一、集群简介
Hadoop 集群具体来说包含两个集群:HDFS集群和YARN集群,两个逻辑上分离,但物理上常在一起。
HDFS集群负责海量数据的存储,集群中的角色主要有:NameNode、DataNode、SecondaryNameNode
YARN集群负责海量数据运算时的资源调度,集群中的角色主要有:ResourceManager、NodeManager
那mapreduce是什么呢?它其实是一个分布式运算编程框架,是应用程序开发包,由用户按照编程规范进行程序开发后打包运行在HDFS集群上,并且受到YARN集群的资源调度管理。
Hadoop的部署方式分三种:独立模式、伪分布式与完全分布式,其中前两种都是在单机部署。独立模式又称为单机模式,仅1个机器运行1个的java进程,主要用于调试。伪分布模式也是在1个机器上运行HDFS的NameNode、DataNode、SecondaryNameNode、ResourceManger和NodeManager,但分别启动单独的java的进程,主要用于调试。完全分布式模式主要用于生产环境部署。会使用n台主机组成一个Hadoop的集群。这种部署模式下,主节点和从节点会分开部署在不同的机器上。
二、部署Hadoop 分布式集群
2.1 集群规划
| 服务器 | IP地址 | 部署组件 |
|---|---|---|
| hadoop1 | 10.10.8.11 | namenode、datanode、resourcemanager、nodemanager |
| hadoop2 | 10.10.8.12 | secondarynamenode、datanode、nodemanager |
| hadoop3 | 10.10.8.13 | datanode、nodemanager |
以后如果需要为集群增加节点,只需要在新节点上运行datanode和nodemanager
2.2 部署前准备
2.2.1 调整文件句柄数
在所有hadoop服务器上执行
1 | [root@hadoop1 ~]# vim /etc/security/limits.conf |
2.2.2 配置主机名和hosts
在所有hadoop服务器上执行
为所有服务器配置主机名和hosts解析,在生产环境一般都由DNS解析这里用hosts代替
1 | [root@hadoop1 ~]# hostnamectl set-hostname hadoop1 |
2.2.3 创建hadoop专属用户
在所有hadoop服务器上执行
1 | [root@hadoop1 ~]# groupadd hadoop |
2.2.4 配置SSH免密登录
免密登录主要是为了以后使用sbin目录下的脚本一键进行启动/关闭HDFS和YARN
