一、简介
NoSQL是Not Only SQL的缩写,泛指用来解决大数据相关问题而创建的数据库技术,NoSQL技术不会完全替代关系型数据库,而是关系型数据的一种补充。HBase是建立在Hadoop文件系统之上的分布式面向列的NoSQL数据库。它是一个开源项目,可横向扩展。HBase的数据模型,类似于谷歌的BigTable设计,可以快速随机访问海量半结构化数据,并利用了Hadoop的文件系统HDFS提供的容错能力。
二、HBase 原理
HBase 是NoSQL数据库的一种,与传统关系型数据库有很多区别,既可以存储结构化数据,也可以存储非结构化数据或半结构化数据。
2.1 HBase 概述
如果需要实时随机地访问超大规模数据集,就可以使用HBase这一Hadoop应用。HBase是一个在HDFS上开发的面向列的分布式数据库。
虽然数据库存储和检索的实现可以选择很多不同的策略,但是绝大多数解决办法,特别是关系型数据库技术的变种,不是为大规模可伸缩的分布式处理设计的。很多厂商提供了复制(replication)和分区(partitioning)解决方案,让数据库能够从单个节点上扩展出去,但是这些附加的技术大都属于事后的解决办法,而且非常难以安装和维护,并且这些解决办法常常要牺牲一些重要的关系型数据库管理系统(RDBMS)特性。
在一个扩展的RDBMS上,连接、复杂查询、触发器、视图以及外键约束这些功能或运行开销大,或根本无法用。HBase从另一个方向来解决可伸缩性的问题,它自底向上地进行构建,能够简单地通过增加节点来达到线性扩展的目的。
HBase并不是关系型数据库,它不支持SQL。但在特定的问题空间里,它能够做RDBMS不能做的事:在廉价硬件构成的集群上管理超大规模的稀疏表。
HBase是Apache的顶级开源项目,本质上是谷歌BigTable的开源山寨版本。建立的HDFS之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统,它介于NoSQL和RDBMS之间,仅能通过主键(row key)和主键的范围(range)来检索数据,仅支持单行事务(可通过Hive支持来实现多表join等复杂操作)。主要用来存储非结构化和半结构化的松散数据。
2.2 HBase 核心概念
HBase的数据存放在带标签的表中。表由行和列组成。表格的单元格(cell)由行和列的坐标交叉决定,是有版本的。默认情况下,版本号是自动分配的,为HBase插入单元格时的时间戳。单元格的内容是未解释的字节数组。HBase是一个稀疏、长期存储、多维度、排序的映射表。这张表的索引是行关键字、列关键字和时间戳。每个值是一个二进制的字节数组。
- 行关键字
row key保存为字节数组,是用来检索记录的主键。可以是任意字符串(最大长度是64KB)。存储时,数据按照row key的字典序(byte order)排序存储。设计row key时,要充分利用排序存储这个特性,将经常一起读取的行存储放到一起。 - 列关键字
列关键字由列族column family和列qualifier两部分组成。列族是表的schema元数据的一部分(而列不是),必须在使用表之前定义。列名都以列族作为前缀。例如courses:history、courses:math都属于courses这个列族。有关联的数据应都放在一个列族里,否则将降低读写效率。目前HBase并不能很好地处理多个列族,建议最多使用两个列族。 - 时间戳
