一、简介
Apache Storm 是开源的分布式、高容错的实时计算系统,擅长处理海量数据,适用于数据实时处理而非批处理。经常用于在实时分析、在线机器学习、持续计算、分布式远程调用和ETL等领域。
二、Apache Storm核心概念
- Stream:Storm中被处理的数据流,一条消息称为一个Tuple。
- Spout:Storm连接外部数据源的组件,可以认为Storm的数据源。
- Bolt:数据处理组件,Bolt里面封装了处理数据的逻辑。Spout和Bolt是Storm中的两类组件,类似MapReduce中的Map和Reduce。比如可以在Bolt上定义过滤、聚合、join、写数据库等。
- Nimbus:Storm集群主节点,负责资源分配和任务调度。我们提交任务和截止任务都是在Nimbus上操作的。一个Storm集群只有一个Nimbus节点。
- Executor:执行Spout或Bolt任务的线程,由Worker进程创建。每个Executor线程只会执行一个Topology中的1个Component的task实例(但不一定只执行一个task,可能执行多个task)。
- Task:Storm中最小的处理单元,一个Executor中可以运行一个或多个Task。Topology中的Spout和Bolt可以设置并行度,一个并行度对应一个Task。
- Topology:由消息分组将Spout和Bolt连接起来的任务拓扑。相当于MapReduce中Map和Reduce组成的任务。
- Supervisor:Storm集群工作节点,接受Nimbus分配任务,管理所有Worker。
- Worker:工作进程,运行在Supervisor节点上,一个supervisor可以运行多个worker进程(默认4个),一个Woker进程可以包含一个或多个Executor线程,一个executor线程可以运行一个或多个task线程。Spout和Bolt都运行在task之上。一个topology可以运行在集群中一台或者多台机器上、一个或多个worker进程上。
- Stream grouping:消息分发策略,定义了Bolt组件以何种方式接受数据。Storm内置了八种消息分组策略,我们也可以通过实现CustomStreamGrouping定义自己的消息分组策略。
- Reliability:可靠性,Storm保证每个Tuple都会被处理。
- Tuple:在storm中,一条数据可以理解为是一个Tuple。
2.1 Storm Grouping 策略
- Shuffle grouping:随机分配消息给Bolt task,能够保证每个Bolt task都能分配到相同数据量的元组。
