一、前言
在 Hadoop 1.X版本中,NameNode会是整个HDFS集群的单点故障(single point of failure,SPOF):每一个HDFS集群只能有一个NameNode节点,一旦NameNode所在服务器宕机或者出现故障将导致整个集群都不可用,除非重启或者开启一个新的Namenode集群才能够恢复可用。
NameNode单点故障对HDFS集群的可用性产生影响主要表现在以下两种情况:
当NameNode所在服务器发生未知的异常(例如:服务器宕机)时,在NameNode被重新启动之前整个集群都将不可用。
当NameNode所在服务器执行某些日常维护任务(例如:软件或硬件升级)重启服务器时,同样会导致HDFS集群在一段时间内不可用。
二、HDFS 高可用原理
在Hadoop 2.X 版本中,HDFS引入了双NameNode架构,HA(High Available)通过将两个NameNode分别配置为Active/Passive状态来解决上述问题。处于Active状态的NameNode叫作Active Namenode,处于Passive状态的NameNode叫作Standby Namenode。 Standby Namenode作为Active Namenode的热备份,能够在NameNode发生故障或者由于日常服务器维护需要重启的时候以一种优雅的方式自动切换为Active Namenode。
基于ZK的HDFS高可用架构如下所示:
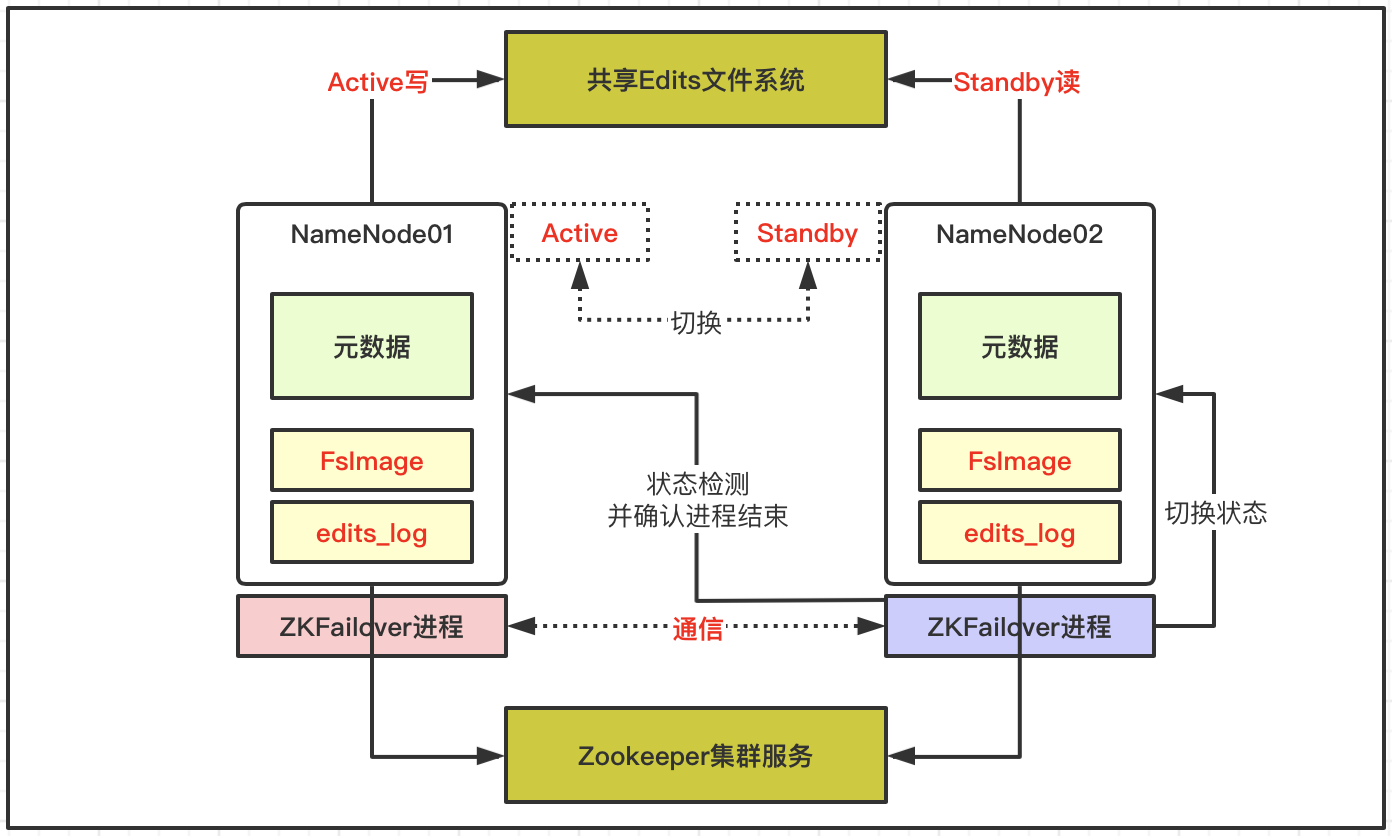
- 基于两个NameNode做高可用,依赖共享Edits文件和Zookeeper集群;
- 每个NameNode节点配置一个ZKfailover进程,负责监控所在NameNode节点状态;
- NameNode与ZooKeeper集群维护一个持久会话;
- 如果Active节点故障停机,ZooKeeper通知Standby状态的NameNode节点;
- 在ZKfailover进程检测并确认故障节点无法工作后;
- ZKfailover通知Standby状态的NameNode节点切换为Active状态继续服务;
ZooKeeper在大数据体系中非常重要,协调不同组件的工作,维护并传递数据,例如上述高可用下自动故障转移就依赖于ZooKeeper组件。
三、HDFS 高可用配置
3.1 搭建 hadoop 集群
