一、Ambari 介绍
Apache Ambari 项目旨在通过开发用于配置、管理和监控 Apache Hadoop 集群的软件来简化 Hadoop 管理。Ambari 提供了一个直观、易于使用的 Hadoop 管理 Web UI,由其 RESTful API 支持。
Ambari 使系统管理员能够:
配置 Hadoop 集群
- Ambari 提供了一个分步向导,用于在任意数量的主机上安装 Hadoop 服务。
- Ambari 处理集群的 Hadoop 服务配置。
管理 Hadoop 集群
- Ambari 为启动、停止和重新配置整个集群的 Hadoop 服务提供集中管理。
监控 Hadoop 集群
- Ambari 提供了一个仪表板,用于监控 Hadoop 集群的运行状况和状态。
- Ambari 利用Ambari Metrics System进行指标收集。
- Ambari 利用Ambari Alert Framework进行系统警报,并会在需要您注意时通知您(例如,节点出现故障、剩余磁盘空间不足等)。
Ambari 使应用程序开发人员和系统集成商能够:
- 使用Ambari REST API将 Hadoop 资源调配、管理和监控功能轻松集成到自己的应用程序中。
二、Ambari 有什么新功能?
- Ambari 的最新版本是 Ambari 2.7.5。
- Ambari 2.7.0 添加了以下功能:
- Ambari UI、Ambari Server 和 Ambari Agent 已经过重大修改,以更有效地处理大型集群管理
- 为了更有效地管理大型集群,更新了 AMS 架构,并改进了指标聚合。
- 更新了默认配置和配置建议,以确保 AMS 开箱即用。
- 添加了对轻松添加和管理新 HDFS 命名空间的支持。
- 添加了对管理 ViewFS 挂载表配置的支持。
- 添加了 FreeIPA 作为受支持的 KDC 实现。
