事情起因
上次对超出docker 16k的大日志做了拼接后,虽然多行日志合并到了一行显示,但在查日志的时候依然不是特别方便;因为在很多情况下需要根据日志的level级别进行单独过滤,这次把日志中的level级别提取出来然后形成新的字段。
日志格式
通过统计日志发现,目前现网中存在多种日志格式,这里暂且划分为标准日志格式和非标准日志格式,它们的日志内容大致如下所示:
标准日志
服务打到docker容器中的标准格式日志如下:
1 | {"log":"[2021-03-15 20:20:58.255] [] [DEFAULT.autoRefreshFlowGraphJob_Scheduler_Worker-1] INFO [com.pintec.jingway.job.AutoRefreshFlowGraphJob] [38] - AutoRefreshFlowGraphJob 开始刷新, flowName:[Init_Test] \n","stream":"stdout","time":"2021-03-15T09:20:58.256399067Z"} |
可以看到标准日志都有共同点 [] [] [] level []
非标准日志
当然,也有一些非标准格式日志类似如下:
1 | {"log":"13:25:58.570 [http-nio-8080-exec-48] DEBUG org.javalite.activeweb.RequestDispatcher - Loaded routes from: app.config.RouteConfig\n","stream":"stdout","time":"2021-04-02T02:25:58.570630811Z"} |
明确目标
在几经沟通后并确认后,标准格式日志占80%以上,最后确定下来只需要对标准日志提取level字段,而非标准日志则不提取;后续由开发同学将日志统一更换为标准格式日志。
过程中遇到的问题
fluentd占用资源
在进行配置前fluentd平均在线上占用的资源为20m左右cpu、120Mi左右内存;然后,在刚开始的调试过程中发现fluentd占用的资源有明显上升。
