问题描述
java服务产生的大日志收集到ES被拆分成多行,ES中被拆分的日志如下:
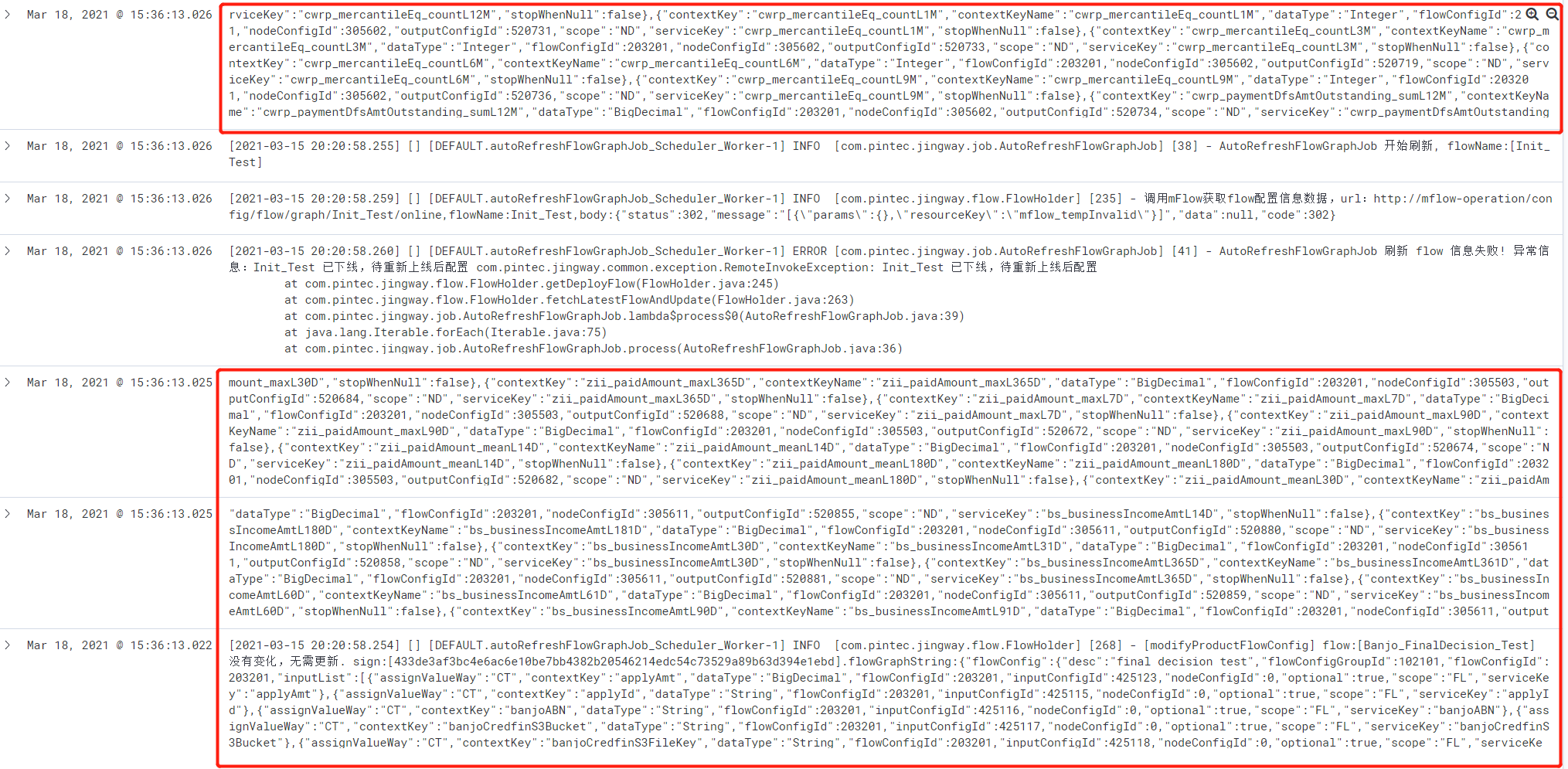
如上所示,红框中的日志本应该是一条,存到ES里结果拆分为了4条日志。
问题排查
于是,就去服务器上找这几条原始日志,如下:

通过对比发现和ES日志完全一样,这说明日志并不是在Fluentd进行收集的时候拆分的。
分析问题
根据观察被拆分处也没有规律,唯一的规律就是日志都特别长,显然日志很有可能是在写入docker stdout时就被拆分了。
确定问题
通过搜索发现,在docker github项目上也有人遇到过该问题,
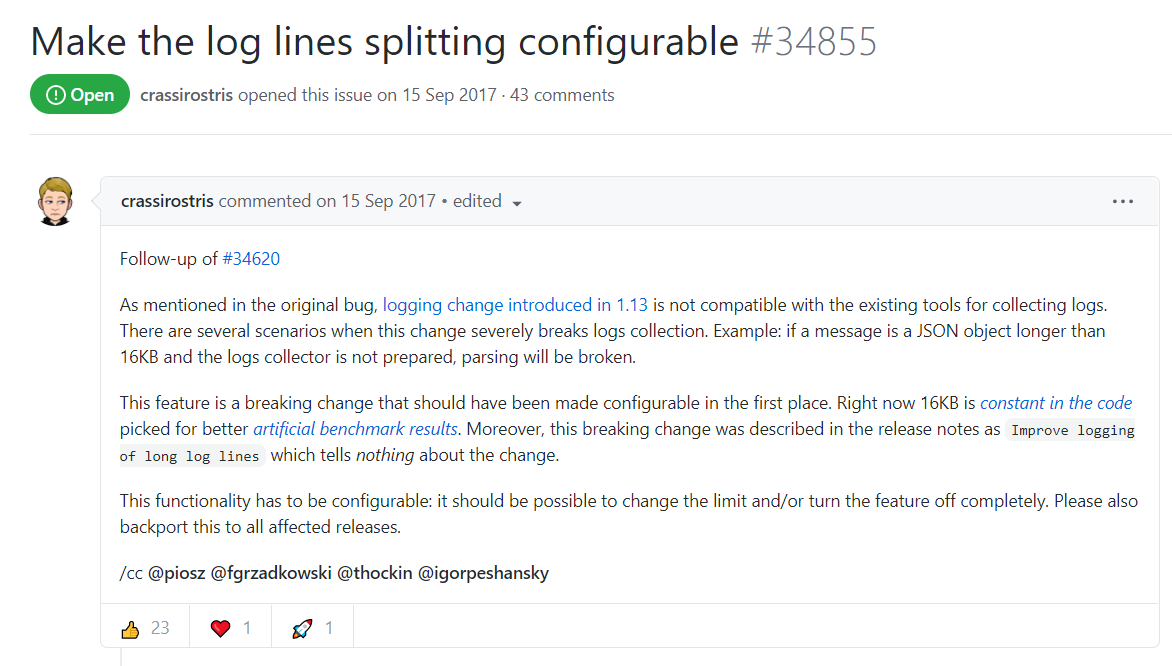
大概的意思是说:在docker 1.13以后的版本中引入了日志更改,如果消息是长度超过16KB的JSON对象,docker会将其拆分。
