一、Metastore和Hiveserver2服务的区别
1.1 Metastore 服务
Metastore 服务访问元数据的方式
bin/hive(cli命令行的方式访问元数据) –访问–> metaStore server –访问–>MySQL
Metastore 服务启动方式
服务端启动Metastore服务
hive --service metastore客户端使用Hive连接
hive
1.2 Hiveserver2 服务
Hiveserver2 服务访问元数据的方式
bin/beeline(jdbc的方式访问元数据) –访问–>hiveServer2 –访问–> metaStore server –访问–> MySQL
Hiveserver2 服务启动方式
服务端启动hiveserver2服务
hive --service hiveserver2客户端使用beeline/Java编码jdbc连接
beeline -u jdbc:hive2://hiveserver2_ip:10000 -n hadoop
二、Hive Metastore 高可用配置
2.1 工作原理
常规连接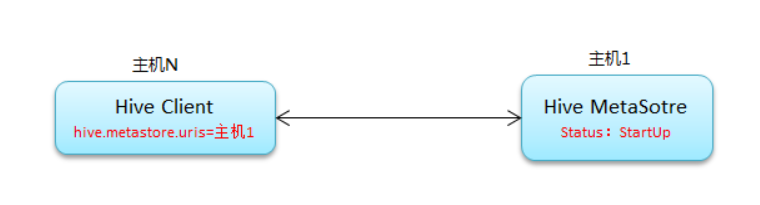
MetaStore HA连接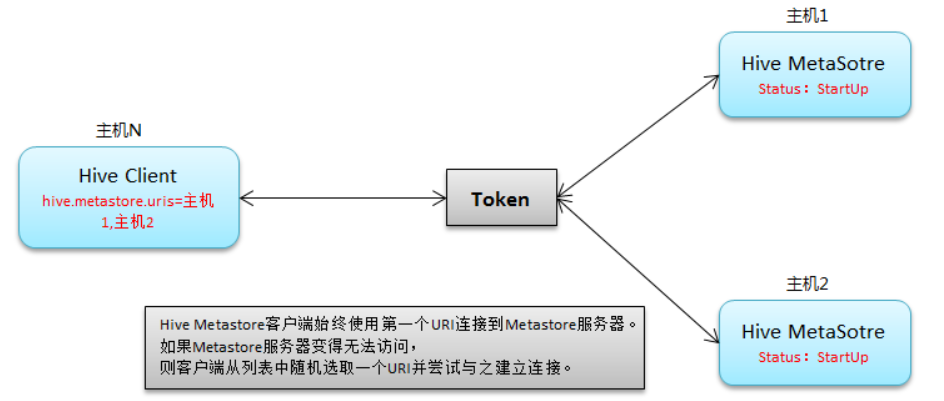
2.2 MetaStore 高可用配置
前置条件
Hadoop、Hive是可用的前提
服务规划
| 主机名 | 运行服务 |
|---|---|
| hadoop1 | MetaStore |
| hadoop2 | hive |
| hadoop3 | MetaStore |
添加hive和hadoop环境变量
1 | [hadoop@hadoop1 ~]$ vim .bash_profile |
2.2.1 Hive Server MetaStore 配置
修改 hive-site.xml 配置,和单节点配置一样,只不过在多台服务器上启动MetaSotre
1 | [hadoop@hadoop1 ~]$ vim apache-hive-2.3.9-bin/conf/hive-site.xml |
修改临时文件目录,建议所有hive都修改
1 | #将以下配置放在最前列 |
2.2.2 Hive Client HA 配置
修改 hive-site.xml 配置
1 | [hadoop@hadoop2 ~]$ vim apache-hive-2.3.9-bin/conf/hive-site.xml |
2.3 启动 MetaStore
启动两个节点的metastore服务
1 | [hadoop@hadoop1 ~]$ hive --service metastore |
2.4 验证 MetaStore高可用
先使用hive查询数据
1 | [hadoop@hadoop2 ~]$ hive |
把优先连接的第一个MetaStore服务关掉
1 | [hadoop@hadoop1 ~]$ jps |
再次查询数据
1 | hive> select * from t1; |
依然可以正常查询,说明MetaStore高可用配置成功
三、Hive Hiveserver2 高可用配置
Hive从0.14开始,使用Zookeeper实现了HiveServer2的HA功能(ZooKeeper Service Discovery),Client端可以通过指定一个nameSpace来连接HiveServer2,而不是指定某一个host和port。