- 添加了对新 Isilon 管理包的支持,可用于在现有 Isilon OneFS 上轻松安装 HDP。
- Ambari Infra Solr 现在使用 Solr 7。
- Amazon Linux 现在是受支持的部署平台。
- 常见的自定义属性现在可以在安装过程中在一处进行配置,从而更容易快速配置安装。
- 添加了团队快速查看谁发起了添加服务、添加主机、启用 HA 等操作的功能。
- 添加了团队快速查看谁执行了重新启动服务等操作的功能。
- 向部署了许多组件的大型集群添加服务时更容易找到主机。
- 添加了向多个主机批量添加和删除组件的功能。
- 添加了批量删除主机的功能。
- 在 Ambari Server 中创建了一个新的 API 门户,以快速了解和试用 Ambari API。导航到 http://ambari.server:8080/api-docs 以查看门户的文档。
- 使为 Ambari、Atlas 和 Ranger 设置 SSO 变得更加容易。
- Ambari 2.6.2 添加了以下功能:
- 保护 Zeppelin Notebook SSL 凭证
- 设置适当的 HTTP 标头以将 Cloud Object Stores 与 HDP 结合使用
- Ambari 2.6.1 添加了以下功能:
- 通过 Ambari 有条件地安装 LZO 包 (AMBARI-22457)
三、开始使用 Ambari
参考:Ambari 2.7.5的安装指南进行操作。
2.7.5编译所依赖的maven包不全,所以退了求其次选择2.7.4编译好的安装包进行部署
| 主机名 | IP地址 | 本地源服务 | 部署组件 | 大数据组件 | JDK版本 |
|---|---|---|---|---|---|
| hadoop1 | 10.10.8.11 | yum本地源 | Ambari-Server、Ambari-Agent、Nginx、MySQL | HDFS、ZK、Kafka、Hbase、YARN | jdk1.8 |