1 | [dev@hadoop1 ~]# su - hadoop |
2.2.5 安装jdk
在所有hadoop服务器上执行
这里我只在运行hadoop用户下配置jdk环境变量,为了避免以后使用到非hadoop用户执行命令而造成损失
1 | [hadoop@hadoop1 ~]$ tar xf downloads/jdk-8u301-linux-x64.tar.gz |
2.3 Hadoop配置文件修改
Hadoop的安装主要就是配置文件的修改,一般在主节点进行修改,完毕后SCP下发给其他各个从节点机器。
在hadoop安装目录下创建3个文件夹 用于存储hadoop数据,生产环境中应使用单独的磁盘
1 | [hadoop@hadoop1 ~]$ tar xf downloads/hadoop-2.7.2.tar.gz |
current/tmp目录,用来存储hadoop运行时生成的文件
hdfs/data目录,用来存储datanode数据
hdfs/name目录,用来存储namenode元数据
2.3.1 修改 hadoop-env.sh
文件中设置的是 Hadoop的运行时需要的环境变量JAVA_HOME是必须设置的,即使我们当前的系统中设置了JAVA_HOME,它也是不认识的,因为Hadoop的即使是在本机上执行,它也是把当前的执行环境当成远程服务器。
1 | [hadoop@hadoop1 ~/hadoop-2.7.2]$ cd etc/hadoop/ |
2.3.2 修改4个*-site.xml文件
修改Hadoop全局配置文件 core-site.xml
1 | [hadoop@hadoop1 ~/hadoop-2.7.2/etc/hadoop]$ vim core-site.xml |
修改HDFS的核心配置文件 hdfs-site.xml
1 | [hadoop@hadoop1 ~/hadoop-2.7.2/etc/hadoop]$ vim hdfs-site.xml |
修改MapReduce的核心配置文件 mapred-site.xml
需要从mapred-site.xml.template模板拷贝
1 | [hadoop@hadoop1 ~/hadoop-2.7.2/etc/hadoop]$ cp mapred-site.xml.template mapred-site.xml |
修改yarn的核心配置文件 yarn-site.xml
1 | [hadoop@hadoop1 ~/hadoop-2.7.2/etc/hadoop]$ vim yarn-site.xml |
2.3.3 修改 slaves
