一、Hive 原理
Hive 是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive 最初是由Facebook开发的,后来开源给了Apache软件基金会,并作为Apache的一个顶级开源项目。Hive基于Hadoop,专为联机分析处理(On-Line Analytical Processing,OLAP)设计,但由于Hadoop MapReduce并不实时,所以Hive并不适合联机事务处理(On-Line Transaction Processing,OLTP)业务。Hive的最佳使用场合是大数据集的批处理作业。
1.1 Hive 的定义
Hive是建立在Hadoop上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(Extract-Transform-Load,ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hive定义了简单的类SQL查询语言,称为Hive QL,简称HQL,它允许熟悉SQL的用户查询数据。
同时,这个语言也允许熟悉MapReduce的开发者开发自定义的Mapper和Reducer程序来处理内建的Mapper和Reducer无法完成的复杂的分析工作。Hive没有专门的数据格式,可以很好地工作在Thrift之上。
1.2 Hive 的设计特征
Hive是一种底层封装了Hadoop的数据仓库处理工具,使用类SQL的Hive QL语言实现数据查询,所有Hive的数据都存储在Hadoop兼容的文件系统(例如Amazon S3、HDFS)中。Hive在加载数据过程中不会对数据进行任何的修改,只是将数据移动到HDFS中Hive设定的目录下,因此,Hive不支持对数据的改写和添加,所有的数据都是在加载时确定的。Hive的设计特点如下:
(1)不同的存储类型,例如纯文本文件、HBase中的文件;
(2)将元数据保存在关系数据库中,可大大减少在查询过程中执行语义检查的时间;
(3)可以直接使用存储在Hadoop文件系统中的数据;
(4)内置大量函数来操作时间、字符串和其他的数据挖掘工具,支持用户扩展UDF函数来完成内置函数无法实现的操作;
(5)类SQL的查询方式,将SQL查询转换为MapReduce的Job在Hadoop集群上执行。
1.3 Hive 的体系结构