在生产环境中使用Hive,强烈建议使用HiveServer2来提供服务,好处很多:
- 在应用端不用部署Hadoop和Hive客户端;
- 相比hive-cli方式,HiveServer2不用直接将HDFS和Metastore暴漏给用户;
- 有安全认证机制,并且支持自定义权限校验;
- 有HA机制,解决应用端的并发和负载均衡问题;
- JDBC方式,可以使用任何语言,方便与应用进行数据交互;
- 从2.0开始,HiveServer2提供了WEB UI。
3.1 工作原理
如果使用HiveServer2的Client并发比较少,可以使用一个HiveServer2实例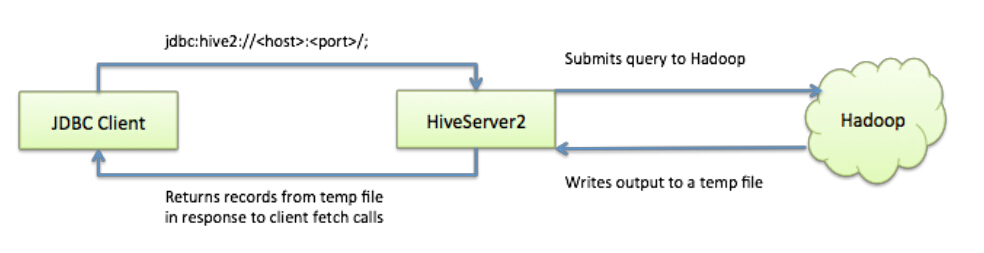
可以启用两个HiveServer2的实例,并通过zookeeper完成HA高可用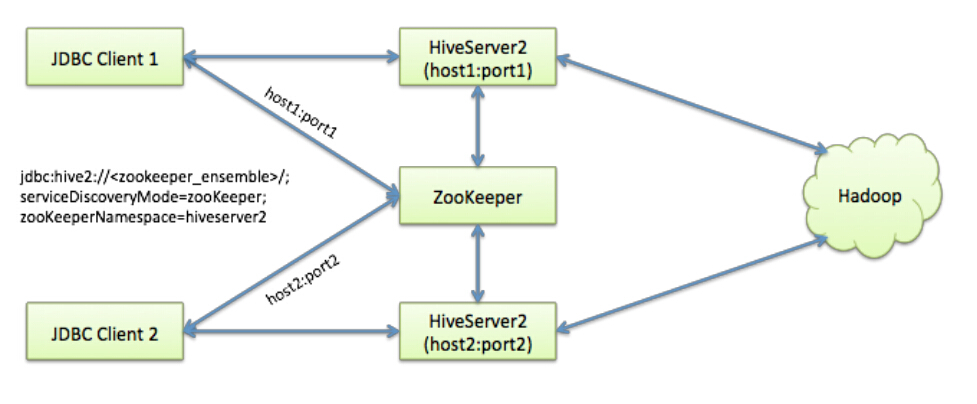
3.2 HiveServer2 高可用配置
前置条件
Hadoop、zookeeper、Hive是可用的前提
添加hive和hadoop环境变量
1 | export HADOOP_HOME=/home/hadoop/hadoop-2.7.2 |
服务规划
| 主机名 | 运行服务 | 依赖服务 |
|---|---|---|
| hadoop1 | HiveServer2 | zookeeper |
| hadoop2 | beeline | zookeeper |
| hadoop3 | HiveServer2 | zookeeper |
前置条件
zookeeper服务是可用的
Hive Server HiveServer2 配置,修改 hive-site.xml 配置
1 | [hadoop@hadoop1 ~]$ vim apache-hive-2.3.9-bin/conf/hive-site.xml |
注意修改 hive.server2.thrift.bind.host 的参数
3.3 启动 HiveServer2
1 | [hadoop@hadoop1 ~]$ hive --service hiveserver2 |
启动后,在ZK中可以看到两个HiveServer2都注册上来了
1 | [hadoop@hadoop1 ~/zookeeper-3.4.8/bin]$ ./zkCli.sh |
3.4 验证 HiveServer2高可用
先使用hive查询数据
1 | [hadoop@hadoop2 ~]$ beeline -u "jdbc:hive2://hadoop1:2181,hadoop2:2181,hadoop3:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2" -n hadoop |
把连接到hadoop1上的HiveServer2服务关掉
1 | [hadoop@hadoop1 ~/zookeeper-3.4.8/bin]$ jps |
再次查询数据
1 | 0: jdbc:hive2://hadoop1:2181,hadoop2:2181,had> select * from t1; |
查询报错,再次重新连接HiveServer2就可以了
1 | [hadoop@hadoop2 ~]$ beeline |