1 | [hadoop@hadoop1 ~/hadoop-2.7.2/etc/hadoop]$ vim slaves |
2.4 配置hadoop命令环境变量
为运行hadoop用户配置hadoop命令环境变量
1 | [hadoop@hadoop1 ~]$ vim .bash_profile |
2.5 格式化集群文件系统
在进行格式化操作前,先将修改好的hadoop目录scp到其它节点上
1 | [hadoop@hadoop1 ~]$ rsync -av hadoop-2.7.2 hadoop@hadoop2:~/ |
在主节点上格式化集群的文件系统
1 | [hadoop@hadoop1 ~]$ hadoop namenode -forma |
format中主要生成了hdfs(namenode)工作所需要的目录和一些初始化的文件
如果初始化了多次,format多次会导致主从之间的集群标识clusterID不一致造成互相不认识,并且数据丢失;可以删除每台机器上
hadoop.tmp.dir指定的文件夹内容,然后再重新format这样就相当于重新建了一个集群
2.6 启动hadoop分布式集群
hadoop启动方式可以分为以下三种:
单节点逐个启动
hdfs
hadoop-daemon.sh start|stop (namenode/datanode/secondarynamenode)
yarn
yarn-daemon.sh start|stop (resourcemanager/nodemanager)
脚本一键启动(需要做免密)
hdfs
start-dfs.sh|stop-dfs.sh
yarn
start-yarn.sh|stop-yarn.sh
start-all启动(需要做免密)
start-all.sh|stop-all.sh
2.6.1 启动 hdfs
1 | [hadoop@hadoop1 ~]$ cd hadoop-2.7.2/sbin |
2.6.2 启动 yarn
1 | [hadoop@hadoop1 ~/hadoop-2.7.2/sbin]$ ./start-yarn.sh |
查看各节点服务进程
1 | [hadoop@hadoop1 ~]$ jps |
到此分布式的hadoop集群已经搭好了
2.7 访问web页面
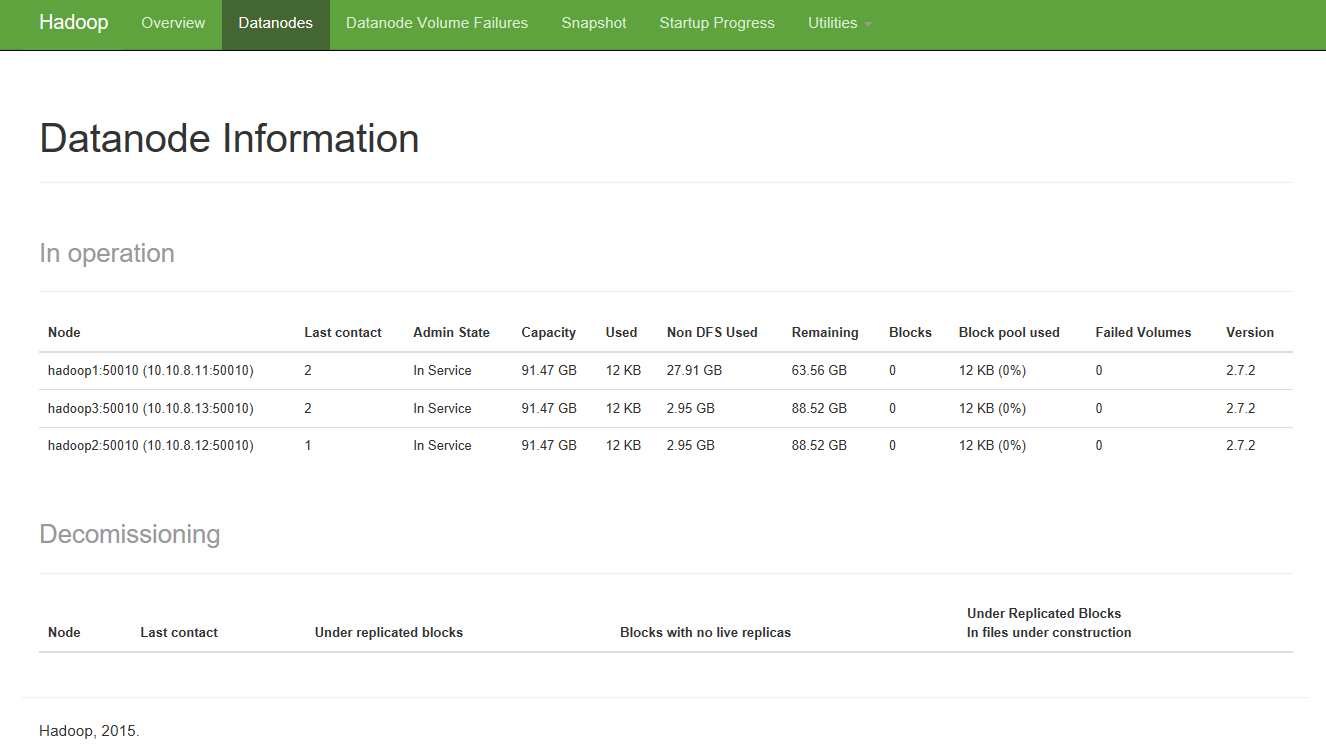
2.7.1 访问hdfs web页面
hdfs集群:http://namenode_host:50070
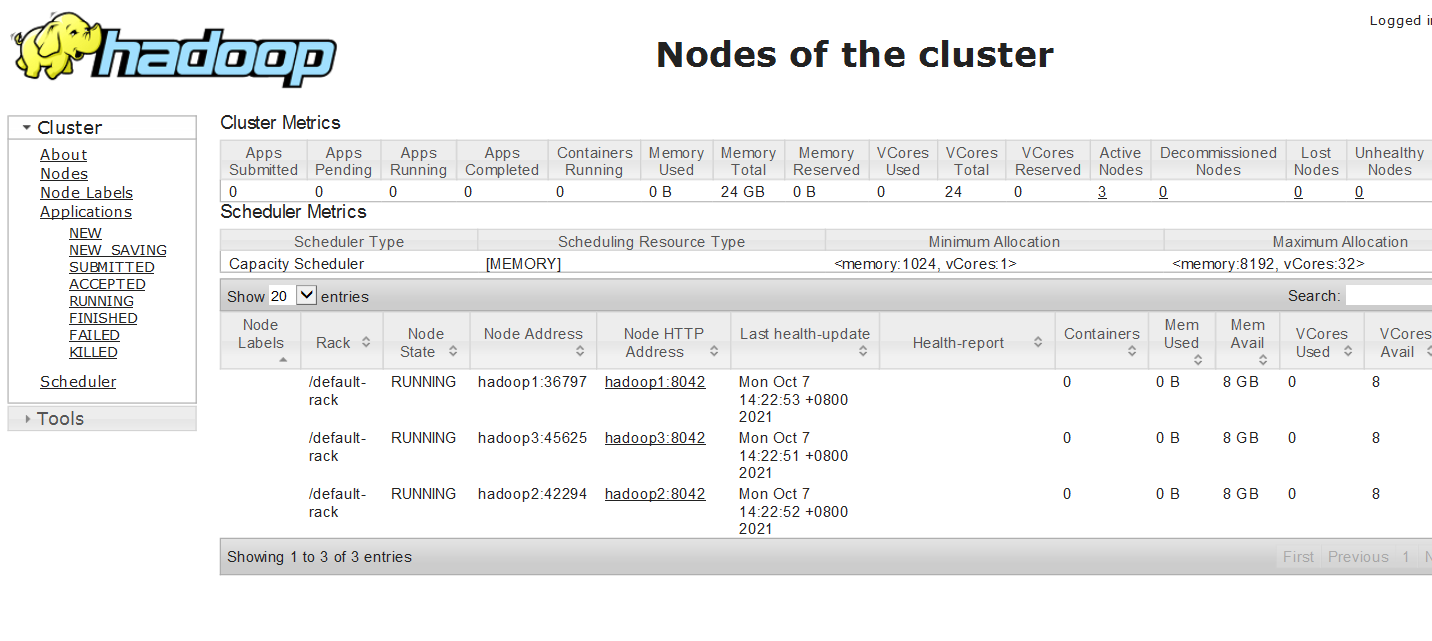
2.7.2 访问yarn web页面
yarn集群:http://resourcemanager_host:8088