搭建集群和上一篇 Hadoop 2.7.2 手动部署 一样,这里就不重复了
3.2 服务规划
| 服务器 | IP地址 | 部署组件 | 高可用组件 |
|---|---|---|---|
| hadoop1 | 10.10.8.11 | namenode、datanode | JournalNode、zookeeper、DFSZKFailoverController |
| hadoop2 | 10.10.8.12 | namenode、datanode | JournalNode、zookeeper、DFSZKFailoverController |
| hadoop3 | 10.10.8.13 | datanode | JournalNode、zookeeper |
3.3 添加 HA 配置
在上述Hadoop集群搭建完成之后,若要启用HA还需要对hdfs-site.xml和core-site.xml两个文件进行一点额外的配置。
在 HDFS-HA 集群中,使用 [nameservice ID] 来唯一识别一个 HDFS 实例,一个 HDFS-HA 集群可以含有多个(目前最多只支持两个)NameNode,集群同时又使用了 [name node ID] 来识别每一个NameNode。因此,在HDFS-HA 集群中,NameNode 的配置参数都以[nameservice ID].[name node ID]为后缀的。由于dfs.nameservices和dfs.ha.namenodes.[nameservice ID]两个配置项的值将决定后面一些配置项的名称,所以建议先配置这两个选项的值。
在本文中,[nameservice ID]=mycluster,两个[name node ID]分别为nn1和nn2,名称可以随意取,只需要保持前后一致即可。
修改 hdfs-site.xml 配置 ,在原有配置基础上增加以下有关HA配置
1 | <!-- 设置namenode存放的路径 --> |
修改 core-site.xml 配置
1 | <property> |
将修改的配置文件拷贝到其它hadoop服务器上
1 | [hadoop@hadoop1 ~/hadoop-2.7.2/etc/hadoop]$ scp core-site.xml hdfs-site.xml hadoop@hadoop2:~/hadoop-2.7.2/etc/hadoop/ |
3.4 同步 NameNode