- Fileds grouping:根据字段进行划分,比如按“user-id”字段进行划分,那么相同“user-id”的值会被分配到一个Bolt task中。
- Partial grouping:类似Filed grouping,但是能够保证下游Bolt任务负载均衡。
- All grouping:将每条消息都广播给所有Bolt任务,也就是说每个Bolt处理的数据完全相同。需要小心使用。
- Global grouping:所有消息流数据全部发送到一个Bolt任务中。
- None grouping:不关心分组策略,相当于Shuffle grouping。
- Direct grouping:直接分组,上游指定那个Bolt任务接受数据。
- Local or shuffle grouping:资源本地化的一种实现方式,如果任务都在同一个进程中,则会发送到该Bolt任务中。如果没有,相当于shuffle grouping。
三、Storm 架构原理
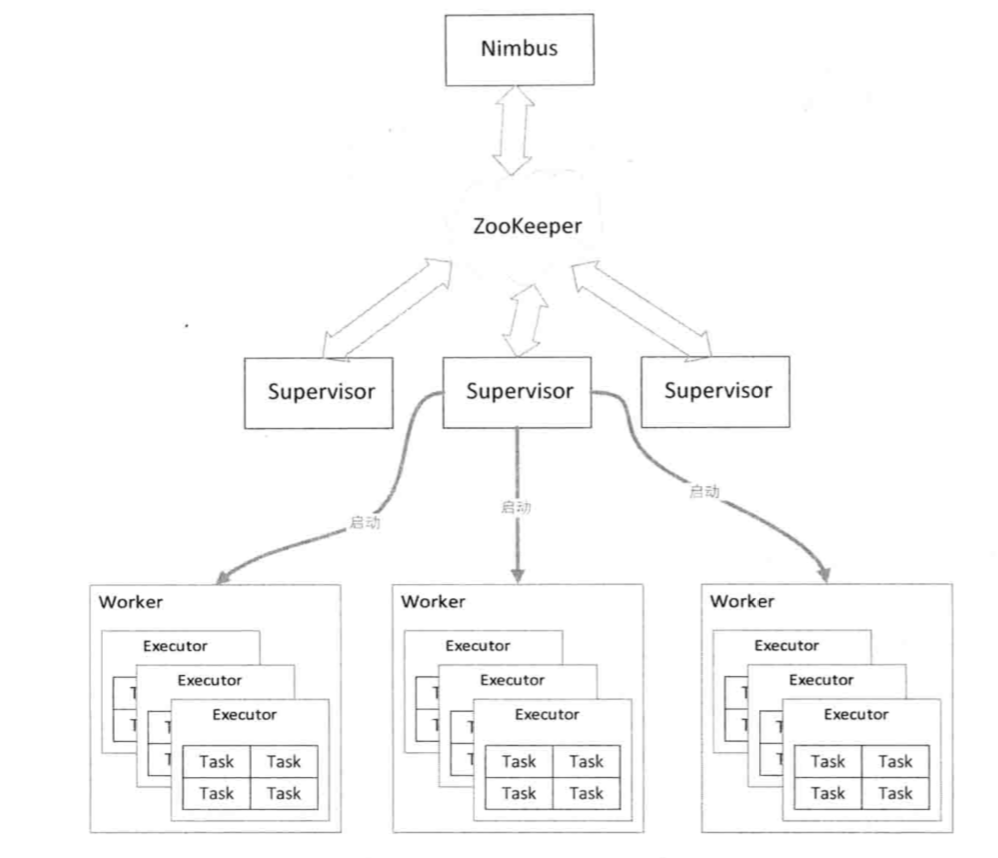
Storm集群有两类节点:运行Nimbus守护进程的主节点和运行Supervisor守护进程的工作节点。Nimbus节点用于分配代码、分配计算任务(分配给哪些Supervisor上的哪些Woker)和监控状态(用于故障检测、恢复)。Supervisor节点负责监听工作(监听Nimbus分配的任务)、启动并停止Woker进程。
Worker是运行在Supervisor上的进程,Supervisor收到Nimbus分配的任务后,负责启动Nimbus指定的Woker进程。Woker进程执行Topology的子集,一个Topology任务可能由运行在多台机器上的Worker进程组成。
Woker进程启动一个或多个Executor线程,Executor线程中可以有一个或多个Task。每个Executor都会启动一个消息循环线程,用于接受、处理和发送消息。
Nimbus和Supervisor之间协调工作也是由Zookeeper来完成的。
Zookeeper集群负责Nimbus节点和Supervior节点之间的通信,监控各个节点之间的状态。比如通常我们提交任务的时候是在Nimbus节点上执行的,Nimbus节点通过zk集群将任务分发下去,而Supervisor是真正执行任务的地方。Nimbus节点通过zk集群监控各个Supervisor节点的状态,当某个Supervisor节点出现故障的时候,Nimbus节点就会通过zk集群将那个Supervisor节点上的任务重新分发,在其他Supervisor节点上执行。这就意味着Storm集群也是高可用集群,如果Nimbus节点出现故障的时候,整个任务并不会停止,但是任务的管理会出现影响,通常这种情况下我们只需要将Nimbus节点恢复就可以了。Nimbus节点不支持高可用,这也是Storm目前面临的问题之一。不过一般情况下,Nimbus节点的压力不大,通常不会出现问题。