HBase中通过row和columns确定的一个存储单元称为cell。每个cell都保存着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是64位整型。时间戳可以由HBase在数据写入时自动赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显式赋值。如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。每个cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。为了避免数据存在过多版本造成管理(包括存储和索引)负担,HBase提供了两种数据版本回收方式。一是保存数据的最后N个版本(比如3个),二是保存最近一段时间内的版本(比如最近7天)。用户可以针对每个列族进行设置。 - cell
由{row key, column(=<family> + <label>), version}唯一确定的单元,cell中的数据是没有类型的,全部以字节码形式存储。
与NoSQL数据库一样,row key是用来检索记录的主键。访问HBase表中的行,只有3种方式。
(1)通过单个row key访问单条记录。
(2)通过row key的range指定检索范围。
(3)全表扫描。
物理上,所有的列族成员都一起存放在文件系统中。所以,虽然把HBase描述为一个面向列的存储器,但实际上更准确的说法是,HBase是个面向列族的存储器。由于调优和存储都是在列族这个层次进行的,所以最好使所有列族成员都有相同的访问模式(access pattern)和大小特征。简而言之,HBase表和RDBMS中的表类似,单元格有版本,行是排序的,而只要列族预先存在,客户端随时可以把列添加到列族中去。
HBase存储格式如下图所示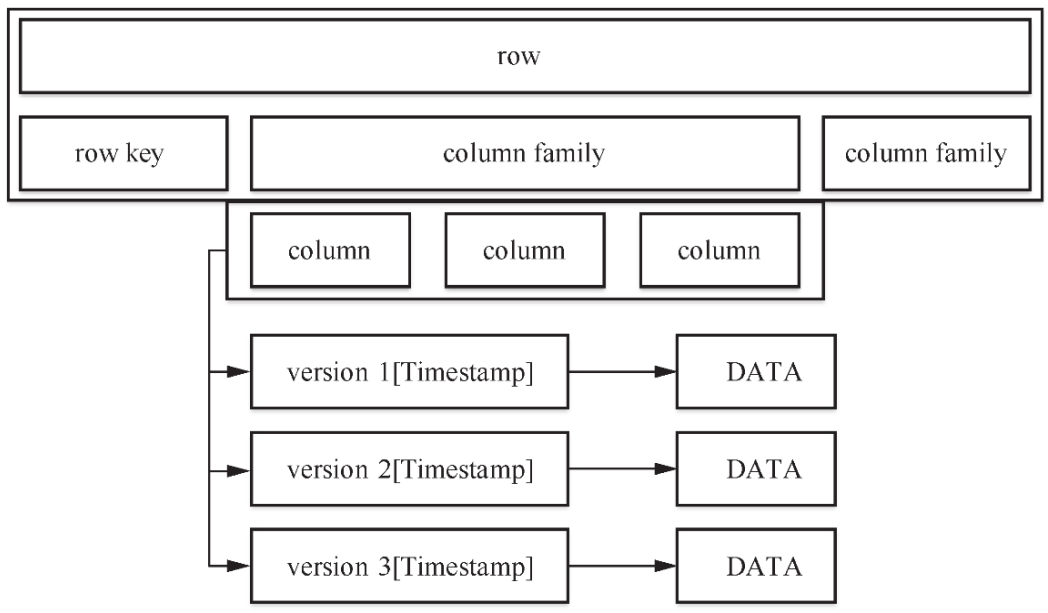
一个典型的RDBMS二维表格式如下所示
对应的数据在HBase中的存储格式如下所示
HBase自动把表水平划分成区域(region)。每个区域由表中行的子集构成。每个区域由它所属的表、它所包含的第一行及最后一行(不包括这行)来表示。
一开始,一个表只有一个区域。但是随着区域变大,等到它的大小超出设定的阈值时,便会在某行的边界上把表分成两个大小基本相同的新分区。在第一次划分之前,所有加载的数据都放在原始区域所在的服务器上。
随着表变大,区域的个数也会增加。区域是在HBase集群上分布数据的最小单位。用这种方式,一个因为太大而无法放在单台服务器上的表会被放到服务器集群上,其中每个节点都负责管理表所在区域的一个子集。表的加载也是使用这种方法把数据分布到各个节点。在线的所有区域按次序排列就构成了表的所有内容。
常规的HBase服务器部署结构如下图所示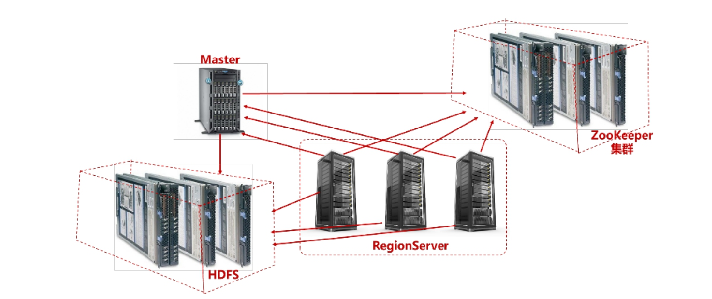
各个角色的功能如下:
(1)Region:表中一部分数据组成的子集,当Region内的数据过多时能够自动分裂,过少时会合并。
(2)RegionServer:维护Master分配给它的Region,处理对这些Region的IO请求,负责切分在运行过程中变得过大的Region。
(3)Master:为RegionServer分配Region,负责RegionServer的负载均衡,发现失效的RegionServer并重新分配其上的Region,执行HDFS上的垃圾文件回收。
(4)ZooKeeper:保证任何时候集群中只有一个Master存储所有Region的寻址入口。实时监控RegionServer的状态,将RegionServer的上线和下线信息实时通知给Master。存储HBase的Schema,包括有哪些table、每个table有哪些column family,处理Region和Master的失效。
以下是HBase与RMDBS的主要差异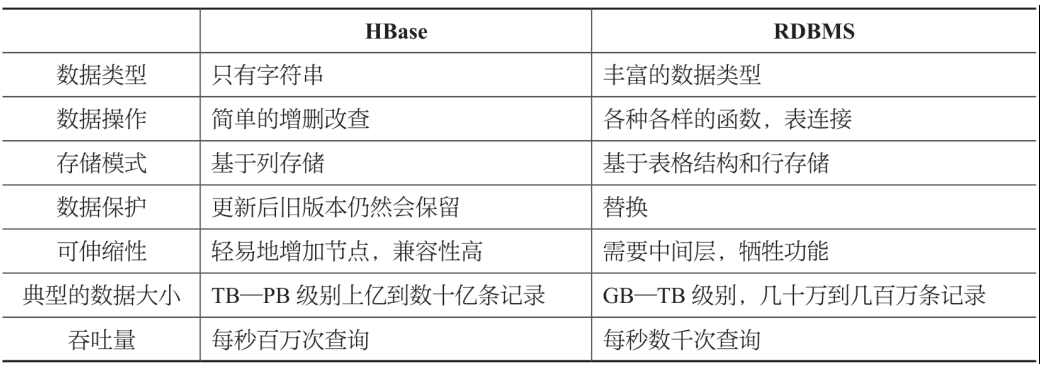
2.3 HBase 的关键流程
HBase客户端会将查询过的HRegion的位置信息进行缓存,如果客户端没有缓存一个HRegion的位置或者位置信息是不正确的,客户端会重新获取位置信息。如果客户端的缓存全部失效,则需要进行多次网络访问才能定位到正确的位置。