Hive本身建立在Hadoop的体系结构上,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务,然后交给Hadoop集群进行处理。
Hive的体系结构如下图所示: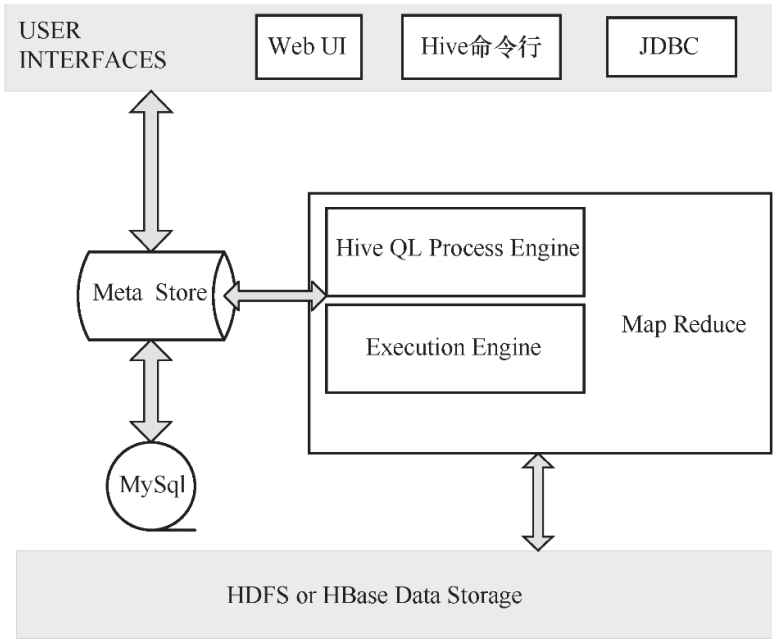
USER INTERFACES:Hive 是一个数据仓库基础工具软件,可以通过用户接口实现与HDFS之间的互动。用户接口包括Web UI、Hive命令行、JDBC;
Meta Store:Hive 选择各自的数据库服务器,用以储存表、数据库、列模式、元数据表、数据类型和HDFS映射。一般使用MySQL存储Hive的元数据信息;
Hive QL Process Engine:Hive QL处理引擎包括解释器、编译器、优化器等,完成Hive QL查询语句从词法分析、语法分析、编译、优化到查询计划生成的整个过程;
Execution Engine:Hive 执行引擎处理查询请求并产生返回结果,由MapReduce调用执行;
HDFS or HBase Data Storage:Hadoop HDFS或者HBase数据存储技术将数据存储到HDFS或HBase文件系统中。
1.4 Hive 的数据存储模型
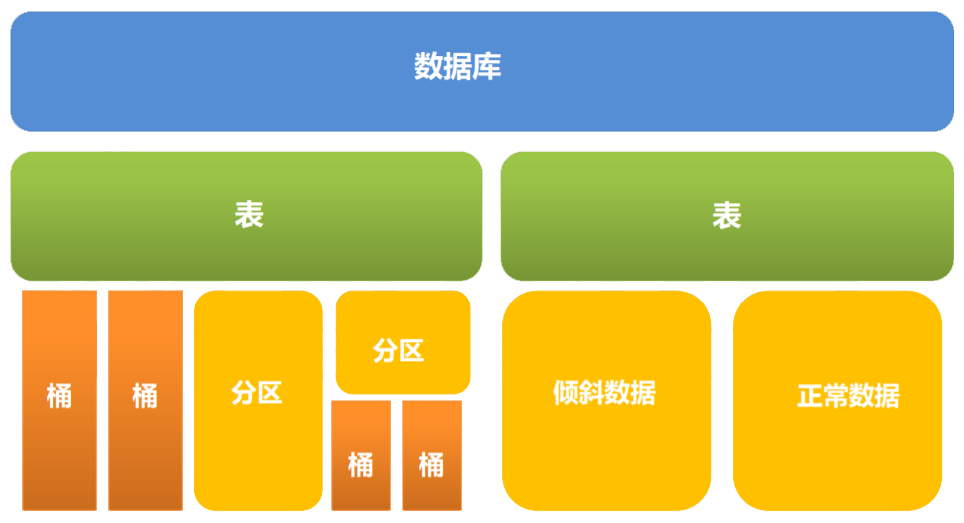
1.4.1 分区和桶
- 分区:数据表可以按照某个字段的值划分分区。
每个分区是一个目录。
分区数量不固定。
分区下可再有分区或者桶。 - 桶:数据可以根据桶的方式将不同数据放入不同的桶中。
每个桶是一个文件。
建表时指定桶个数,桶内可排序。
数据按照某个字段的值Hash后放入某个桶中。
在Hive中,一个Partition对应于表下的一个目录,所有的Partition的数据都存储在对应的目录中;Buckets对指定列计算hash,根据hash值切分数据,目的是为了并行,每个Bucket对应一个文件。
1.4.2 托管表和外部表
- Hive 默认创建托管表,由Hive来管理数据,意味着Hive会将数据移动到数据仓库目录;
- 另外一种选择是创建外部表,这时Hive会到仓库目录以外的位置访问数据。
| 操作 | 托管表 | 外部表 |
|---|---|---|
| CREATE LOAD | 把数据移到仓库目录 | 创建表时指明外部数据的位置 |
| DROP | 元数据和数据会被一起删除 | 只删除元数据 |
如何选择?