一般情况下,Zookeeper集群的压力并不大,一般只需要部署3台就够了。Zookeeper集群在Storm集群中逻辑上是独立的,但在实际部署的时候,一般会将zk节点部署在Nimbus节点或Supervisor节点上。
Nimbus和Supervisor都能快速失败恢复,而且它们都是无状态的,状态信息存储在Zookeeper(元数据)中和本地中。当Nimbus或Supervisor挂掉后,可以重新启动并读取状态信息到集群中来正常运行,所以Storm系统具有很高的容错性。
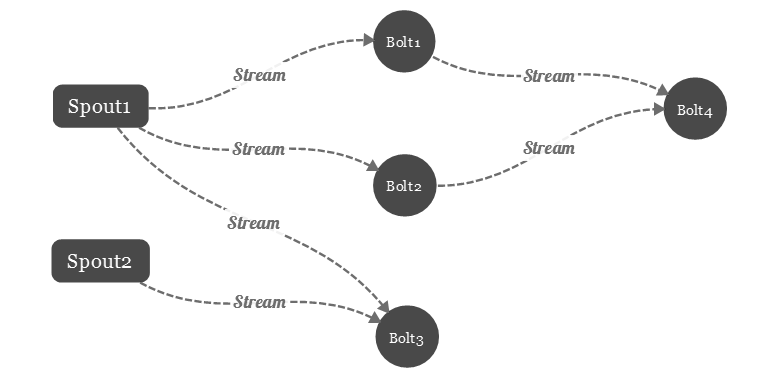
在逻辑上将Storm中消息来源节点称为Spout,消息处理节点称为Bolt,它们通过流分组组成Topology。
3.1 Storm 中的数据流
在Storm中,Spout组件主要用来从数据源拉取数据,形成一个Tuple后转交给Bolt处理。Bolt接受到Tuple处理完后,可以选择继续交给下一个Bolt处理,也可以选择不往下传。这样数据以Tuple的形式一个接一个的往下执行,就形成了一个拓扑数据流。
3.2 Storm 的元数据
Storm在ZooKeeper中存储数据的目录,这是一个根路径为/storm的树,树中的每一个节点代表ZooKeeper中的一个节点(znode),每一个叶子节点是Storm真正存储数据的地方。从根节点到叶子节点的全路径代表了该数据在ZooKeeper中的存储路径,该路径可被用来写入或获取数据。
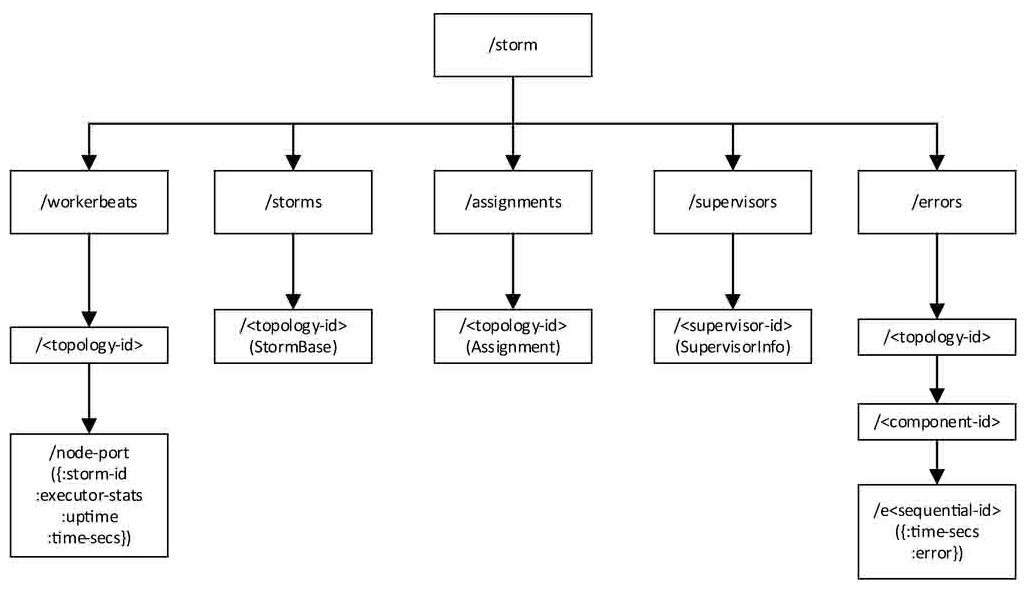
- /storm/workerbeats/<topology-id>/node-port:它存储由node和port指定的Worker的运行状态和一些统计信息,主要包括storm-id(也即topology-id)、当前Worker上所有Executor的统计信息(如发送的消息数目、接收的消息数目等)、当前Worker的启动时间以及最后一次更新这些信息的时间。在一个topology-id下面,可能有多个node-port节点。它的内容在运行过程中会被更新。
- /storm/storms/<topology-id>:它存储Topology本身的信息,包括它的名字、启动时间、运行状态、要使用的Worker数目以及每个组件的并行度设置。它的内容在运行过程中是不变的。