| hadoop2 | 10.10.8.12 | Ambari-Agent | HDFS、ZK、Kafka、Hive | jdk1.8 | |
| hadoop3 | 10.10.8.13 | Ambari-Agent | HDFS、ZK、Kafka、 | jdk1.8 |
软件准备(HDP-3.1.4.0是最后一个可以下载到的开源版本),使用讯雷下载
| 安装包名 | 下载地址 |
|---|---|
| ambari-2.7.4.0-centos7.tar.gz | http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.7.4.0/ambari-2.7.4.0-centos7.tar.gz |
| HDP-3.1.4.0-centos7-rpm.tar.gz | http://public-repo-1.hortonworks.com/HDP/centos7/3.x/updates/3.1.4.0/HDP-3.1.4.0-centos7-rpm.tar.gz |
| HDP-UTILS-1.1.0.22-centos7.tar.gz | http://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.22/repos/centos7/HDP-UTILS-1.1.0.22-centos7.tar.gz |
| HDP-GPL-3.1.4.0-centos7gpl.tar.gz | http://public-repo-1.hortonworks.com/HDP-GPL/centos7/3.x/updates/3.1.4.0/HDP-GPL-3.1.4.0-centos7gpl.tar.gz |
| mysql-connector-java-8.0.22.jar | https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.22/mysql-connector-java-8.0.22.jar |
3.1 配置本地 yum 源
3.1.1 配置 nginx
1 | [root@hadoop1 ~]# yum install -y nginx |
3.1.2 导入下载的镜像
1 | [root@hadoop1 ~]# cd /tmp/ambari_repo/ |
用浏览器访问nginx服务,会有如下页面
3.1.3 安装本地源工具
1 | [root@hadoop1 ambari_repo]# yum install yum-utils createrepo yum-plugin-priorities -y |
3.1.4 配置 ambari 本地源
创建本地源
1 | [root@hadoop1 ambari_repo]# createrepo ./ |
修改ambari 源
1 | [root@hadoop1 ~]# vim /etc/yum.repos.d/ambari.repo |
修改HDP 源
1 | [root@hadoop1 ~]# vim /etc/yum.repos.d/hdp.repo |
修改HDP-UTILS 源
1 | [root@hadoop1 ~]# vim /etc/yum.repos.d/hdp-utils.repo |
3.1.5 加载 yum缓存
1 | [root@hadoop1 ~]# yum clean all |
3.2 安装 ambari-server
1 | [root@hadoop1 ~]# yum -y install ambari-server |
ambari-server 默认使用内置的postgresql数据库,为了方便统一管理这里使用mysql作为数据库