- 如果所有处理都由Hive完成,建议使用托管表;
- 如果要用Hive和其它工具来处理同一个数据集,应该使用外部表。
1.5 Hive 中SQL-MapReduce 原理
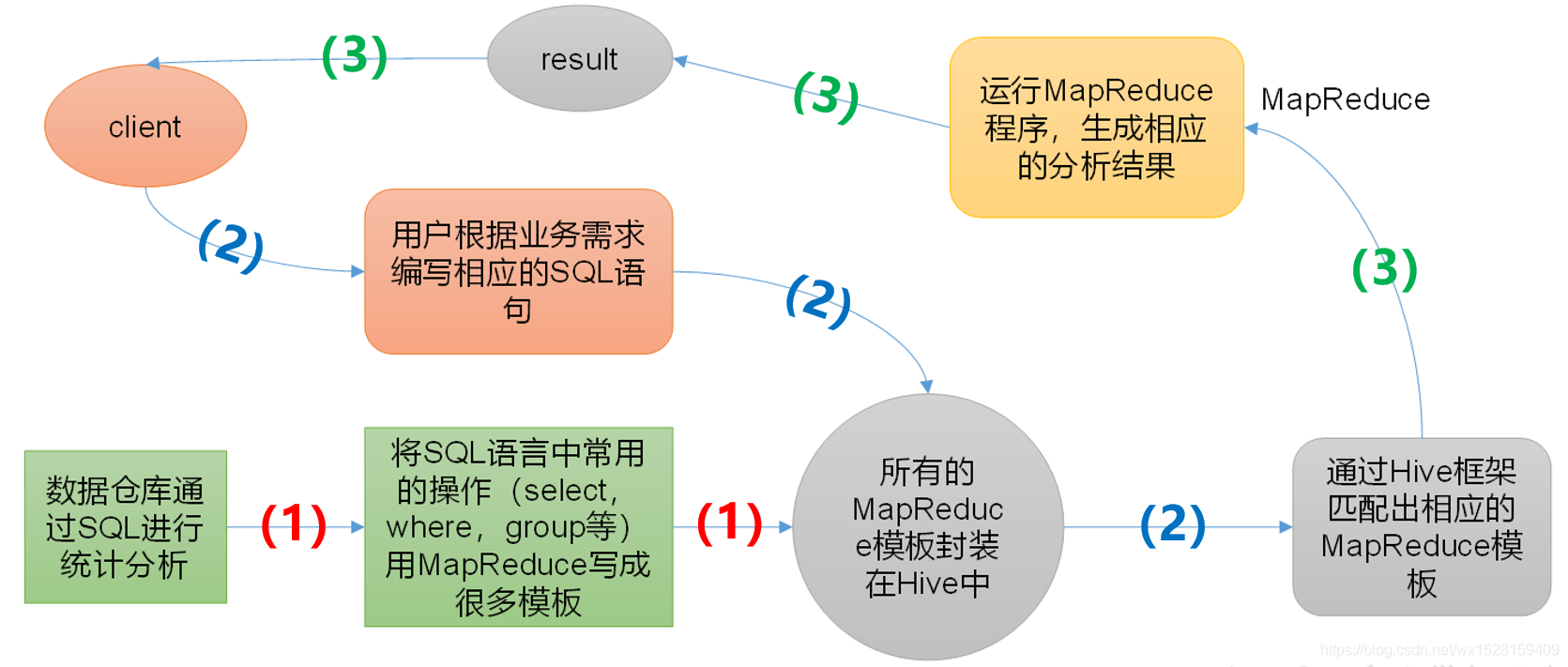
(1)事先将常用的SQL操作封装成MapReduce模板存放在Hive中;
(2)client依据实际需求写SQL语句,匹配对应的MapReduce模板,然后运行对应的MapReduce程序,
(3)生成相应的分析结果,返回给client。
1.6 Hive 的优缺点
Hive的优点
- 高可靠、高容错:HiveServer采用集群模式, 双MetaStore,超时重试机制;
- 类SQL:类似SQL语法,内置大量函数;
- 可扩展:自定义存储格式,自定义函数;
- 多接口:Beeline,JDBC,ODBC,Python,Thrift。
Hive的缺点
- 延迟较高:默认MR为执行引擎,MR延迟较高(支持MapReduce,Tez,Spark等多种计算引擎);
- 不支持物化视图:Hive支持普通视图,不支持雾化视图。Hive不能再视图上更新、插入、删除数据;
- 不适用OLTP:暂不支持列级别的数据添加、更新、删除操作;
- 暂不支持存储过程:当前版本不支持存储过程,只能通过UDF来实现一些逻辑处理。
1.7 Hive 与传统数据库对比
| Hive | 传统数据库 | |
|---|---|---|
| 存储 | HDFS,理论上可无限拓展 | 集群存储,存在容量上限,而且伴随容量的增长,计算速度急剧下降。只能适应于数据量比较小的商业应用,对于超大规模数据无能为力。 |
| 执行引擎 | 有MR/Tez/Spark多种引擎 | 可以选择更加高效的算法来执行查询,也可以进行更多的优化措施来提高速度 |
| 使用方式 | HQL(类似SQL) | SQL |
| 灵活性 | 元数据存储独立于数据存储 之外,解耦合元数据和数据 | 低,数据用途单一 |
| 分析速度 | 计算依赖于集群规模,易拓展,在大数据量情况下,远远快于普通数据库 | 在数据容量较小时非常快速,数据量较大时,急剧下降 |
| 索引 | 低效,目前还不完善 | 高效 |
| 易用性 | 需要自行开发应用模型,灵活度较高,但是易用性较低 | 集成一整套成熟的的报表解决方案,可以较为方便的进行数据的分析 |
| 可靠性 | 数据存储在HDFS,可靠性高, 容错性高 | 可靠性较低,一次查询失败需要重新开始。数据容错依赖于硬件Raid |
| 依赖环境 | 依赖硬件较低,可适应一般的普通机器 | 依赖于高性能的商业服务器 |
| 价格 | 开源产品 | 商用比较昂贵 |
综上所述: 由于数据库和数据仓库设计目的完全不一样,两者的性能有所差异,用法也是有很大差别的,这一点主要体现在表的设计和操作类型上。
但是数据库和数据仓库也并不是完全独立的两个东西,数据仓库可以借助于某些数据库来实现,这也是为什么有人说数据仓库不是一个实体,而是一种方案的主要原因。
二、Hive 部署
可在官网查看Hive与Hadoop相对应的版本
2.1 配置 Hive 用户和库
mysql 配置 hive用户和数据库
1 | mysql> create database if not exists hive_metadata; |
2.2 配置 Hive
2.2.1 准备 Hive和 Mysql驱动
1 | #准备hive |