- /storm/assignments/<topology-id>:它存储了Nimbus为每个Topology分配的任务信息,包括该Topology在Nimbus机器本地的存储目录、被分配到的Supervisor机器到主机名的映射关系、每个Executor运行在哪个Worker上以及每个Executor的启动时间。该节点的数据在运行过程中会被更新。
- /storm/supervisors/<supervisor-id>:它存储Supervisor机器本身的运行统计信息,主要包括最近一次更新时间、主机名、supervisor-id、已经使用的端口列表、所有的端口列表以及运行时间。该节点的数据在运行过程中也会被更新。
- /storm/errors/<topology-id>/<component-id>/e<sequential-id>:它存储运行过程中每个组件上发生的错误信息。<sequential-id>是一个递增的序列号,每一个组件最多只会保留最近的10条错误信息。它的内容在运行过程中是不变的(但是有可能被删除)。
3.3 Storm 怎么使用这些元数据
了解了存储在ZooKeeper中的数据,我们自然想知道Storm是如何使用这些元数据的。例如,这些数据何时被写入、更新或删除,这些数据都是由哪种类型的节点(Nimbus、Supervisor、Worker或者Executor)来维护的。
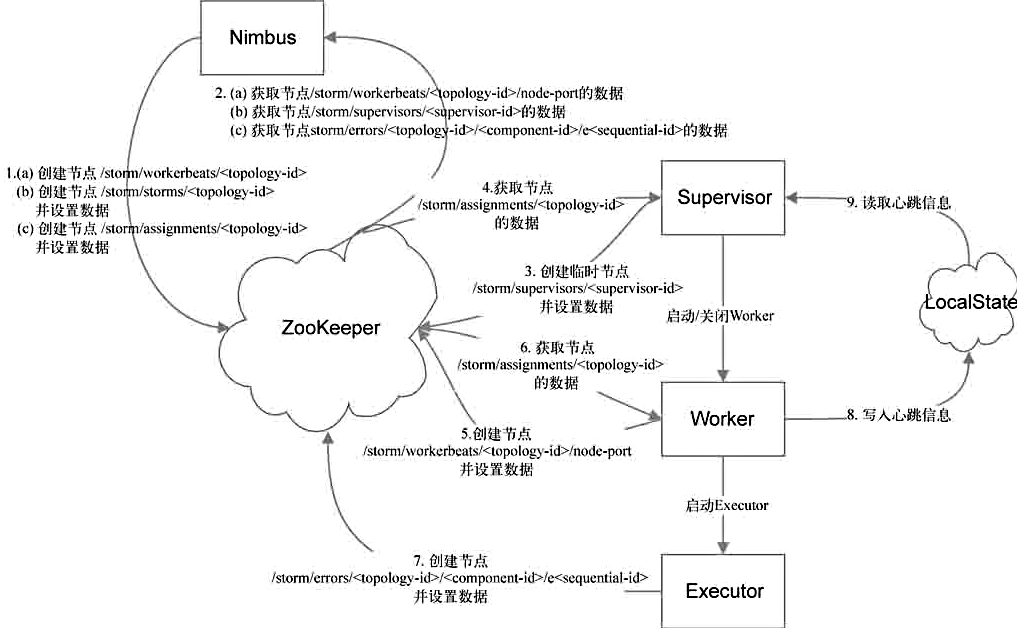
Nimbus
Nimbus既需要在ZooKeeper中创建元数据,也需要从ZooKeeper中获取元数据。图中箭头1和箭头2的作用。
- 箭头1表示由Nimbus创建的路径,包括:
a./storm/workerbeats/<topology-id>
b./storm/storms/<topology-id>
c./storm/assignments/<topology-id>
其中对于路径a,Nimbus只会创建路径,不会设置数据(数据是由Worker设置的,后面会介绍);对于路径b和c,Nimbus在创建它们的时候就会设置数据。a和b只有在提交新Topology的时候才会创建,且b中的数据设置好后就不再变化,c则在第一次为该Topology进行任务分配的时候创建,若任务分配计划有变,Nimbus就会更新它的内容。 - 箭头2表示Nimbus需要获取数据的路径,包括:
a./storm/workerbeats/<topology-id>/node-port
b./storm/supervisors/<supervisor-id>