3.4.1 启动 JournalNodes
在 JournalNodes 所在的机器上分别启动 JournalNode 进程
1 | [hadoop@hadoop1 ~/hadoop-2.7.2/sbin]$ ./hadoop-daemon.sh start journalnode |
3.4.2 同步 NameNodes
如果集群还没有进行格式化,可以使用 hdfs namenode -format 命令格式化后再进行同步
1 | #先启动nn1的namenode |
3.4.3 启动 nn2 NameNode
1 | [hadoop@hadoop2 ~/hadoop-2.7.2/sbin]$ ./hadoop-daemon.sh start namenode |
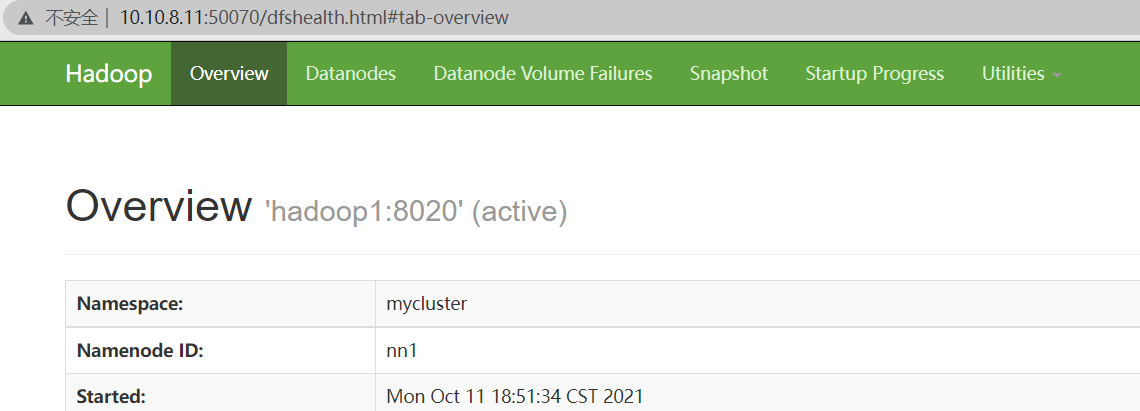
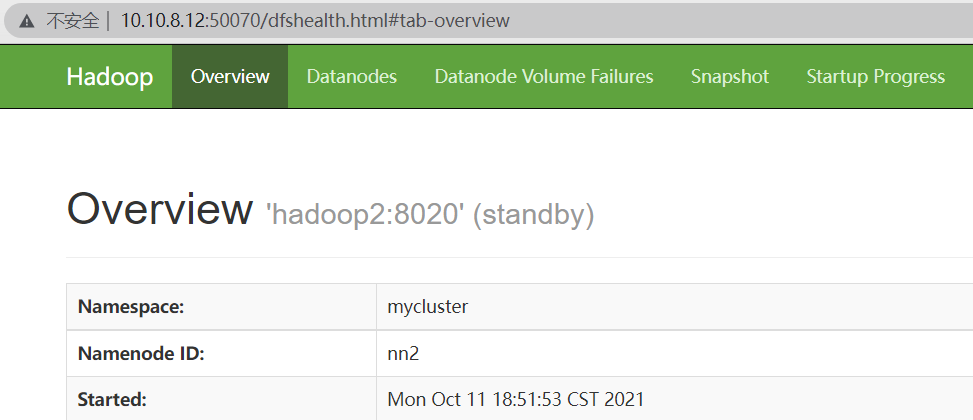
所有NameNode都启动后,访问它们的管理界面查看各NameNode状态
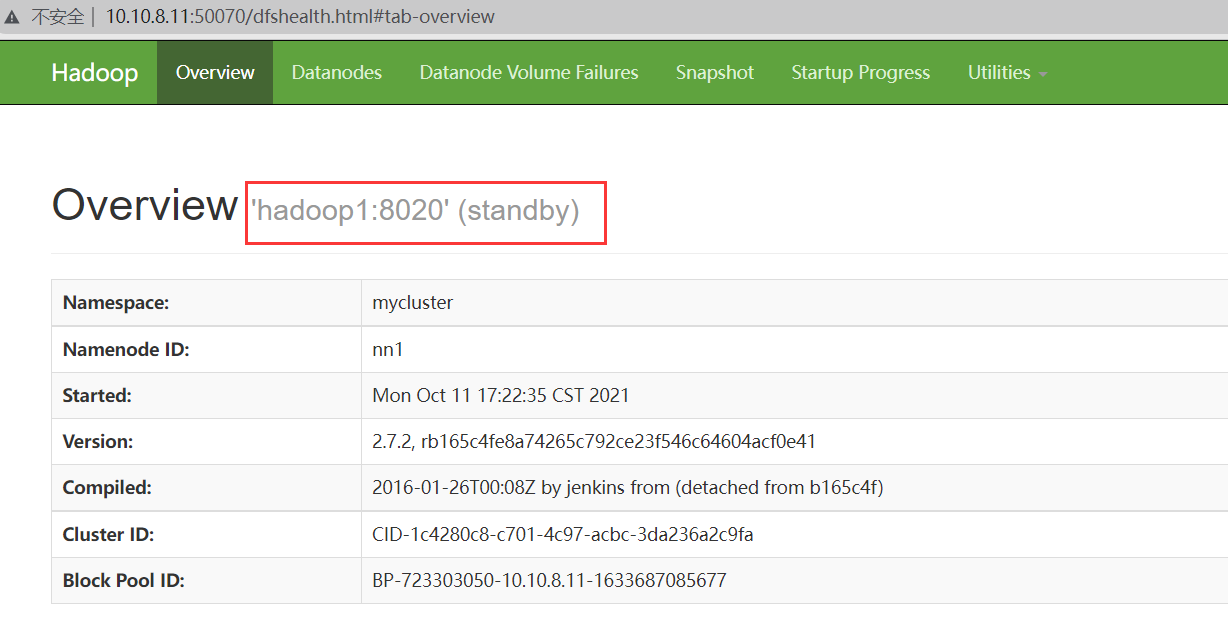
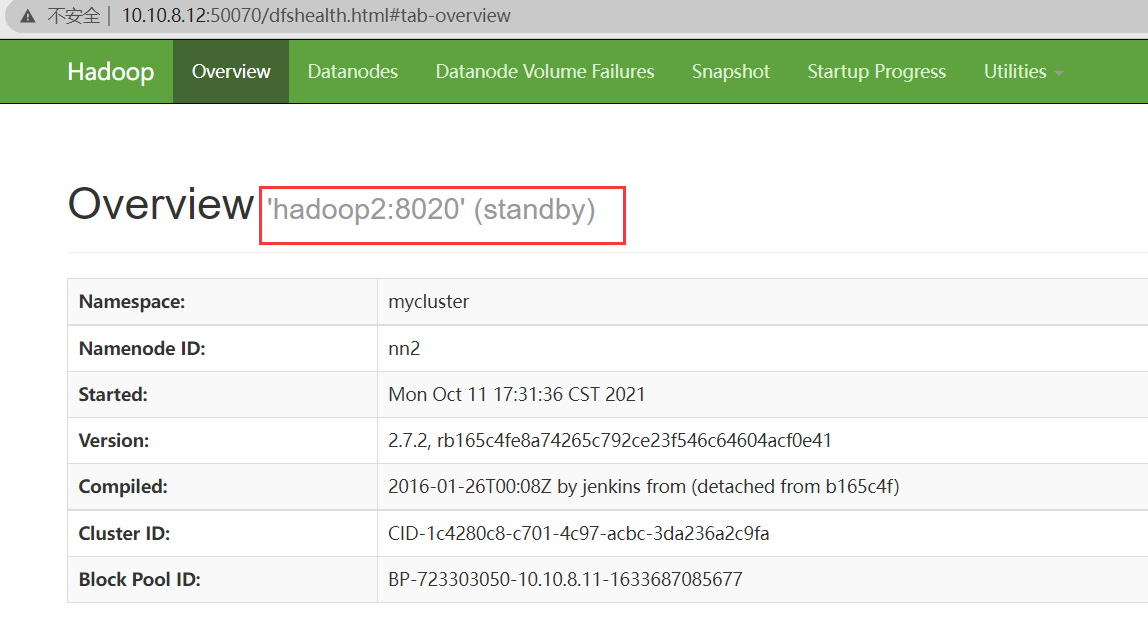
如图所示,按照上述配置启动的HA NameNode 都是Standby状态,需要使用 hdfs haadmin 管理命令将其中的一个切换为Active状态。
注:在HA集群环境里,备用的namenode还起到了检测命名空间状态的作用,因此就没有必要在集群中再运行Secondary NameNode、CheckpointNode和BackupNode了。
3.5 手动切换 Active 状态
启动集群后可以通过 hdfs haadmin 来查看HA NameNode管理命令的用法
| 命令 | 描述 |
|---|---|
| -transitionToActive | 转换指定NameNode 的状态为Acitve |
| -transitionToStandby | 转换指定NameNode 的状态为Standby |
| -failover | 在两个NameNode 之间启动一次故障转移 |
| -getServiceState | 查看指定NameNode 的状态,Acitve或者Standby |
| -checkHealth | 检查指定NameNode 的健康状态 |