2.2.2 配置 Hive环境变量
1 | [hadoop@hadoop1 ~]$ vim .bash_profile |
2.2.3 修改 hive-site.xml 配置
1 | [hadoop@hadoop1 ~]$ cp apache-hive-2.3.9-bin/conf/hive-default.xml.template apache-hive-2.3.9-bin/conf/hive-site.xml |
修改临时文件目录
1 | #将以下配置放在最前列 |
2.3 启动 Hive
2.3.1 Hive 数据库初始化
执行 schematool -dbType mysql -initSchema,进行Hive数据库的初始化
1 | [hadoop@hadoop1 ~]$ schematool -dbType mysql -initSchema |
2.3.2 启动 Hive 客户端
1 | [hadoop@hadoop1 ~]$ hive |
三、Hive 分布式部署
服务规划
| 主机名 | 运行服务 | 其它依赖服务 |
|---|---|---|
| hadoop1 | Hive Server | MySQL、HDFS |
| hadoop2 | Hive Client |
前置条件
mysql和HDFS是可用的
3.1 配置 Hive 用户和库
mysql 配置 hive用户和数据库
1 | mysql> create database if not exists hive_metadata; |
3.2 配置 Hive Server
3.2.1 准备 Hive和 Mysql驱动
1 | #准备hive |
3.2.2 配置 Hive环境变量
1 | [hadoop@hadoop1 ~]$ vim .bash_profile |
3.2.3 修改 hive-site.xml 配置
1 | [hadoop@hadoop1 ~]$ cp apache-hive-2.3.9-bin/conf/hive-default.xml.template apache-hive-2.3.9-bin/conf/hive-site.xml |
修改临时文件目录
1 | #将以下配置放在最前列 |
3.2.4 Hive 数据库初始化
执行 schematool -dbType mysql -initSchema,进行Hive数据库的初始化
1 | [hadoop@hadoop1 ~]$ schematool -dbType mysql -initSchema |
3.2.5 master运行 metastore
1 | [hadoop@hadoop1 ~]$ hive --service metastore |
3.3. 配置 Hive Client
3.3.1 配置 Hive环境变量
1 | [hadoop@hadoop2 ~]$ vim .bash_profile |
3.3.2 修改 hive-site.xml 配置
1 | [hadoop@hadoop1 ~]$ cp apache-hive-2.3.9-bin/conf/hive-default.xml.template apache-hive-2.3.9-bin/conf/hive-site.xml |
修改临时文件目录
1 | #将以下配置放在最前列 |
3.3.3 启动 Hive 客户端
1 | [hadoop@hadoop2 ~]$ hive |