c./storm/errors/<topology-id>/<component-id>/e<sequential-id>
Nimbus需要从路径a读取当前已被分配的Worker的运行状态。根据该信息,Nimbus可以得知哪些Worker状态正常,哪些需要被重新调度,同时还会获取到该Worker所有Executor统计信息,这些信息会通过UI呈现给用户。从路径b可以获取当前集群中所有Supervisor的状态,通过这些信息可以得知哪些Supervisor上还有空闲的资源可用,哪些Supervisor则已经不再活跃,需要将分配到它的任务分配到其他节点上。从路径c上可以获取当前所有的错误信息并通过UI呈现给用户。集群中可以动态增减机器,机器的增减会引起ZooKeeper中元数据的变化,Nimbus通过不断获取这些元数据信息来调整任务分配,故Storm具有良好的可扩展性。当Nimbus死掉时,其他节点是可以继续工作的,但是不能提交新的Topology,也不能重新进行任务分配和负载调整,因此目前Nimbus还是存在单点的问题。
Supervisor
同Nimbus类似,Superviser也要通过ZooKeeper来创建和获取元数据。除此之外,Supervisor还通过监控指定的本地文件来检测由它启动的所有Worker的运行状态。图中箭头3、箭头4和箭头9的作用。
- 箭头3表示Supervisor在ZooKeeper中创建的路径是
/storm/supervisors/<supervisor-id>。新节点加入时,会在该路径下创建一个节点。值得注意的是,该节点是一个临时节点(创建ZooKeeper节点的一种模式),即只要Supervisor与ZooKeeper的连接稳定存在,该节点就一直存在;一旦连接断开,该节点则会被自动删除。该目录下的节点列表代表了目前活跃的机器。这保证了Nimbus能及时得知当前集群中机器的状态,这是Nimbus可以进行任务分配的基础,也是Storm具有容错性以及可扩展性的基础。 - 箭头4表示Supervisor需要获取数据的路径是
/storm/assignments/<topology-id>。我们知道它是Nimbus写入的对Topology的任务分配信息,Supervisor从该路径可以获取到Nimbus分配给它的所有任务。Supervisor在本地保存上次的分配信息,对比这两部分信息可以得知分配信息是否有变化。若发生变化,则需要关闭被移除任务所对应的Worker,并启动新的Worker执行新分配的任务。Nimbus会尽量保持任务分配的稳定性。 - 箭头9表示Supervisor会从LocalState中获取由它启动的所有Worker的心跳信息。Supervisor会每隔一段时间检查一次这些心跳信息,如果发现某个Worker在这段时间内没有更新心跳信息,表明该Worker当前的运行状态出了问题。这时Supervisor就会杀掉这个Worker,原本分配给这个Worker的任务也会被Nimbus重新分配。