此问题,在docker 源码中也得到了证实。
解决问题
既然导致日志拆分的原因已经找到了,大致可以从以下3个方面解决大日志拆分
- 把docker版本降到1.13以下
- 修改docker源码,然后重新编译
- 在Fluentd中对拆分的日志进行合并
经过分析发现前面两个在实施的过程中会对现有服务产生较大影响(因为现有服务大多数只运行了一个pod),既然这样那只有实施第3个方案了。
顺着docker github上的问题,找到了一个可以合并多行日志的插件,随后经过多番测试成功合并了因docker 16k限制而拆分的大日志。
合并后的结果如下:
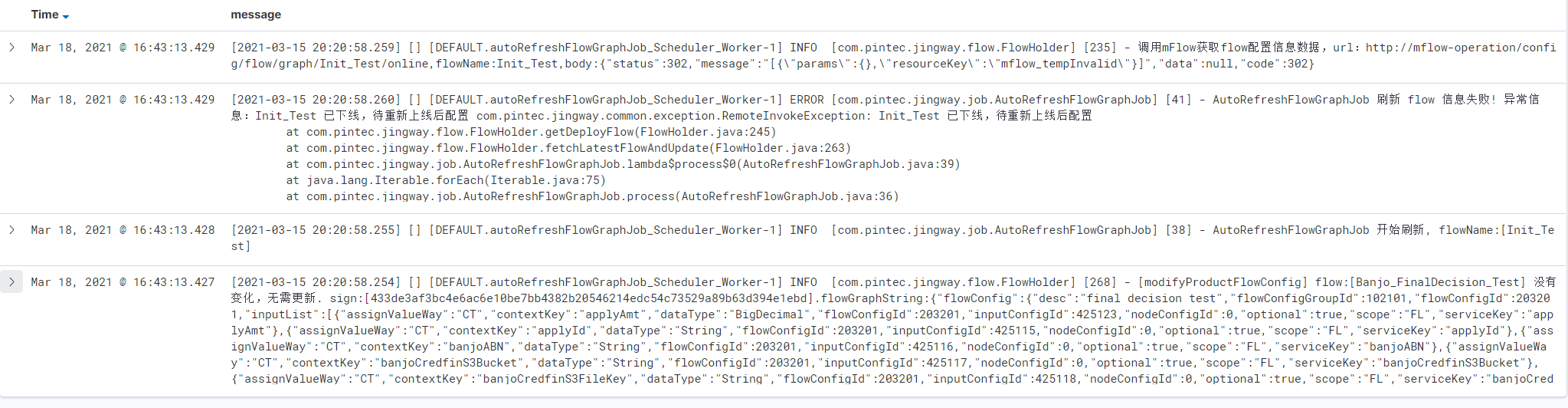
前面的7条日志,最终合并成了4条
Fluentd 配置
经过调试后,最终fluentd的配置如下,主要就是增加了concat多行合并配置
1 | # cat fluentd.conf |