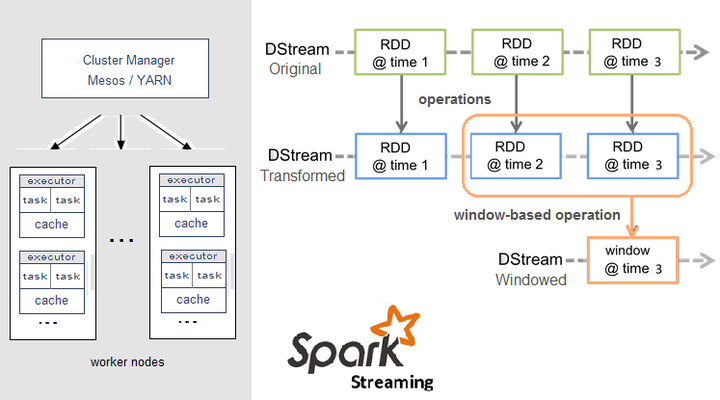
Spark Streaming,即核心Spark API的扩展,不像Storm那样一次处理一个数据流。相反,它在处理数据流之前,会按照时间间隔对数据流进行分段切分。Spark针对连续数据流的抽象,我们称为DStream(Discretized Stream)。 DStream是小批处理的RDD(弹性分布式数据集), RDD则是分布式数据集,可以通过任意函数和滑动数据窗口(窗口计算)进行转换,实现并行操作。
3.3 Apache Flink
针对流数据+批数据的计算框架。把批数据看作流数据的一种特例,延迟性较低(毫秒级),且能够保证消息传输不丢失不重复。
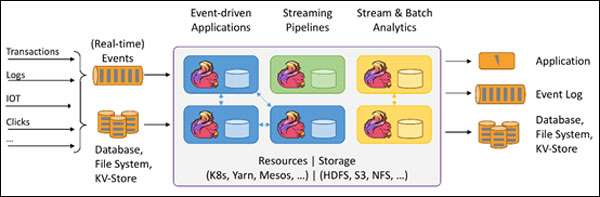
Flink创造性地统一了流处理和批处理,作为流处理看待时输入数据流是无界的,而批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。Flink程序由Stream和Transformation这两个基本构建块组成,其中Stream是一个中间结果数据,而Transformation是一个操作,它对一个或多个输入Stream进行计算处理,输出一个或多个结果Stream。
四、区别对比
| 对比项 | Flink | Storm | Spark Streaming |
|---|---|---|---|
| 诞生时间 | 2014 年 12月 | 2014 年 9 月 17 日 | 2010 |
| 社区及生态 | 被阿里收购后,有了官方中文社区、很多资料也有中文版、在国内使用率最高 | 社区活跃,文档资料详细 | 社区活跃,文档资料详细 |
| 状态管理 | 基于操作的状态管理 | 无状态管理 | 基于 DStream的状态管理 |
| 消息投递保证次数 | 最多一次、至少一次、恰好一次 | 最多一次、至少一次 | 最多一次、至少一次、恰好一次 |
| 容错方式 | checkpoint机制:通过分布式一致性快照机制,对数据流和算子状态进行保存 | ACK 机制:对每个消息进行全链路跟踪,失败或超时进行重发 | RDD CheckPoint(基于 RDD 做 CheckPoint) |
| 吞吐量 | 高 | 低 | 高 |
| 延迟 | 低 | 低 | 中等 |
| 模型 | Native(数据进入立即处理) | Native(数据进入立即处理) | Micro-Batching |
| API语言 | scala、java、python、sql | scala、java、sql | scala、java、python、sql、R |
| 运行时 | 单个jvm进程可以有多个应用多个任务 | 单个jvm进程单个应用多个任务,每个线程多任务 | 单个jvm进程单个应用多个任务,每个线程单个任务 |
- 相比于storm ,spark和flink两个都支持窗口和算子,减少了不少的编程时间;
- flink相比于storm和spark,flink支持乱序和延迟时间(在实际场景中,这个功能很牛逼),个人觉得就这个功能就可以锤爆spark;
- 对于spark而言他的优势就是机器学习,如果我们的场景中对实时要求不高可以考虑spark,但是如果是要求很高就考虑使用flink,比如对用户异常消费进行监控,如果这个场景使用spark的话那么等到系统发现开始预警的时候(0.5s),罪犯已经完成了交易,可想而知在某些场景下flink的实时有多重要。