Worker
Worker也需要利用ZooKeeper来创建和获取元数据,同时它还需要利用本地的文件来记录自己的心跳信息。图中箭头5、箭头6和箭头8的作用。
- 箭头5表示Worker在ZooKeeper中创建的路径是
/storm/workerbeats/<topology-id>/node- port。在Worker启动时,将创建一个与其对应的节点,相当于对自身进行注册。需要注意的是,Nimbus在Topology被提交时只会创建路径/storm/workerbeats/<topology-id>,而不会设置数据,数据则留到Worker启动之后由Worker创建。这样安排的目的之一是为了避免多个Worker同时创建路径时所导致的冲突。 - 箭头6表示Worker需要获取数据的路径是
/storm/assignments/<topology-id>,Worker会从这些任务分配信息中取出分配给它的任务并执行。 - 箭头8表示Worker在LocalState中保存心跳信息。LocalState实际上将这些信息保存在本地文件中,Worker用这些信息跟Supervisor保持心跳,每隔几秒钟需要更新一次心跳信息。Worker与Supervisor属于不同的进程,因而Storm采用本地文件的方式来传递心跳。
Executor
Executor只会利用ZooKeeper来记录自己的运行错误信息,图中箭头7的作用。
箭头7表示Executor在ZooKeeper中创建的路径是/storm/errors/<topology-id>/<component-id>/e<sequential-id>。每个Executor会在运行过程中记录发生的错误。
从前面的描述中可以得知,Nimbus、Supervisor以及Worker两两之间都需要维持心跳信息,它们的心跳关系如下。
- Nimbus和Supervisor之间通过
/storm/supervisors/<supervisor-id>路径对应的数据进行心跳保持。Supervisor创建这个路径时采用的是临时节点模式,所以只要Supervisor死掉,对应路径的数据就会被删掉,Nimbus就会将原本分配给该Supervisor的任务重新分配。 - Worker跟Nimbus之间通过