2.3.1 Region的分配
任何时刻,一个Region只能分配给一个RegionServer。Master跟踪当前有哪些可用的RegionServer,以及当前哪些Region分配给了哪些RegionServer,哪些Region还没有分配。当存在未分配的Region且有一个RegionServer上有可用空间时,Master就给这个RegionServer发送一个装载请求,把Region分配给这个RegionServer。RegionServer得到请求后,就开始对此Region提供服务。
2.3.2 RegionServer上线
Master使用ZooKeeper来跟踪RegionServer状态。当某个RegionServer启动时,会首先在ZooKeeper上的rs目录下建立代表自己的文件,并获得该文件的独占锁。由于Master订阅了rs目录上的变更消息,当rs目录下的文件出现新增或删除操作时,Master可以得到来自ZooKeeper的实时通知。因此一旦RegionServer上线,Master能马上得到消息。
2.3.3 RegionServer下线
当RegionServer下线时,它和ZooKeeper的会话断开,ZooKeeper会自动释放代表这台Server的文件上的独占锁,而Master不断轮询rs目录下文件的锁状态。如果Master发现某个RegionServer丢失了它自己的独占锁,Master就会尝试去获取代表这个RegionServer的读写锁,一旦获取成功,就可以确定:
(1)RegionServer和ZooKeeper之间的网络断开了;
(2)RegionServer失效了。
只要这两种情况中的一种情况发生了,无论哪种情况,RegionServer都无法继续为它的Region提供服务,此时Master会删除Server目录下代表这台RegionServer的文件,并将这台RegionServer的Region分配给其他还活着的机器。
如果网络短暂出现问题导致RegionServer丢失了它的锁,那么RegionServer重新连接到ZooKeeper之后,只要代表它的文件还在,它就会不断尝试获取这个文件上的锁,一旦获取到了,就可以继续提供服务。
2.3.4 Master上线
Master启动上线包括以下步骤。
(1)从ZooKeeper上获取唯一代表Master的锁,用来阻止其他节点成为Master。
(2)扫描ZooKeeper上的Server目录,获得当前可用的RegionServer列表。
(3)与每个RegionServer通信,获得当前已分配的Region和RegionServer的对应关系。
(4)扫描.META.region的集合,计算得到当前还未分配的Region,将它们放入待分配Region列表。
2.3.5 Master下线
(1)由于Master只维护表和Region的元数据,而不参与表数据IO的过程,所以Master下线仅导致所有元数据的修改被冻结。此时无法创建、删除表,无法修改表的schema,无法进行Region的负载均衡,无法处理Region上下线,无法进行Region的合并,唯一例外的是Region的split可以正常进行,因为只有RegionServer参与,表的数据读写还可以正常进行。因此Master下线短时间内对整个HBase集群没有影响。
(2)Master下线,启用Zookeeper的选举机制,确定新的Master,新的Master执行上线流程
从上线过程可以看到,Master保存的信息全是冗余信息,都可以从系统其他地方收集或者计算出来。因此,一般HBase集群中总是有一个Master在提供服务,还有一个以上的Master在等待时机抢占它的位置。