将nn1切换为Active状态
1 | [hadoop@hadoop1 ~/hadoop-2.7.2/sbin]$ hdfs haadmin -transitionToActive nn1 |
再次访问管理界面查看各NameNode状态
四、ZK 实现 NN 自动故障转移
4.1 部署 zookeeper
在3台服务器上执行以下命令,配置zookeeper集群
1 | [hadoop@hadoop1 ~]$ https://archive.apache.org/dist/zookeeper/zookeeper-3.4.8/zookeeper-3.4.8.tar.gz |
为3台zk分别创建ServerID标识
1 | [hadoop@hadoop1 ~/zookeeper-3.4.8]$ echo 1 > data/myid |
启动zk集群
1 | [hadoop@hadoop1 ~/zookeeper-3.4.8]$ ./bin/zkServer.sh start |
查看zk节点状态
1 | [hadoop@hadoop1 ~/zookeeper-3.4.8]$ ./bin/zkServer.sh status |
集群中当前hadoop1上的zk成为leader节点
4.2 配置自动故障转移
修改 hdfs-site.xml 配置文件,增加如下配置
1 | <property> |
修改 core-site.xml 配置文件,增加如下配置
1 | <property> |
4.3 初始化 HA 在 ZK 中状态
关闭所有HDFS服务,在hadoop1上执行(因为配置了免密,可以启动/关闭所有节点的hdfs服务)
1 | [hadoop@hadoop1 ~/hadoop-2.7.2/sbin]$ ./stop-dfs.sh |
初始化HA在Zk中状态
1 | [hadoop@hadoop1 ~/hadoop-2.7.2/sbin]$ hdfs zkfc -formatZK |
成功了会提示:Successfully created /hadoop-ha/mycluster in ZK.
4.4 启动 HDFS 集群
在hadoop1上启动HDFS服务
1 | [hadoop@hadoop1 ~/hadoop-2.7.2/sbin]$ ./start-dfs.sh |
默认在哪个主机先启动DFSZK Failover Controller,那个主机NameNode就是Active NameNode