/storm/workerbeats/<topology-id>/node-port中的数据进行心跳保持。Nimbus会每隔一定时间获取该路径下的数据,同时Nimbus还会在它的内存中保存上一次的信息。如果发现某个Worker的心跳信息有一段时间没更新,就认为该Worker已经死掉了,Nimbus会对任务进行重新分配,将分配至该Worker的任务分配给其他Worker。 - Worker跟Supervisor之间通过本地文件(基于LocalState)进行心跳保持。
四、Storm 集群部署
服务规则
| 主机名 | 运行storm服务 | 依赖环境 |
|---|---|---|
| hadoop1 | Nimbus、UI | JDK1.8、zookeeper |
| hadoop2 | surpervisor | JDK1.8、zookeeper |
| hadoop3 | surpervisor | JDK1.8、zookeeper |
4.1 配置 Storm
下载 storm
1 | [hadoop@hadoop1 downloads]$ wget https://downloads.apache.org/storm/apache-storm-2.2.1/apache-storm-2.2.1.tar.gz |
配置 storm.yaml
1 | [hadoop@hadoop1 ~]$ vim apache-storm-2.2.1/conf/storm.yaml |
更多配置可以查看 https://github.com/apache/storm/blob/v2.2.1/conf/defaults.yaml 。随着深入了解,可以优化集群配置。
配置storm环境变量
1 | [hadoop@hadoop1 ~]$ vim .bash_profile |
将拷贝配置到其它storm节点
1 | [hadoop@hadoop1 ~]$ rsync -av apache-storm-2.2.1 hadoop@hadoop2:~/ |
4.2 启动 Storm
启动 nimbus 节点和 storm ui
1 | [hadoop@hadoop1 ~]$ nohup storm nimbus >> apache-storm-2.2.1/nimbus.log & |
启动 Supervisor 节点
1 | [hadoop@hadoop2 ~]$ nohup storm supervisor >> apache-storm-2.2.1/supervisor.log & |
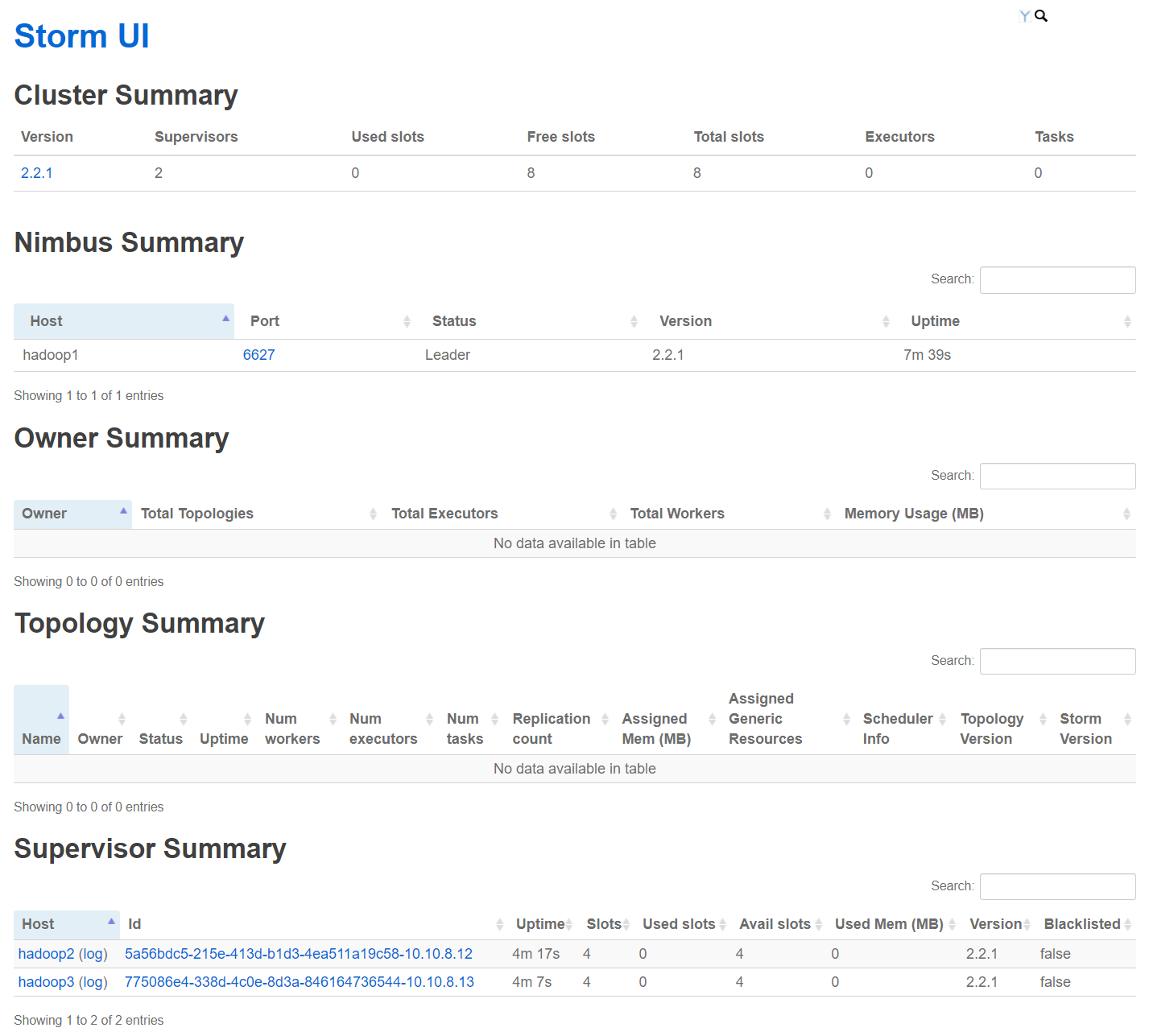
4.3 访问 Storm UI 页面
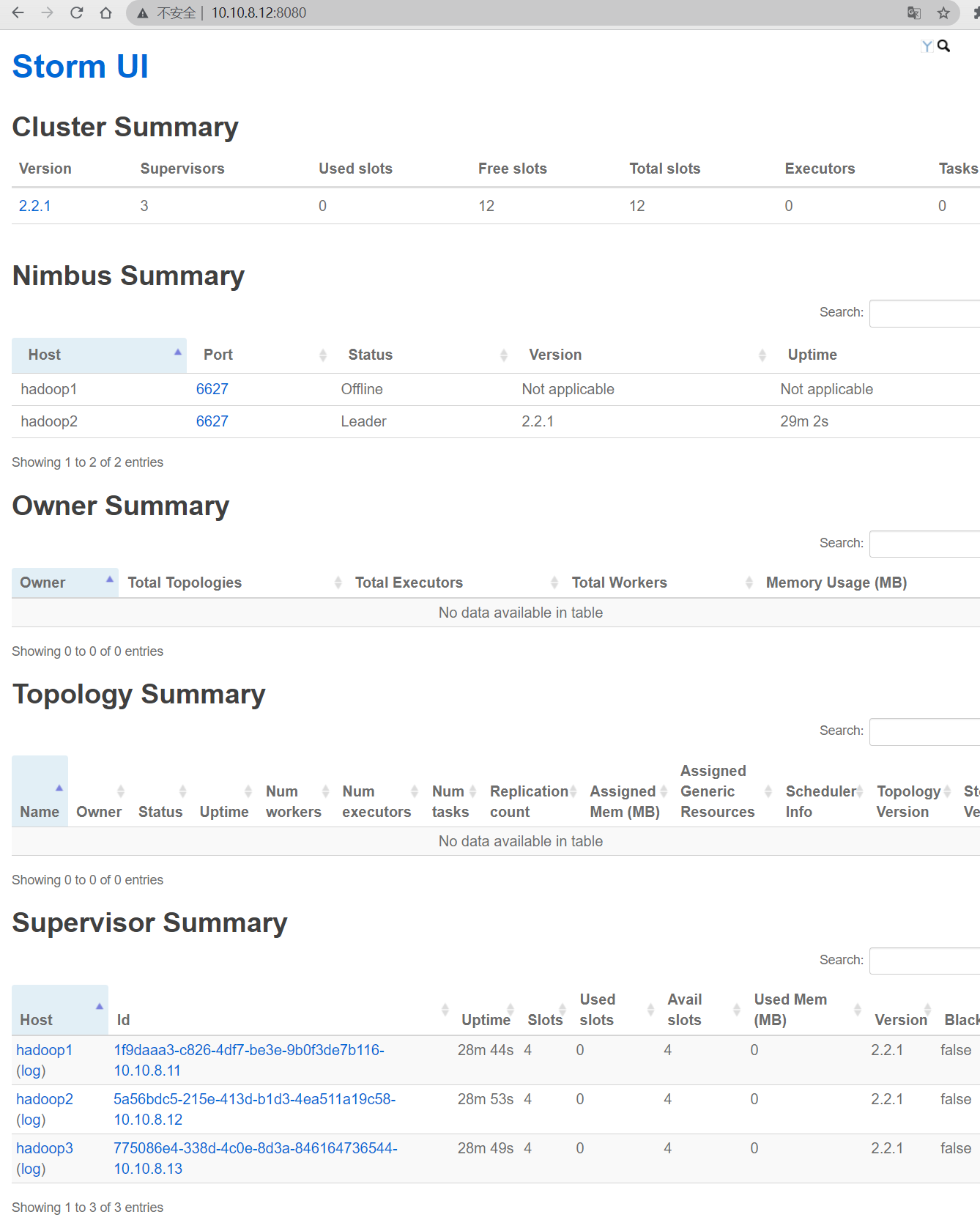