当客户端要修改HBase的数据时,首先创建一个action(比如put、delete、incr等操作),这些action都会被包装成Key-Value对象,然后通过RPC将其传输到HRegionServer上。HRegionServer将其分配给相应的HRegion,HRegion先将数据写入Hlog中,然后将其写入MemStore。MemStore中的数据是排序的,当MemStore累计到一定阈值时,就会创建一个新的MemStore,并且将老的MemStore添加到flush队列,由单独的线程flush到磁盘上,成为一个StoreFile。与此同时,系统会在ZooKeeper中记录一个redo point,表示这个时刻之前的变更已经持久化了。当系统出现意外时,可能导致内存(MemStore)中的数据丢失,此时使用Log(WAL log)来恢复redo point之后的数据。
StoreFile是只读的,一旦创建后就不可以再修改,因此HBase的更新其实是不断追加的操作。当一个Store中的StoreFile达到一定的阈值后,就会进行一次合并,将对同一个key的修改合并到一起,形成一个大的StoreFile。
由于对表的更新是不断追加的,处理读请求时,需要访问Store中全部的StoreFile和MemStore,将它们的数据按照row key进行合并,由于StoreFile和MemStore都是经过排序的,并且StoreFile带有内存中索引,所以合并的过程还是比较快的。
2.3.6 读请求处理过程
(1)客户端通过 ZooKeeper 以及-ROOT-表和.META.表找到目标数据所在的 RegionServer(就是数据所在的 Region 的主机地址);
(2)zk返回结果给客户端;
(3)联系 RegionServer 查询目标数据;
(4)RegionServer 定位到目标数据所在的 Region,发出查询请求;
(5)Region 先在 Memstore 中查找,命中则返回;
(6)如果在 Memstore 中找不到,则在 Storefile 中扫描,为了能快速的判断要查询的数据在不在这个 StoreFile 中,应用了 BloomFilter;
(BloomFilter,布隆过滤器:迅速判断一个元素是不是在一个庞大的集合内,但是他有一个 弱点:它有一定的误判率);
(误判率:原本不存在与该集合的元素,布隆过滤器有可能会判断说它存在,但是,如果布隆过滤器,判断说某一个元素不存在该集合,那么该元素就一定不在该集合内)。
2.3.7 写请求处理过程
写请求处理过程如下:
(1)Client向RegionServer提交写请求;
(2)RegionServer找到目标Region;
(3)Region检查数据是否与schema一致;
(4)如果客户端没有指定版本,则获取当前系统时间作为数据版本;
(5)将更新写入WAL log;
(6)将更新写入Memstore;
(7)判断Memstore的数据是否需要flush为StoreFile。
三、HBase 集群部署
官网下载HBase:https://hbase.apache.org/downloads.html
服务规则
| 主机名 | 运行HBase服务 |
|---|---|
| hadoop1 | Master、RegionServer |
| hadoop2 | Backup_Master、RegionServer |
| hadoop3 | Backup_Master、RegionServer |
3.1 修改 HBase配置文件
下载 hbase
1 | [hadoop@hadoop1 ~/downloads]$ wget https://archive.apache.org/dist/hbase/2.3.6/hbase-2.3.6-bin.tar.gz |
复制 hdfs-site.xml 配置文件
1 | [hadoop@hadoop1 ~]$ cp hadoop-2.7.2/etc/hadoop/hdfs-site.xml hbase-2.3.6/conf/ |