建立mysql与ambari连接
1 | [root@hadoop1 ~]# cp mysql-connector-java-8.0.22.jar /usr/share/java/mysql-connector-java.jar |
配置MySQL ambari用户
1 | mysql> create database ambari; |
配置ambari-server
1 | [root@hadoop1 ~]# ambari-server setup |
注意:WARNING 处提示需要将路径
/var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql的sql导入到ambari服务使用的库中
设置ambari-server的mysql驱动路径
1 | [root@hadoop1 ~]# ambari-server setup --jdbc-db=mysql --jdbc-driver=/usr/share/java/mysql-connector-java.jar |
启动ambari-server
1 | [root@hadoop1 ~]# ambari-server start |
启动完后使用浏览器访问ambari地址: http://ip:8080/ ,默认用户 admin/admin
3.3 安装 ambari-agent
在需要运行hadoop集群的服务器上安装ambari-agent(在后面部署hadoop的时候可以自动在节点安装agent,所以这一步是非必要的)
1 | [root@hadoop1 ~]# yum install ambari-agent -y |
到这里Ambari平台就安装完了
如果想更改配置信息
停止
ambari-server stop重置
ambari-server reset重新设置
ambari-server setup
四、部署 Hadoop 集群
接下来部署和运行集群使用hadoop用户
在所有hadoop服务器上创建hadoop运行用户
1 | [root@hadoop1 ~]# groupadd hadoop |
配置hosts解析或内网DNS
1 | [hadoop@hadoop1 ~]$ sudo vim /etc/hosts |
配置SSH免密登录
1 | [hadoop@hadoop1 ~]$ ssh-keygen |
所有hadoop服务器配置JDK环境,这里的JDK环境变量是配置在hadoop用户下的
1 | [hadoop@hadoop1 ~]$ tar xf downloads/jdk-8u301-linux-x64.tar.gz |
重新打开终端或切换hadoop用户使环境变量生效
4.1 使用安装向导创建集群
访问ambari地址: http://ip:8080/ ,使用安装向导创建集群
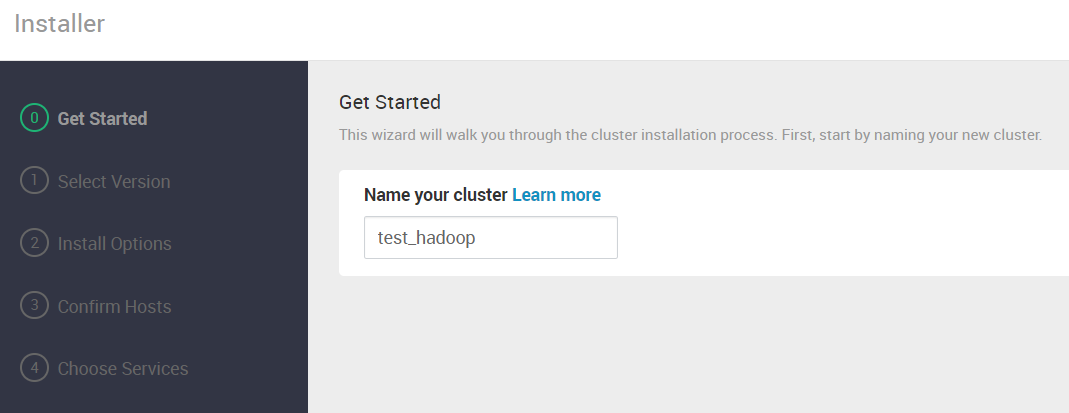
4.2 输入集群名称
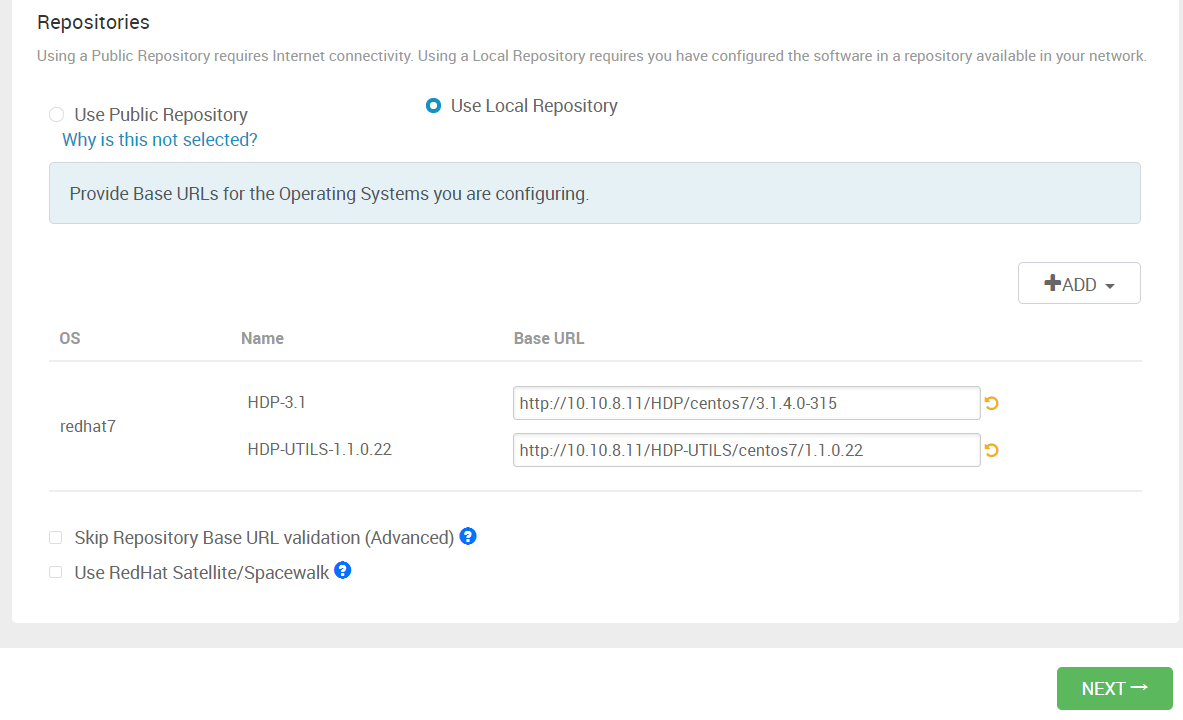
4.3 选择 hadoop 集群版本
选择hadoop集群版本,也可以自己下载离线包上传

我这里使用的centos7系统,本地库只保留一个redhat7的配置,并将yum源文件中的hdp和hdp-utils地址复制过来
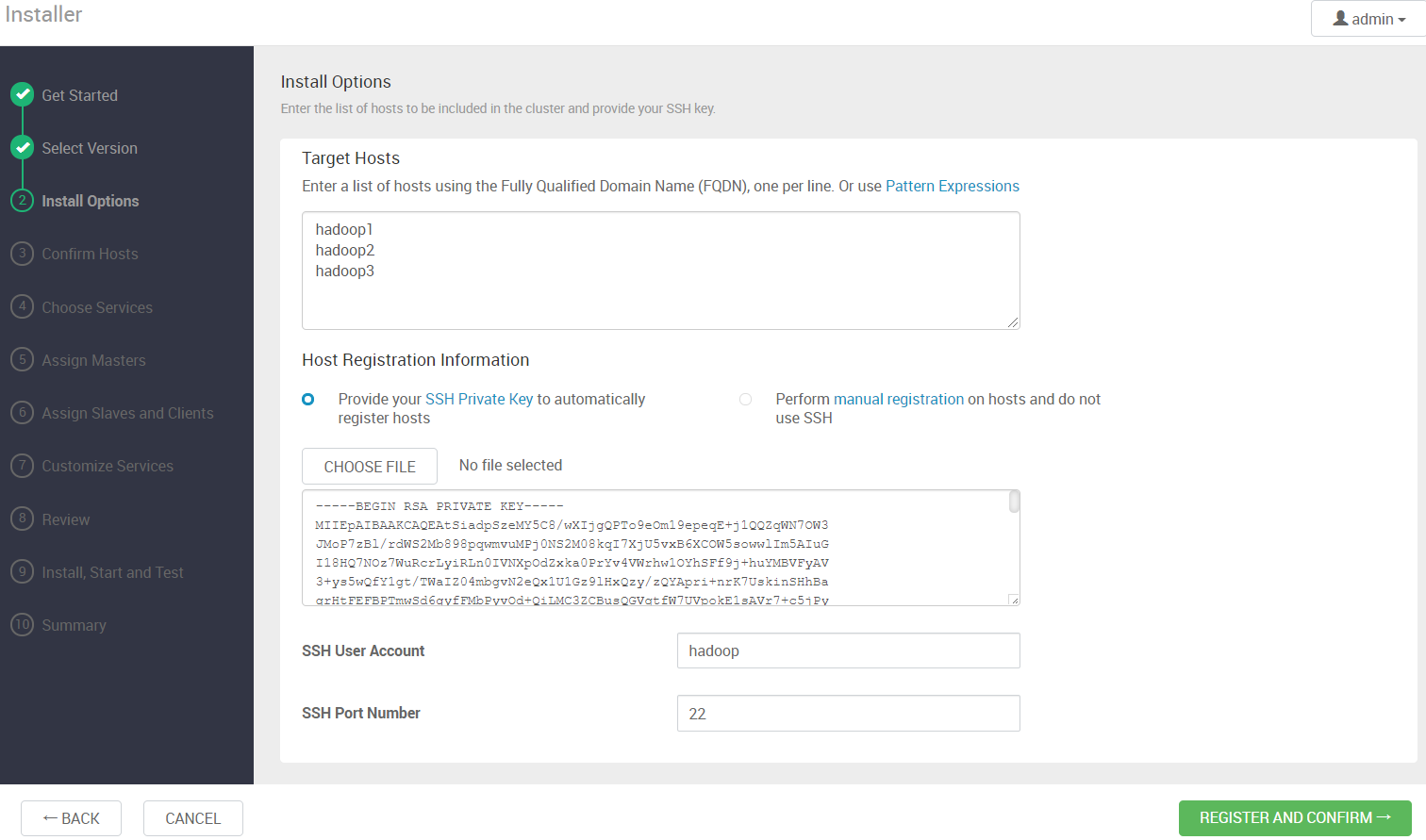
4.4 添加 hadoop 节点
添加hadoop节点主机名,并上传密钥(先做好免密登录,这里使用的是hadoop用户)
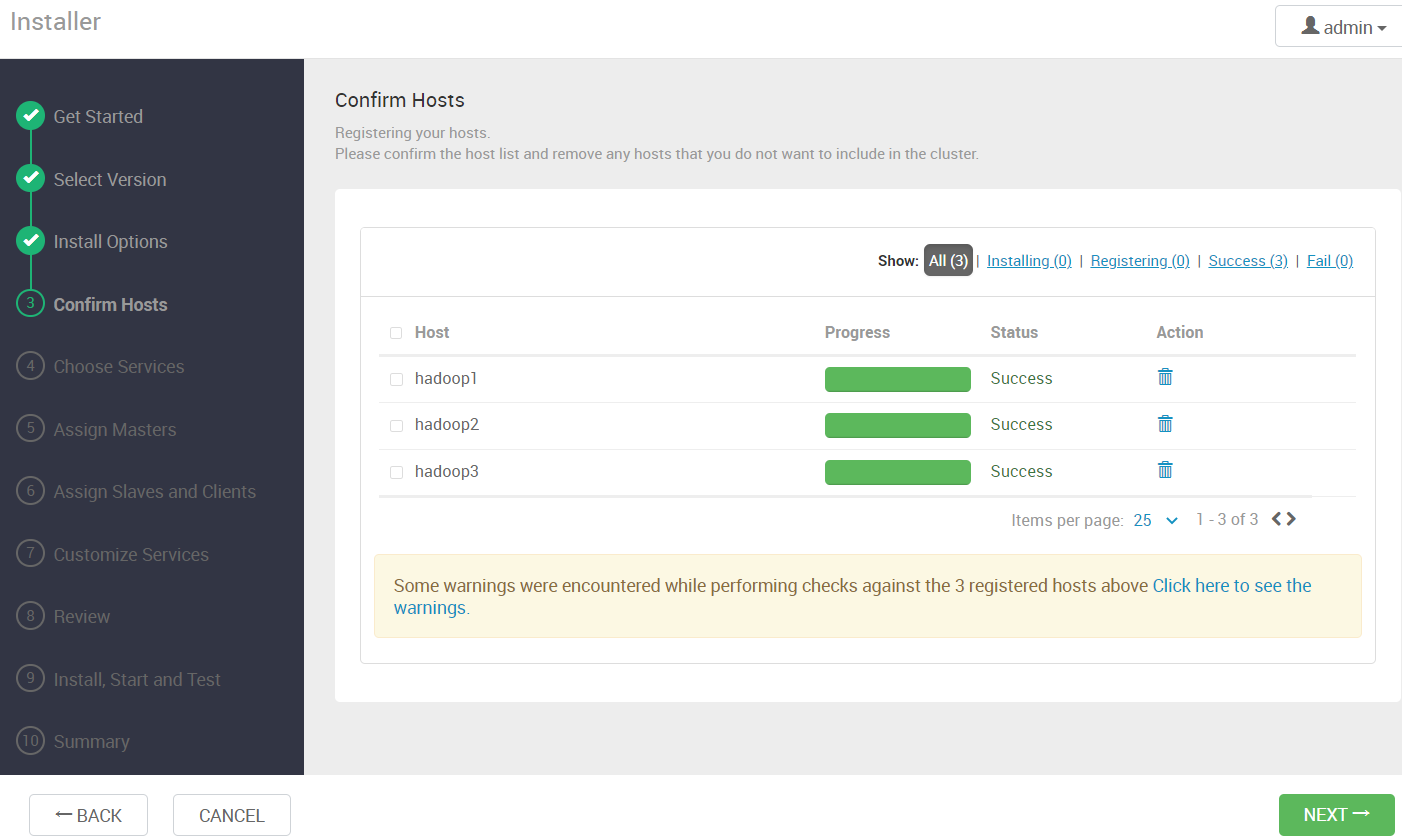
4.5 等待安装完成
等待 ambari-agent 安装完成
4.6 安装大数据组件
选择需要的大数据组件进行安装
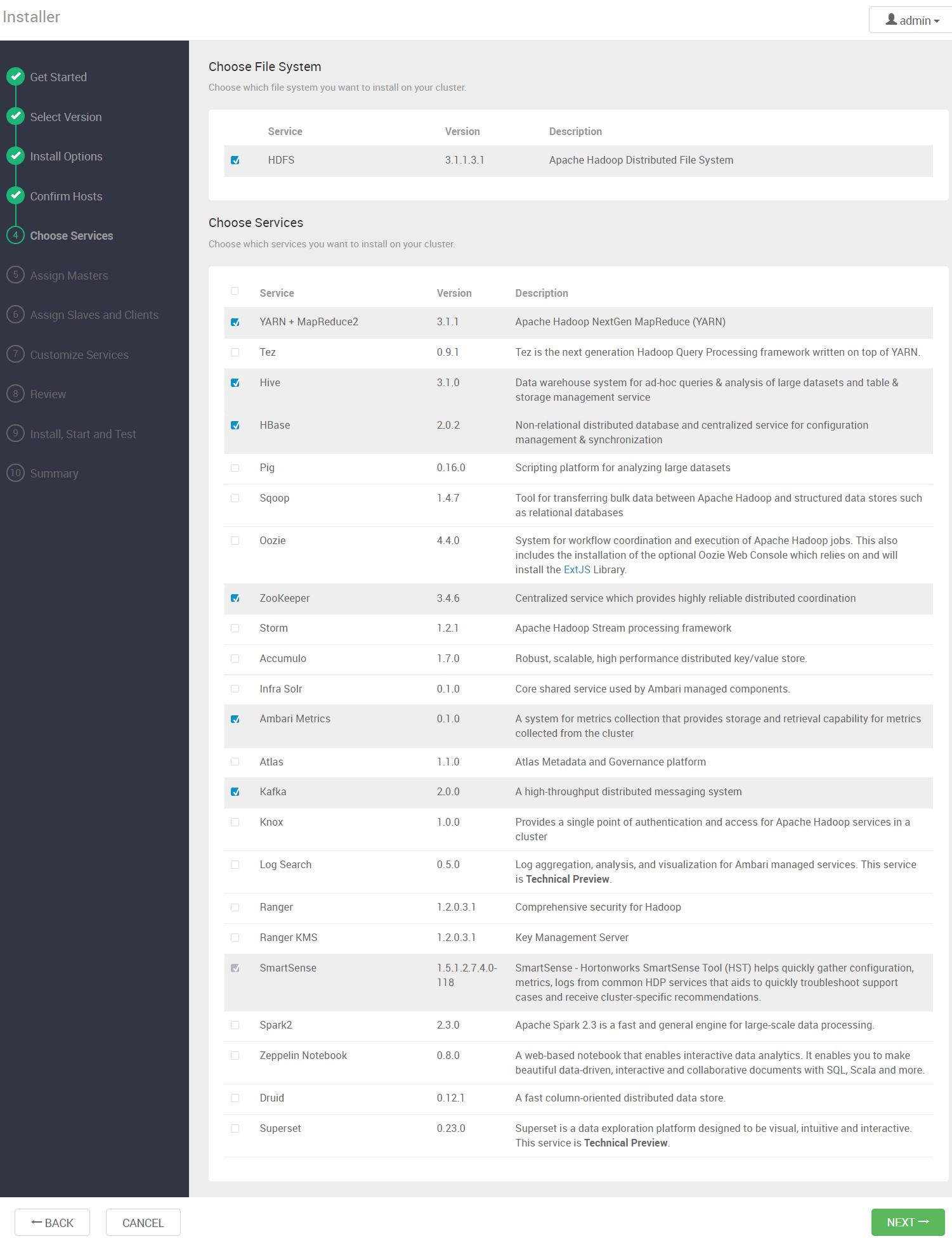