访问ui页面: http://storm_ui:8080/
五、Storm 高可用集群部署
服务规则
| 主机名 | 运行storm服务 | 依赖环境 |
|---|---|---|
| hadoop1 | Nimbus、UI、surpervisor | JDK1.8、zookeeper |
| hadoop2 | Nimbus、UI、surpervisor | JDK1.8、zookeeper |
| hadoop3 | surpervisor | JDK1.8、zookeeper |
4.1 配置 Storm
下载 storm
1 | [hadoop@hadoop1 downloads]$ wget https://downloads.apache.org/storm/apache-storm-2.2.1/apache-storm-2.2.1.tar.gz |
配置 storm.yaml
1 | [hadoop@hadoop1 ~]$ vim apache-storm-2.2.1/conf/storm.yaml |
更多配置可以查看 https://github.com/apache/storm/blob/v2.2.1/conf/defaults.yaml 。随着深入了解,可以优化集群配置。
配置storm环境变量
1 | [hadoop@hadoop1 ~]$ vim .bash_profile |
将拷贝配置到其它storm节点
1 | [hadoop@hadoop1 ~]$ rsync -av apache-storm-2.2.1 hadoop@hadoop2:~/ |
4.2 启动 Storm
启动 nimbus 节点和 storm ui
1 | [hadoop@hadoop1 ~]$ nohup storm nimbus >> apache-storm-2.2.1/nimbus.log & |
启动 Supervisor 节点
1 | [hadoop@hadoop1 ~]$ nohup storm supervisor >> apache-storm-2.2.1/supervisor.log & |
4.3 访问 Storm UI 页面
访问ui页面: http://storm_ui:8080/
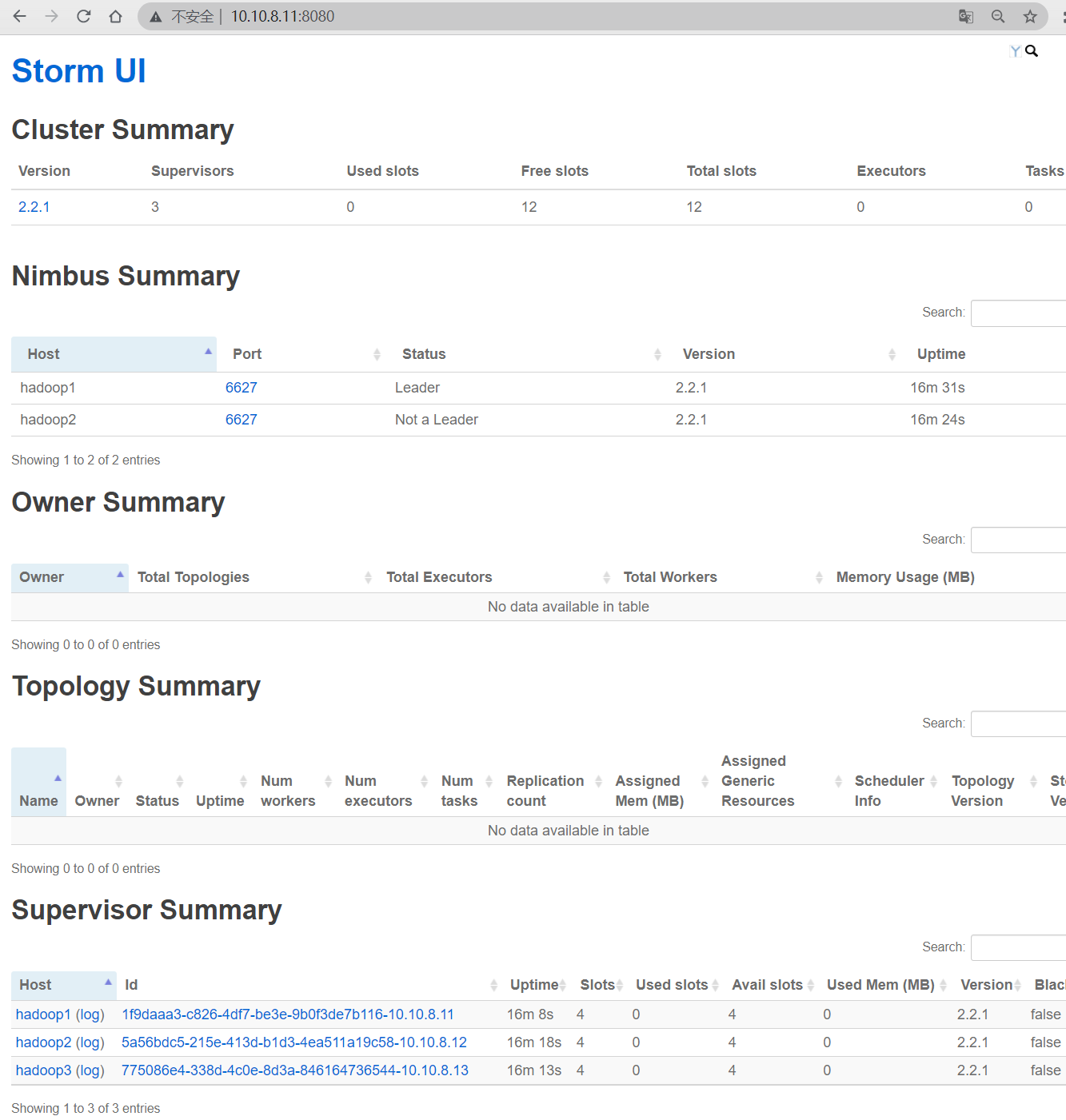
4.4 验证 Storm 高可用
停止leader节点的Nimbus服务
1 | [hadoop@hadoop1 ~/zookeeper-3.4.8/bin]$ jps |grep Nimbus |
再次访问 Storm UI,备用的Nimbus已经变为了leader状态