复制$HADOOP_HOME/etc/hadoop/hdfs-site.xml到$HBASE_HOME/conf目录下,这样以保证hdfs与hbase两边一致,这也是官网所推荐的方式。在官网中提到一个例子,例如hdfs中配置的副本数量为5,而默认为3,如果没有将最新的hdfs-site.xml复制到$HBASE_HOME/conf目录下,则hbase将会按3份备份,从而两边不一致,导致会出现异常
修改 hbase-site.xml
1 | [hadoop@hadoop1 ~]$ vim hbase-2.3.6/conf/hbase-site.xml |
修改 hbase-env.sh 添加 Java 运行环境
1 | [hadoop@hadoop1 ~]$ vim hbase-2.3.6/conf/hbase-env.sh |
修改 regionserver
1 | [hadoop@hadoop1 ~]$ vim hbase-2.3.6/conf/regionservers |
创建 backup-masters 备用master配置文件
1 | [hadoop@hadoop1 ~]$ vim hbase-2.3.6/conf/backup-masters |
同步hbase节点配置
1 | [hadoop@hadoop1 ~]$ rsync -av hbase-2.3.6 hadoop@hadoop2:~/ |
3.2 启动 HBase
启动所有服务
1 | [hadoop@hadoop1 ~]$ cd hbase-2.3.6/bin/ |
也可以只启动单个服务
#启动hbase master
hbase-daemon.sh start master#启动hbase regionserver
hbase-daemon.sh start regionserver
查看 hbase 服务进程
1 | [hadoop@hadoop1 ~]$ jps |
3.3 访问 HBase Web UI
HBase Web UI使用的HTTP端口Master的16010和RegionServer的16030。
如果一切设置正确,能够使用 Web 浏览器连接到 Master,或辅助Master 的 UI
Master Web UI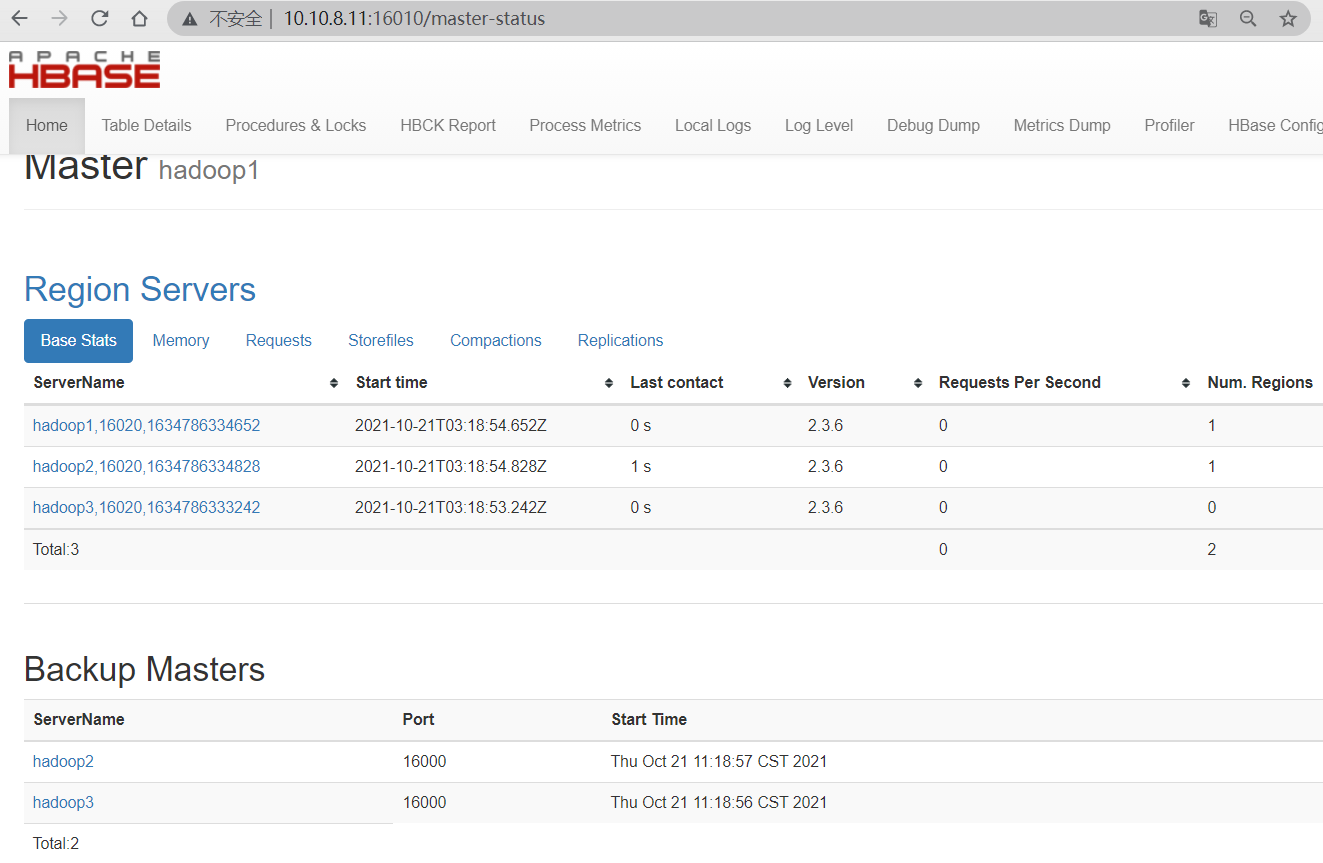
RegionServer Web UI
四、HBase Shell
4.1 HBase Shell 常用命令
| 命名 | 描述 | 语法 |
|---|---|---|
| 通用命令 | ||
| help ‘命令名’ | 查看命令的使用描述 | help '命令名' |
| whoami | 我是谁 | whoami |
| version | 返回hbase版本信息 | version |
| status | 返回hbase集群的状态信息 | status |
| table_help | 查看如何操作表 | table_help |
| tools | 列出hbase所支持的工具 | tools |
| shutdown | 关闭hbase集群(与exit不同) | shutdown |
| exit | 退出hbase shell | exit |
| 数据定义语言 DDL | ||
| create | 创建表 | create '表名','列族名1','列族名2','列族名N' |
| alter | 修改列族 | 添加一个列族:alter '表名','列族名'删除列族:alter '表名',{NAME=> '列族名',METHOD=> 'delete'} |
| describe | 显示表相关的详细信息 | describe '表名' |
| list | 列出hbase中存在的所有表 | list |