4.7 分配大数据组件
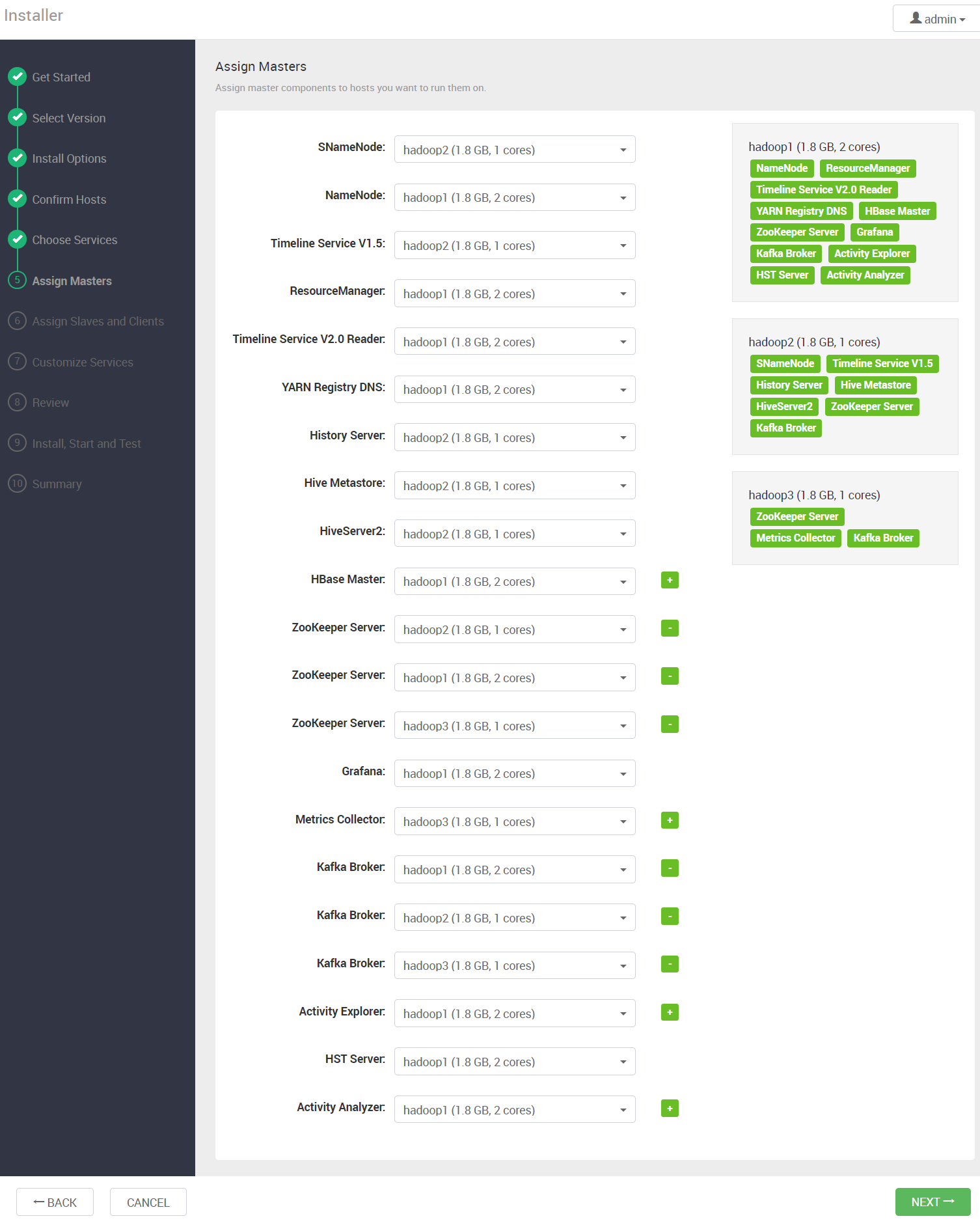
4.8 配置节点的角色
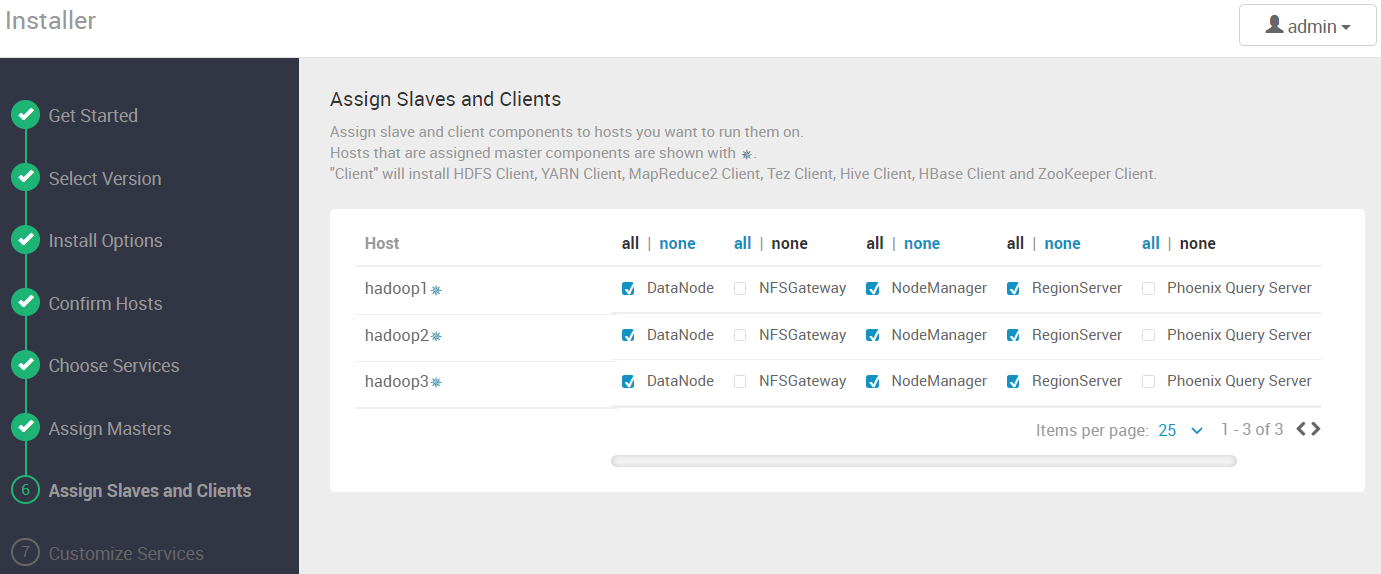
4.9 帐号密码配置
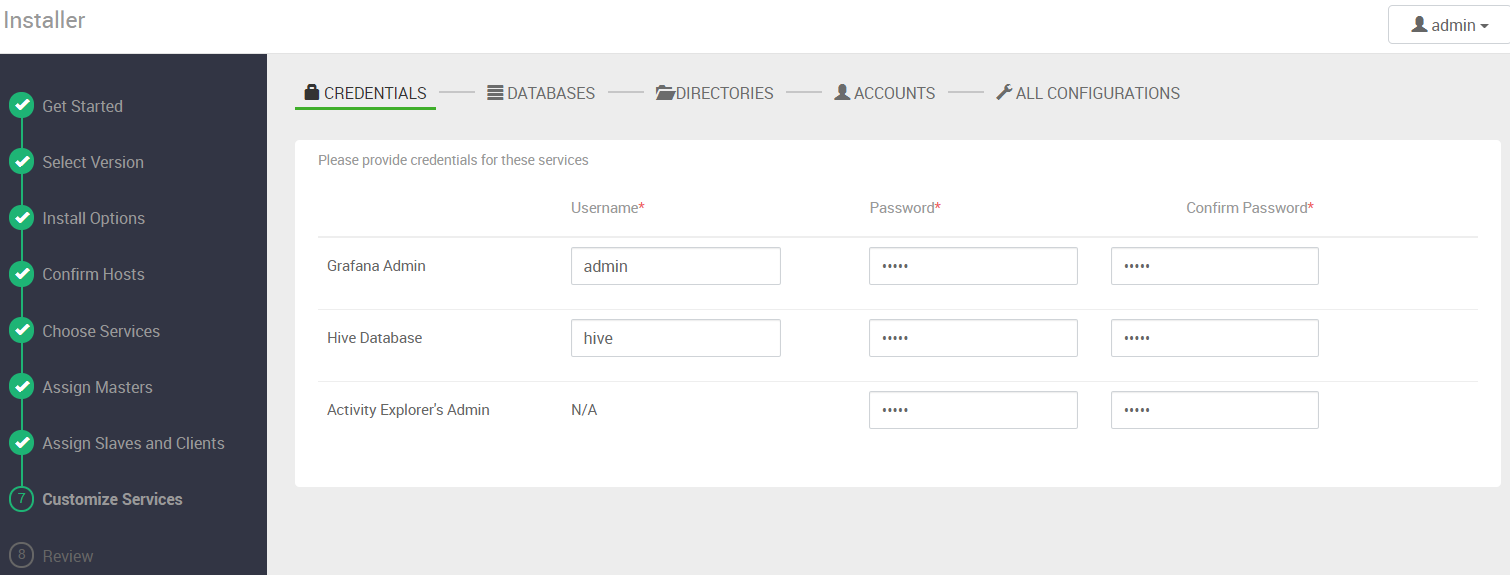
如果添加了hive组件,需要配置数据库连接,注意数据库地址
1 | #mysql数据库添加hive用户权限 |
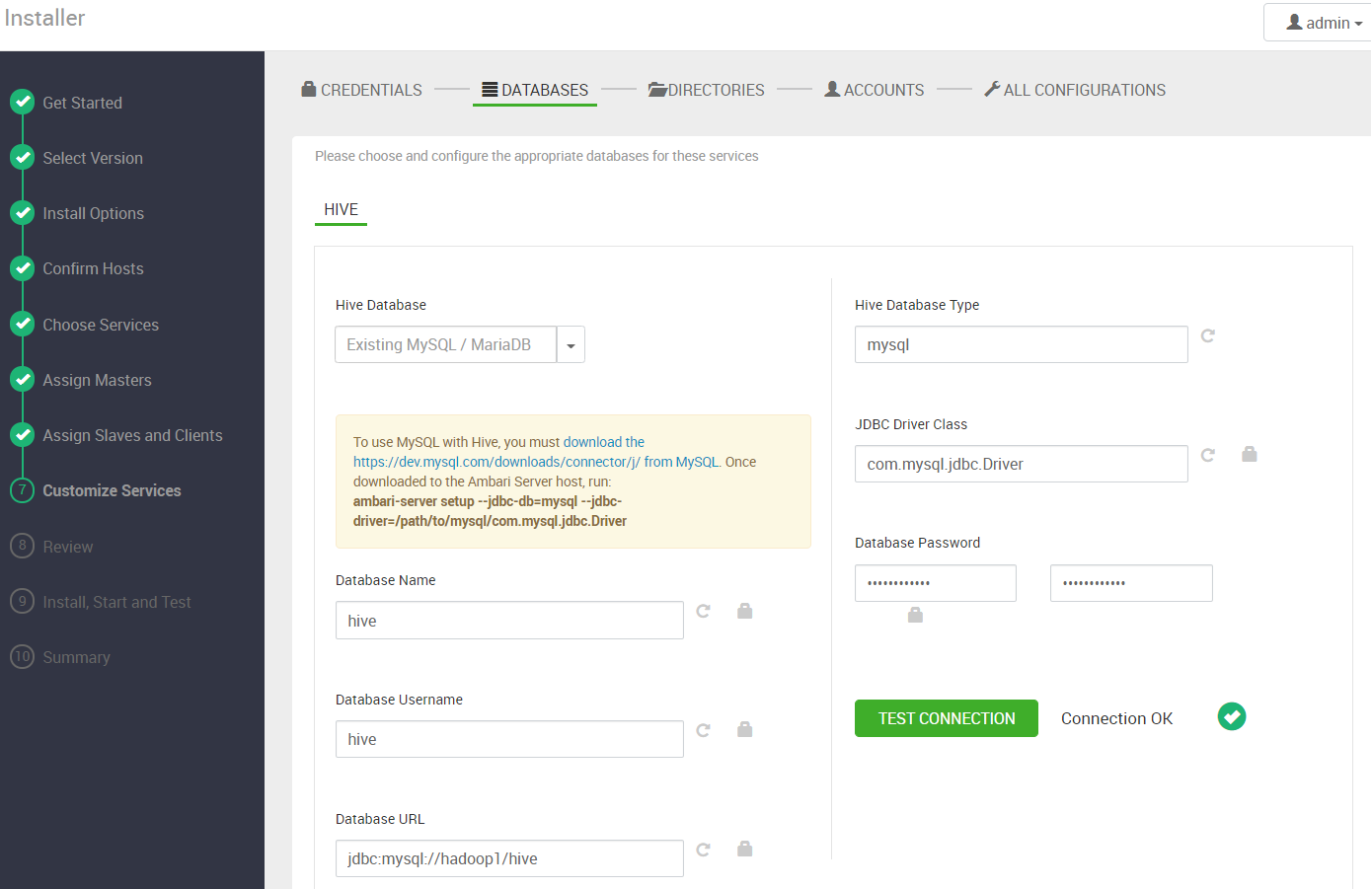
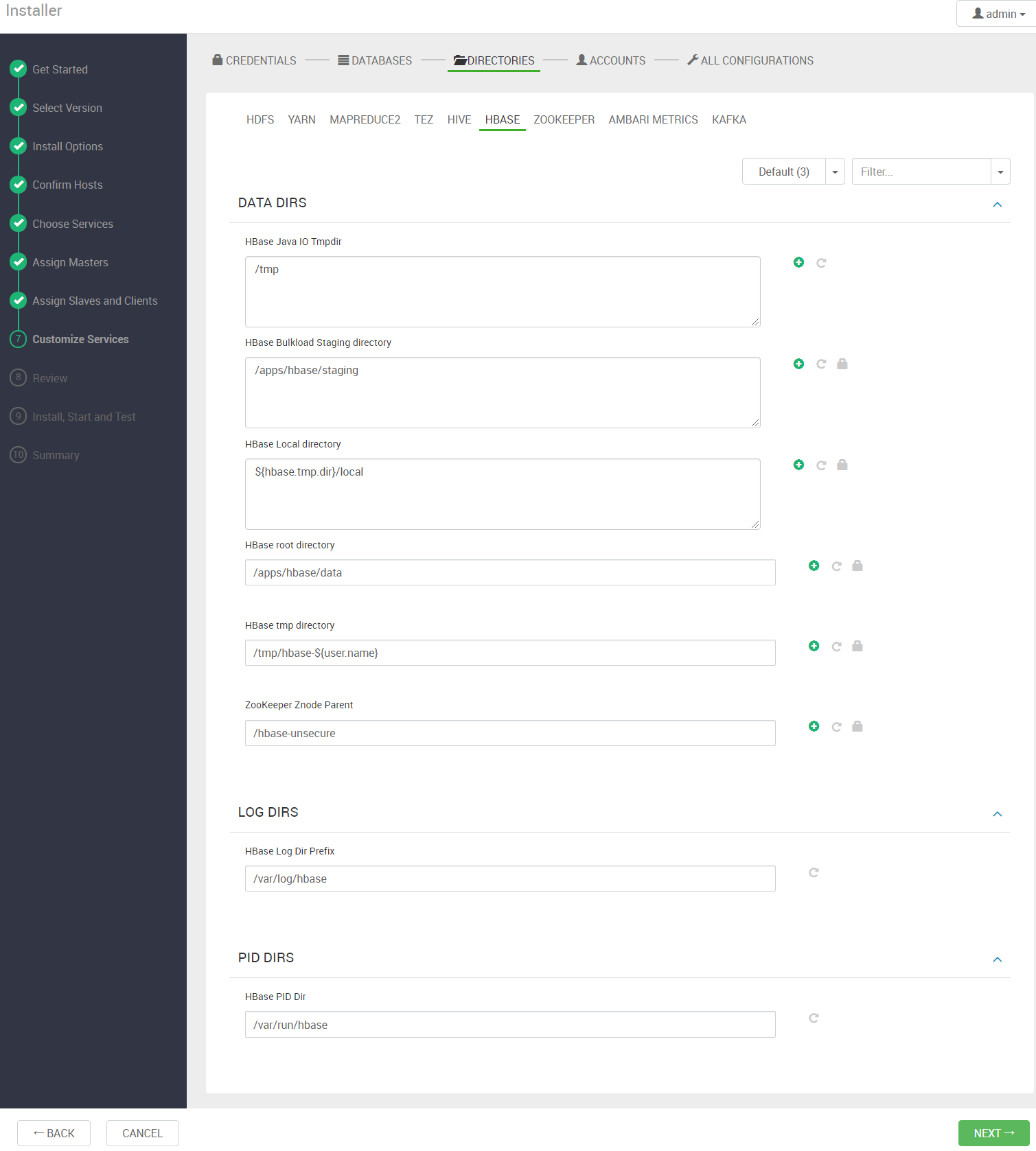
配置大数据相关存储目录,这个根据实际环境进行调整应使用单独的磁盘
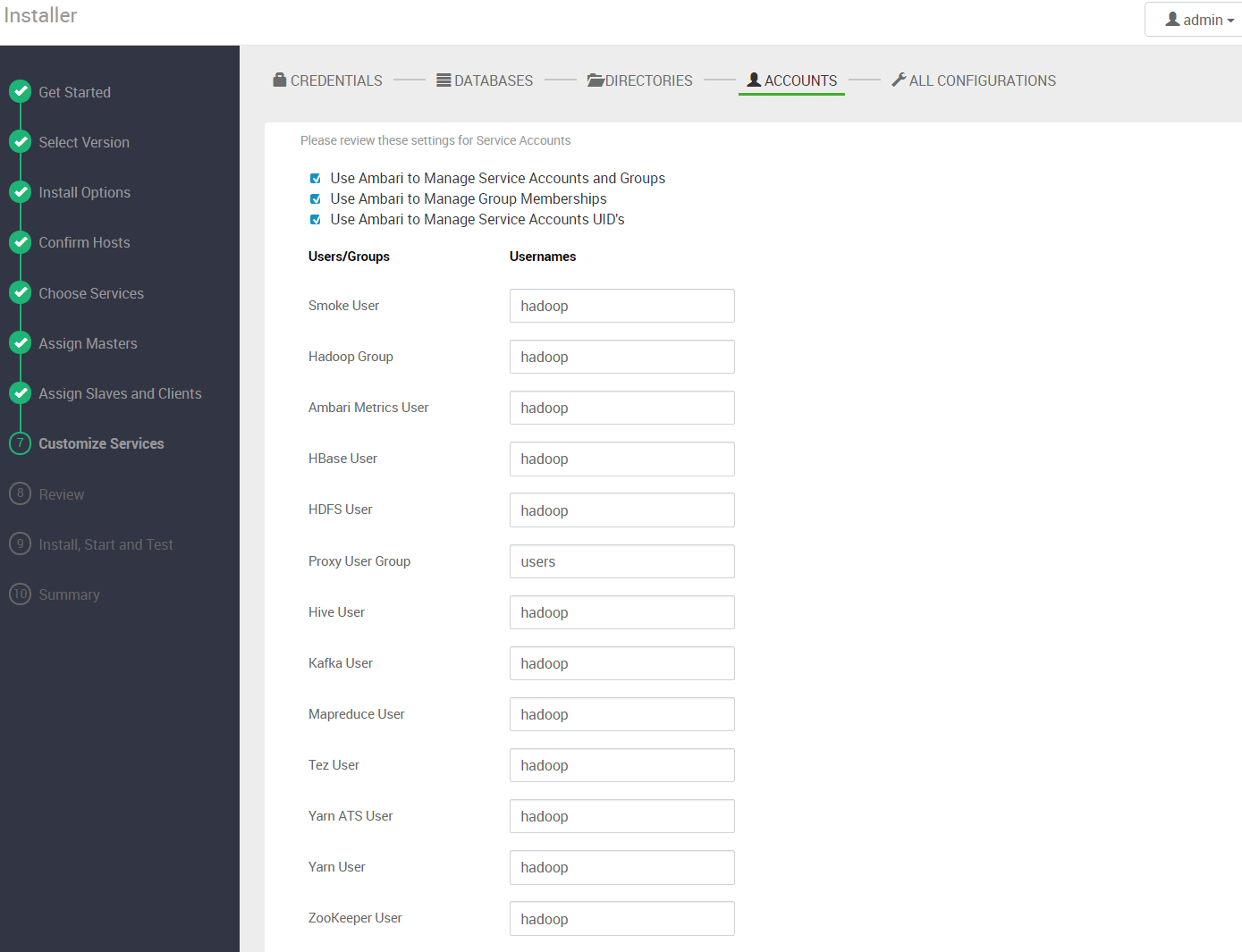
服务运行用户配置,默认会为每个服务创建以服务名为代表的用户,并使用该用户启动服务,如果想统一运行用户可以将 Username 改为你需要的用户
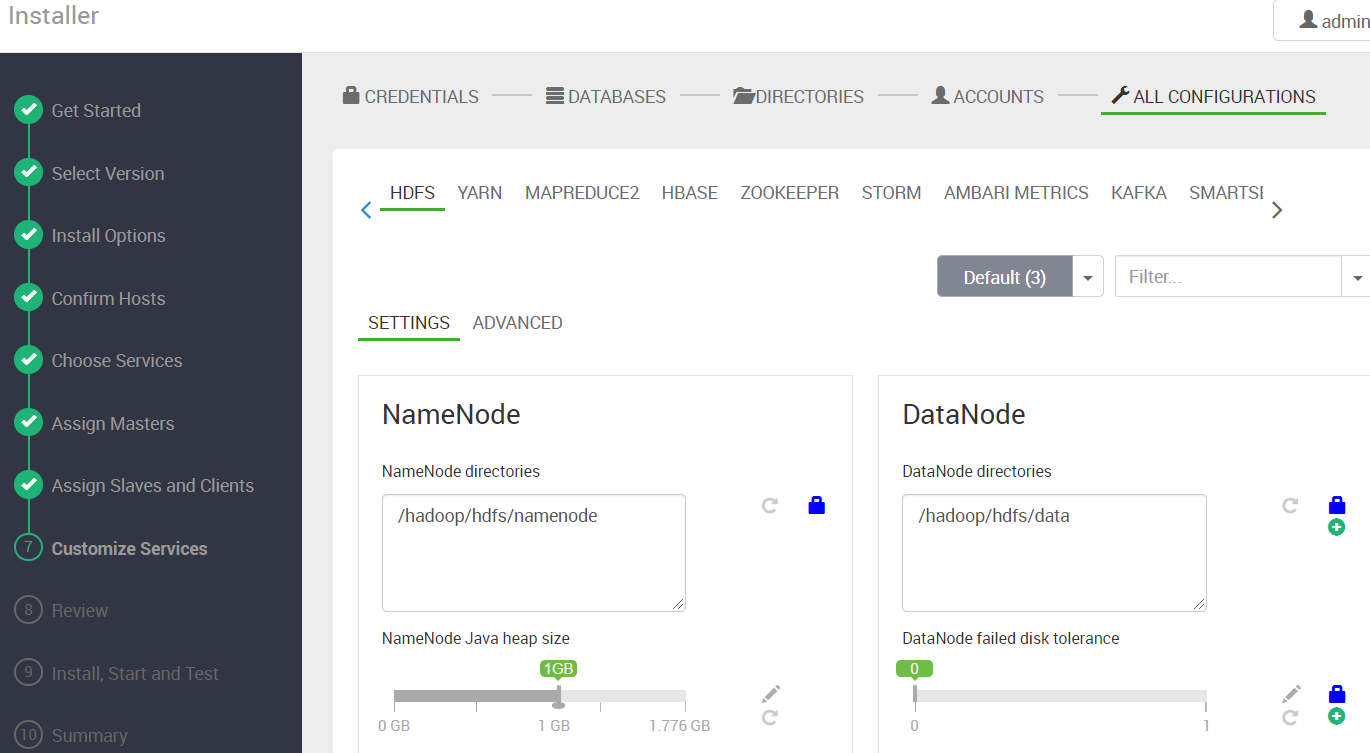
存储路径和内存配置
4.10 开始部署
将配置信息都确认完后,便可以开始部署了
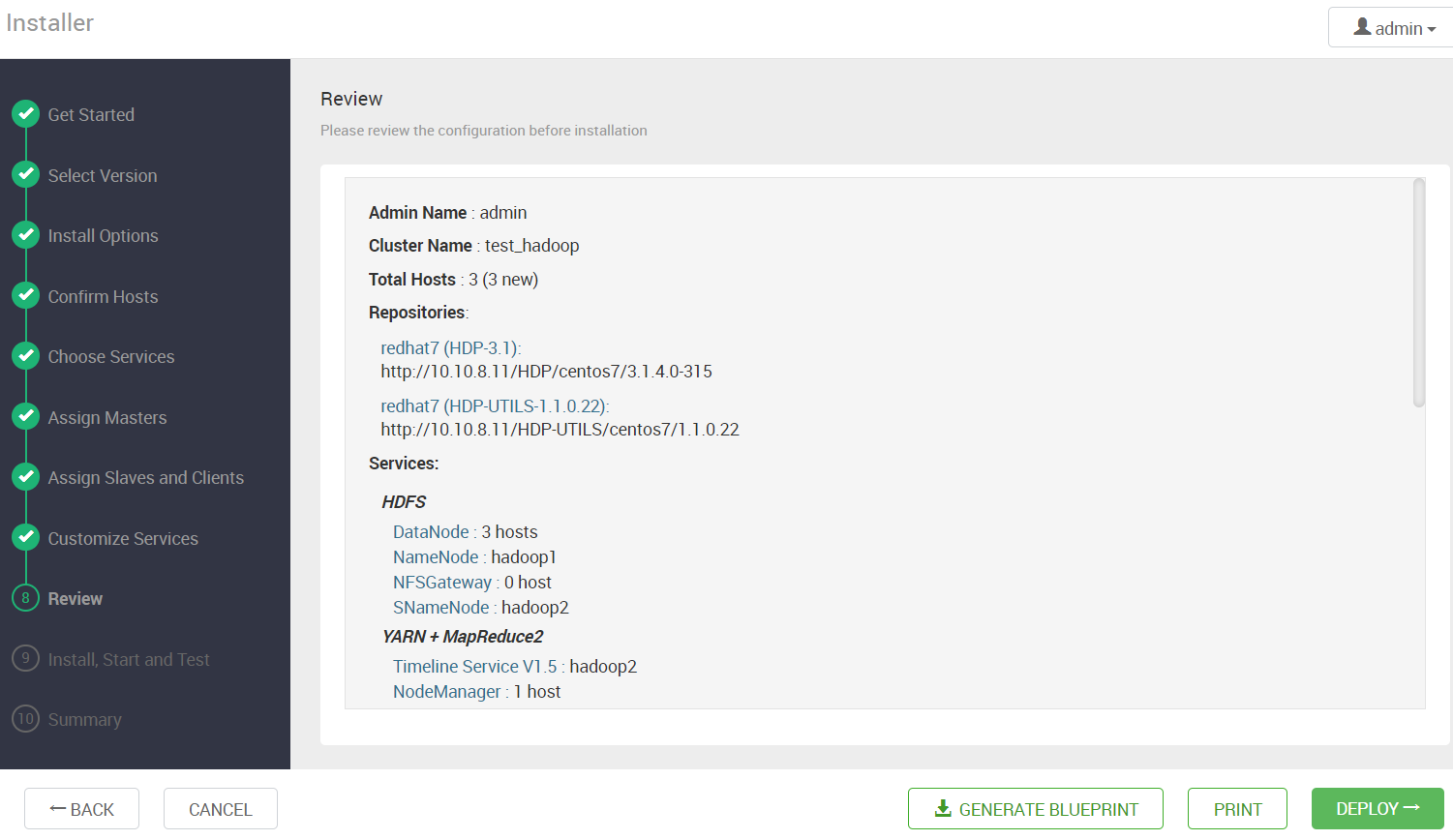
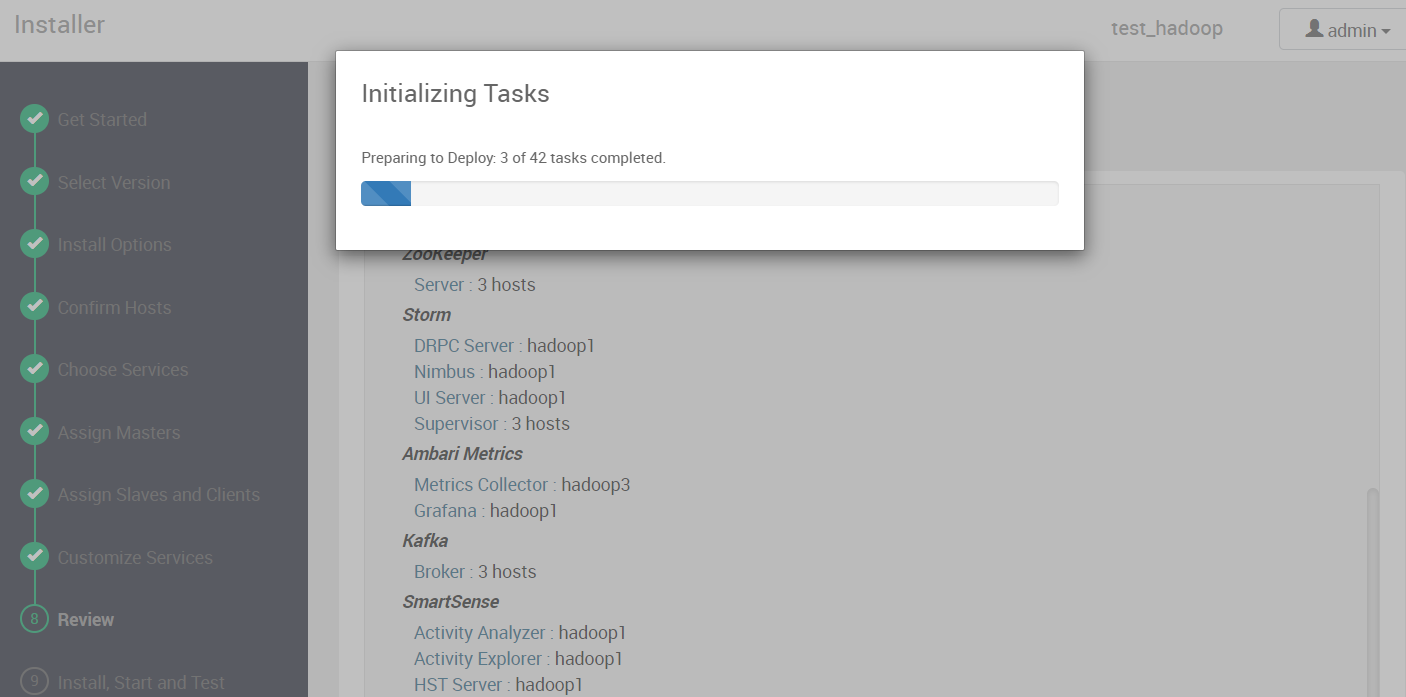
等待部署完成
如果结果显示有黄色警告,配置已经成功了,只是由于某个服务没有正常启动导致的。
4.11 启动集群
部署完后就可以通过ambari管理hadoop集群了
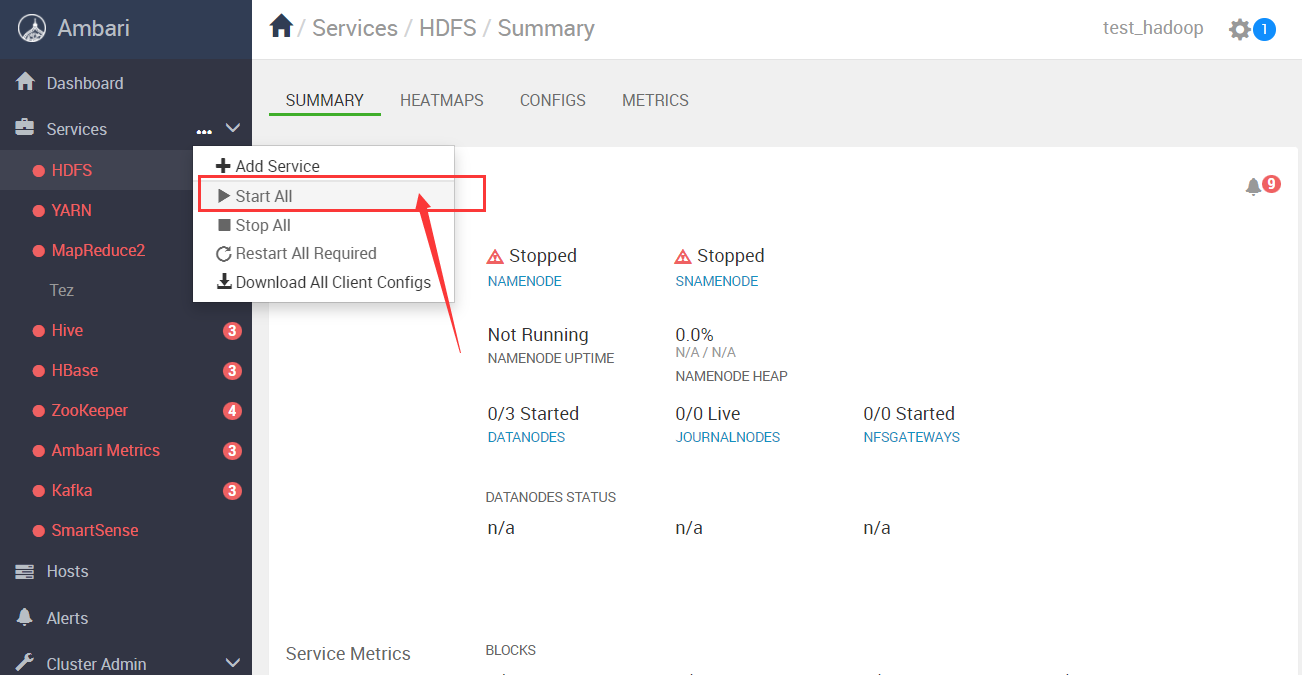
4.12 可能遇到的问题
集群启动过程中可能遇到的问题
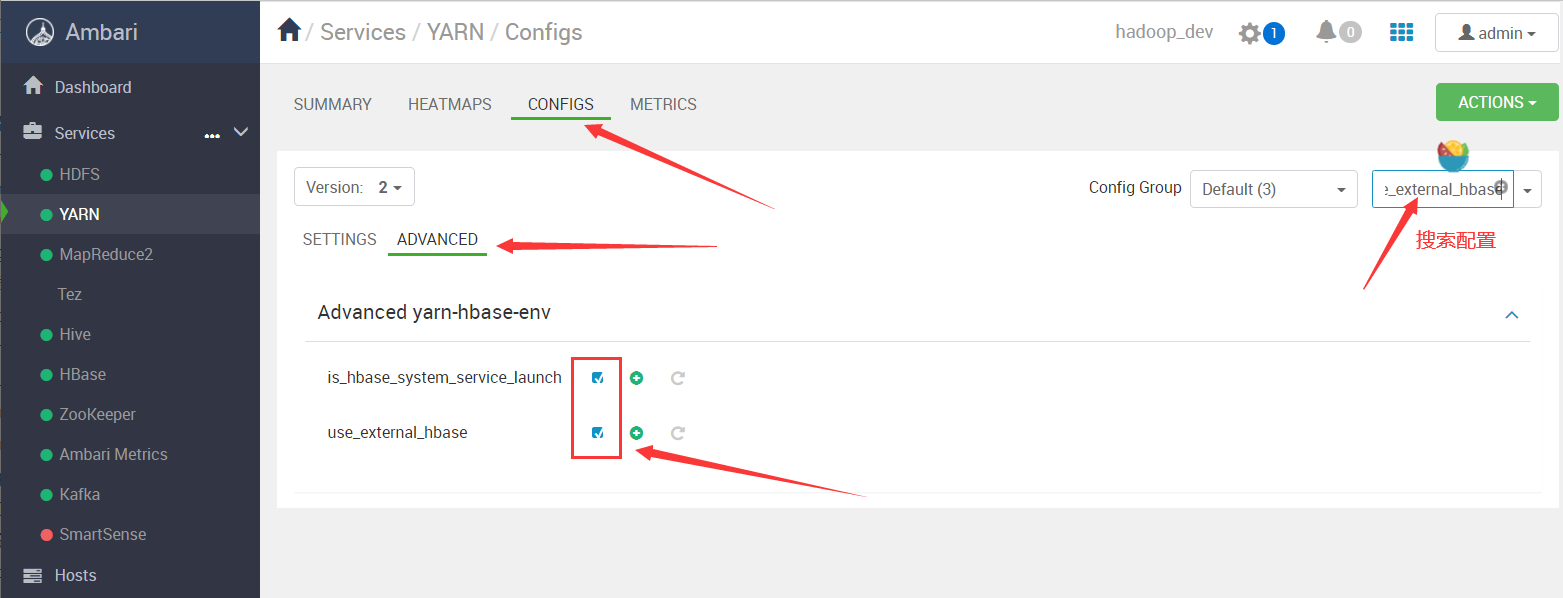
Timeline Service V2.0 Reader 无法启动
报错:
resource_management.core.exceptions.ExecuteTimeoutException: Execution of 'ambari-sudo.sh su hadoop -l -s /bin/bash -c 'export PATH='"'"'/usr/sbin:/sbin:/usr/lib/ambari-server/*:/usr/sbin:/sbin:/usr/lib/ambari-server/*:/root/jdk1.8.0_301/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/downloads/apache-maven-3.6.3/bin:/root/bin:/var/lib/ambari-agent:/var/lib/ambari-agent'"'"'; sleep 10;export HBASE_CLASSPATH_PREFIX=/usr/hdp/3.1.4.0-315/hadoop-yarn/timelineservice/*; /usr/hdp/3.1.4.0-315/hbase/bin/hbase --config /usr/hdp/3.1.4.0-315/hadoop/conf/embedded-yarn-ats-hbase org.apache.hadoop.yarn.server.timelineservice.storage.TimelineSchemaCreator -Dhbase.client.retries.number=35 -create -s'' was killed due timeout after 300 seconds
解决方法:
勾选yarn配置文件中的 is_hbase_system_service_launch 和 use_external_hbase 选项,并重启服务