经过多次测试发现是因为fluentd在进行正则匹配时,如果遇到无法匹配的日志fluentd就会疯狂的输出日志,这时cpu和内存资源会飞快的上升,如下图所示:
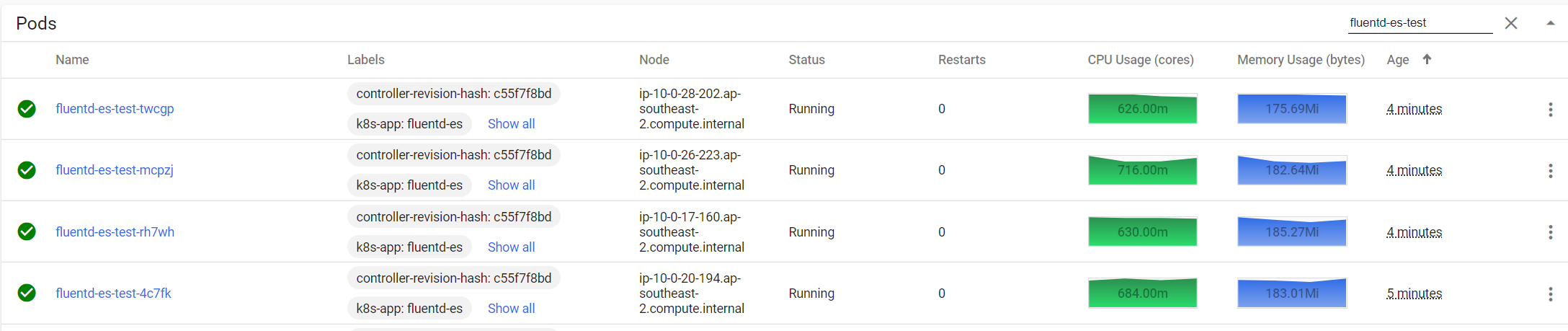
解决方案:需要合理调整fluentd中插件的先后顺序,再一个可以区分开无法匹配的日志另行处理(这个在后面配置文件中# 区分标准格式和非标准格式日志)。
需要舍弃部分日志
一开始我是想把所有只要带有level日志级别的都提取出来作为关键字,关键配置如下:
1 | <filter kubernetes.**> |
用过滤的方法匹配日志级,很显然基本上所有的日志都可以提取出level;
但同时也会带来问题,如果日志中不带有level日志级别就会被舍弃掉,最终ES中就查不到该日志了。
解决方案:只提取标准日志格式的level字段(决不能丢掉任何服务日志)。
tag字段被替换
当把资源占用问题处理了、标准日志格式也提取出了level字段,最后因为在处理标准日志和非标准日志过程中标记了tag,就是因为这个tag替换了原本日志的tag(采集的日志文件名)。
原日志tag类似:

被替换后的tag:

解决方案:将原tag字段的数据重新写入新的字段,如log_file (这个在后面配置文件中# 对解析出来的日志文件路径修改key,因为key与后面的关键字tag重名)。
解析出来的k8s相关字段过多
当一切准备就绪后,发现解析出来的k8s相关元数据非常多,大部分在查询过程中都使用不到,日志字段大致如下:
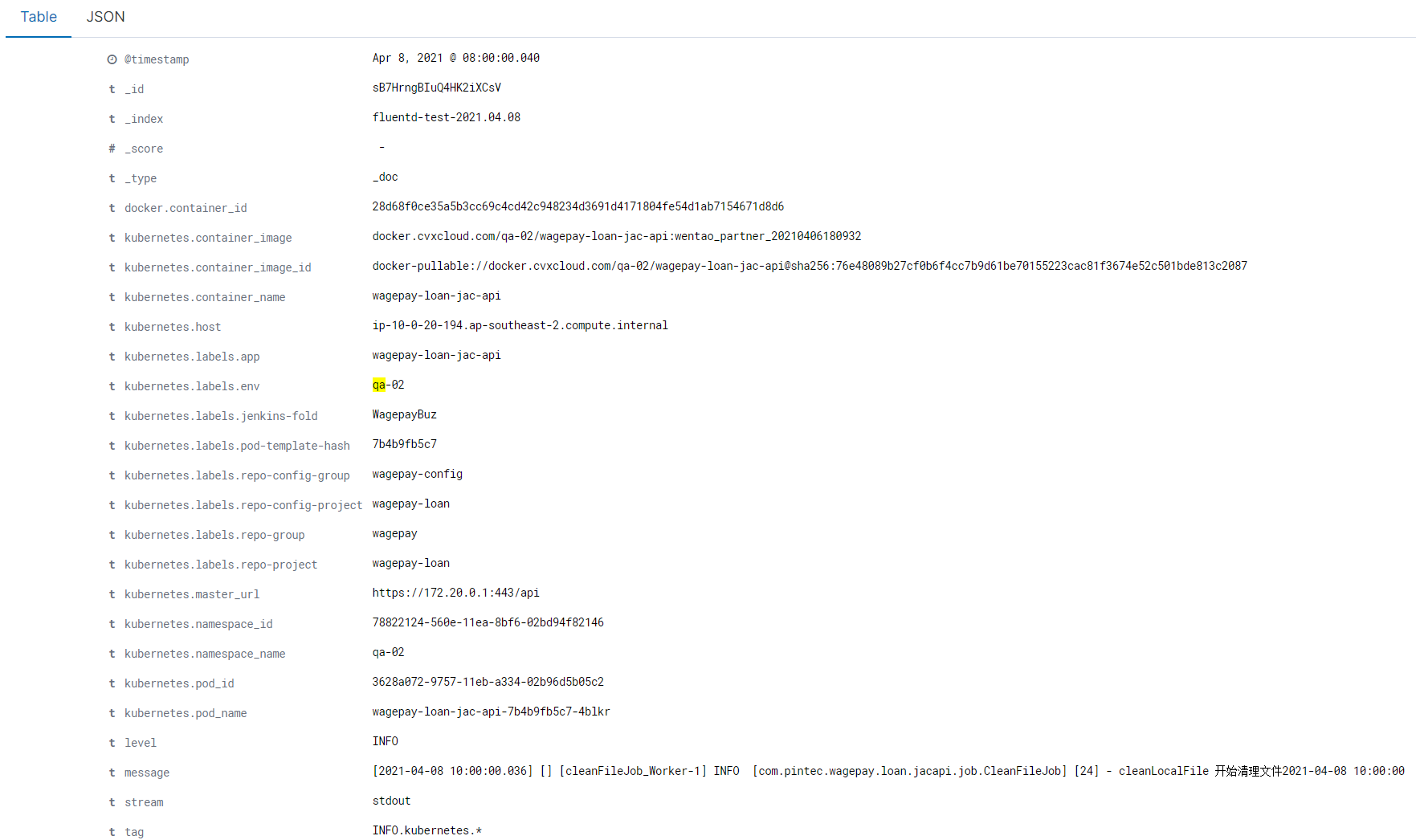
解决方案:删除日志字段(这个在后面配置文件中# 删除日志中不需要的key)。
最终的配置
最终的fluentd配置如下:
1 | # 日志源配置,格式化成json |
注意:由于引入插件ewrite_tag_filter在原官方docker镜像中没有安装,可以使用以下命令安装:
1 | gem install fluent-plugin-rewrite-tag-filter |
也可以使用我安装好的镜像:chenzz/fluentd:v3.0.2
output配置:
1 | <match **> |