也可以在各个NameNode节点上手动启动DFSZK Failover Controller
sbin/hadoop-daemons.sh start zkfc
4.5 验证 NN 自动故障转移
先查看当前 NameNode 状态
1 | [hadoop@hadoop1 ~/hadoop-2.7.2/sbin]$ hdfs haadmin -getServiceState nn1 |
现在NN1是active,将hadoop1上的NameNode进程停掉
1 | [hadoop@hadoop1 ~/hadoop-2.7.2/sbin]$ jps |
再次查看 NameNode 状态
1 | [hadoop@hadoop1 ~/hadoop-2.7.2/sbin]$ hdfs haadmin -getServiceState nn2 |
可以看到NN2已经变成了active状态
如果在测试过程中发现 kill NameNode 后,状态并没有自动切换,查看zkfc日志${HADOOP_HOME}/logs/hadoop-hadoop-zkfc-hadoop2.log有如下错误:
1 | 2021-10-12 15:08:50,712 WARN org.apache.hadoop.ha.FailoverController: Unable to gracefully make NameNode at hadoop2/10.10.8.12:8020 standby (unable to connect) |
这是因为没有 fuster 程序,导致无法进行 fence,需要在NN服务器上安装包含fuster程序的软件包psmisc
1 | # yum -y install psmisc |
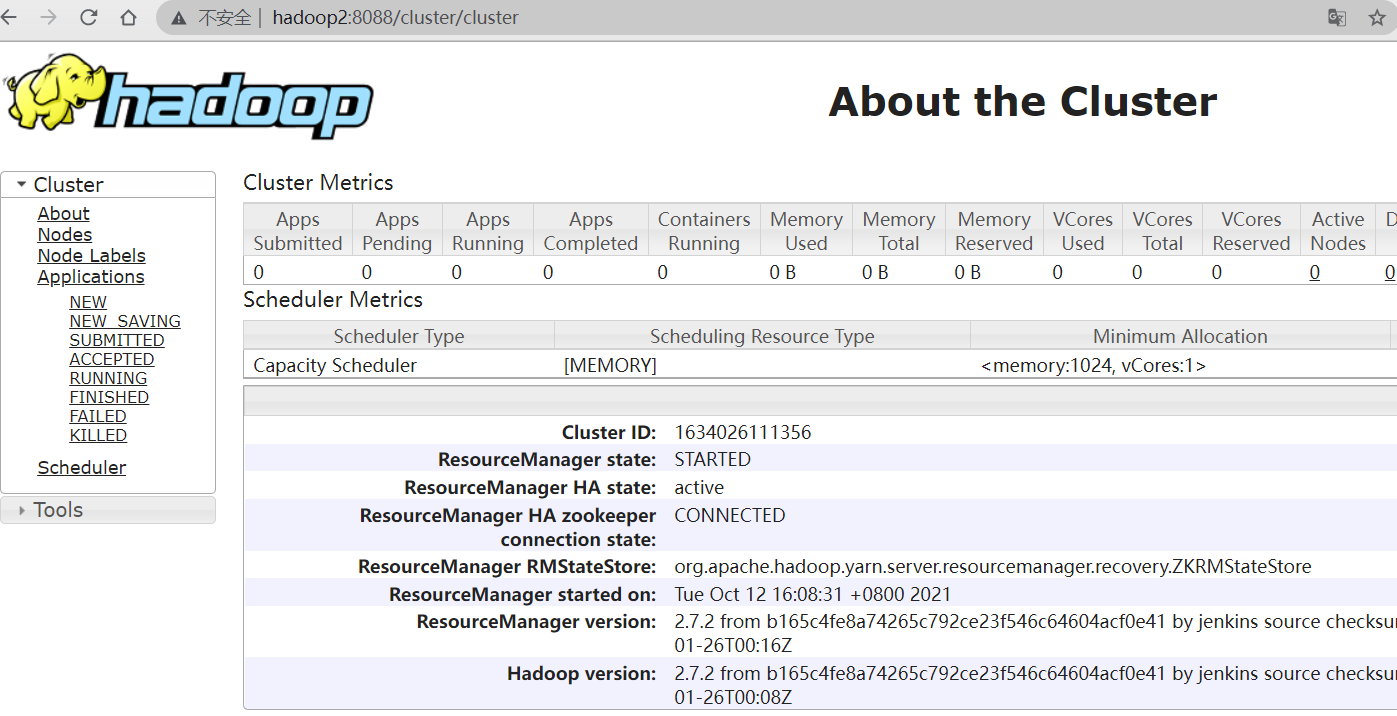
五、YARN 高可用
5.1 YARN 高可用架构
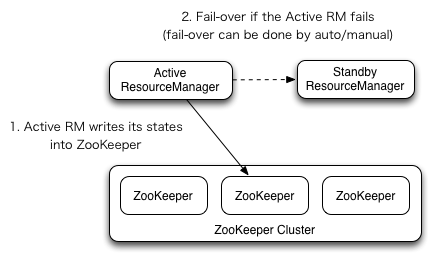
ResourceManager HA通过一个主从架构实现在任意时刻,总有一个RM是active的,而一个或更多的RM处于standby状态等待随时成为active。触发active的转换的条件是通过admin命令行或者在automatic-failover启用的情况下通过集成的failover-controller触发。