| exists | 测试表是否存在 | exists '表名' |
| enable | 使表有效 | enable '表名' |
| is_enabled | 是否启用 | is_enabled '表名' |
| disable | 使表无效 | disable '表名' |
| is_disabled | 是否无效 | is_disabled '表名' |
| drop | 删除表 | drop的表必须是disable的 'disable' 表名,'drop' 表名 |
| drop_all | 删除满足正则表达式的所有表 | drop_all '正则表达式' |
| truncate | 重新创建指定表 | truncate '表名' |
| 数据操纵语言 DML | ||
| delete | 删除指定对象的值(可以为表,行,列对应的值,另外也可以指定时间戳的值) | 删除列族的某个列: delete '表名','行键','列族名:列名' |
| deleteall | 删除指定行的所有元素值 | deleteall '表名','行键' |
| get_counter | 获取计数器 | get_counter '表名','行键','列族:列名' |
| put | 添加或修改的表的值 | put '表名','行键','列族名','列值'put '表名','行键','列族名:列名','列值' |
| scan | 通过对表的扫描来获取对用的值 | scan '表名'扫描某个列族: scan '表名', {COLUMN=>'列族名'}扫描列族的某个列: scan '表名', {COLUMN=>'列族名:列名'}查询同一个列族的多个列: scan '表名', {COLUMNS => ['列族名1:列名1','列族名1:列名2', …]} |
| get | 获取行或单元(cell)的值 | get '表名', '行键'get '表名', '行键', '列族名' |
| count | 统计表中行的数量 | count '表名' |
| incr | 增加指定表行或列的值 | incr '表名', '行键','列族:列名',步长值 |
4.2 HBase Shell 常用操作
使用shell登录
1 | $ hbase shell |
create 创建一个表
1 | hbase(main):006:0> create 'member','member_id','address','info' |
describe 查看表的描述
1 | hbase(main):008:0> describe 'member' |
对表添加一个列族
1 | hbase(main):009:0> alter 'member','id' |
删除一个列族
1 | hbase(main):010:0> alter 'member', {NAME => 'member_id', METHOD => 'delete'} |
删除列
1 | #通过delete命令,我们可以删除id为某个值的‘info:age’字段 |
启动/禁用表
1 | #通过enable和disable来启用/禁用这个表,相应的可以通过is_enabled和is_disabled来检查表是否被禁用 |
exists 检查表是否存在
1 | hbase(main):021:0> exists 'member' |
drop 删除表
1 | #删除表需要先将表disable |
put 推送数据到HBase表
1 | hbase(main):030:0> create 'table1','id','address','info' |
count
查询表中有多少行
1 | hbase(main):043:0> count 'table1' |
get
1 | #获取一个id的所有数据 |
scan
1 | #查询整表数据 |