自动failover
RM有一个选项可以嵌入使用Zookeeper的ActiveStandbyElector来决定哪个RM成为Active。当Active挂掉或者不响应时,另一个RM会自动被选举为Active然后接管集群。注意,并不需要像HDFS一样运行一个隔离的ZKFC守护进程,因为对于嵌入到RM中的ActiveStandbyElector表现出来就是在做failure检查和leader选举,不用单独的ZKFC。
手动failover
当自动failover没有启用时,管理员需要手动切换众多RM中的一个成为active。为了从一个RM到其他RM进行failover,做法通常是先将现在的Active的RM切为Standby,然后再选择一个Standby切为Active。所有这些都可以通过 yarn rmadmin 的命令行完成。
在RM failover时的Client, ApplicationMaster和 NodeManager
当有多个RM时,被client和node使用的配置文件yarn-site.xml需要列出所有的RM。Clients, ApplicationMasters (AMs) 和 NodeManagers (NMs) 会以一种round-robin轮询的方式来不断尝试连接RM直到其命中一个active的RM。如果当前Active挂掉了,他们会恢复round-robin来继续寻找新的Active。默认的重试策略是 org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider类来实现的。你可以通过继承实现org.apache.hadoop.yarn.client.RMFailoverProxyProvider来覆盖这个方法,并且设置对应的类名到这个属性yarn.client.failover-proxy-provider。
从之前的主RM状态恢复
伴随ResourceManager的重启机制开启,升级为主的RM会加载RM内部状态并且恢复原来RM留下的状态,而这依赖于RM的重启特性。而之前提交到RM的作业会发起一个新的尝试请求。应用作业会周期性的checkpoint来避免任务丢失。状态存储对于所有的RM都必须可见。当前,有两种RMStateStore实现来支持持久化—— FileSystemRMStateStore 和 ZKRMStateStore。其中 ZKRMStateStore隐式的允许在任意时刻写到一个单一的RM,因此是HA集群的推荐存储。当使用ZKRMStateStore时,不需要单独的隔离机制来解决分布式的脑裂问题。
5.2 服务规划
| 服务器 | IP地址 | 部署组件 | 高可用组件 |
|---|---|---|---|
| hadoop1 | 10.10.8.11 | namenode、datanode、resourcemanager、nodemanager | zookeeper |
| hadoop2 | 10.10.8.12 | namenode、datanode、resourcemanager、nodemanager | zookeeper |
| hadoop3 | 10.10.8.13 | datanode、nodemanager | zookeeper |
5.3 添加 RM 高可用配置
修改 yarn-site.xml 配置文件
1 | <configuration> |
修改完后将文件同步到其它hadoop节点
1 | [hadoop@hadoop1 ~/hadoop-2.7.2/etc/hadoop]$ scp yarn-site.xml hadoop@hadoop2:~/hadoop-2.7.2/etc/hadoop/ |
5.4 启动 YARN 服务
完成之后直接启动 YARN 服务不需要进行格式化
1 | [hadoop@hadoop1 ~/hadoop-2.7.2/sbin]$ ./stop-yarn.sh |
查看 yarn 服务状态
1 | [hadoop@hadoop1 ~]$ yarn rmadmin -getServiceState rm1 |
5.5 验证 YARN 高可用
在active状态的节点上,关闭 resourcemanager 服务
1 | [hadoop@hadoop1 ~]$ jps |
再次查看 yarn 服务状态
1 | [hadoop@hadoop1 ~]$ yarn rmadmin -getServiceState rm2 |
另一个已经切换为 active 状态
YRAN 同样也可以使用命令 yarn rmadmin -transitionToActive --forcemanual rm1 手动切换 active 节点
5.6 访问 YARN web页面
YARN 开启了高可用后,如果访问的是 standby 节点页面会跳转到 active 节点