由于我们常用的node_exporter并不能覆盖所有监控项,这里我们使用Process-exporter 对进程进行监控。
process-export主要用来做进程监控,比如某个服务的进程数、消耗了多少CPU、内存等资源。
一、process-exporter使用
1.1 下载 process-exporter
process-exporter GibHUB地址
process-exporter 下载地址
process-exporter可以使用命令行参数也可以指定配置文件启动
1.2 配置 process-exporter
1 | vim /home/admin/process-exporter/process_name.yaml |
cmdline: 所选进程的唯一标识,ps -ef 可以查询到。如果改进程不存在,则不会有该进程的数据采集到。
例如:> ps -ef | grep redis
redis 4287 4127 0 Oct31 ? 00:58:12 redis-server *:6379
{{.Comm}} groupname=”redis-server” exe或者sh文件名称 {{.ExeBase}} groupname=”redis-server *:6379” / {{.ExeFull}} groupname=”/usr/bin/redis-server *:6379” ps中的进程完成信息 {{.Username}} groupname=”redis” 使用进程所属的用户进行分组 {{.Matches}} groupname=”map[:redis]” 表示配置到关键字“redis”
1.3 编写启动脚本
1 | vim /usr/lib/systemd/system/process_exporter.service |
1.4 启动 procexx-export
1 | systemctl daemon-reload |
验证监控数据
1 | curl http://localhost:9256/metrics |
二、prometheus 配置
添加或修改配置
1 | - job_name: 'doog_dev_prometheus' |
重启prometheus服务
1 | curl -X POST http://127.0.0.1:9090/-/reload |
三、grafana出图
process-exporter对应的dashboard为:https://grafana.com/grafana/dashboards/249
效果如下
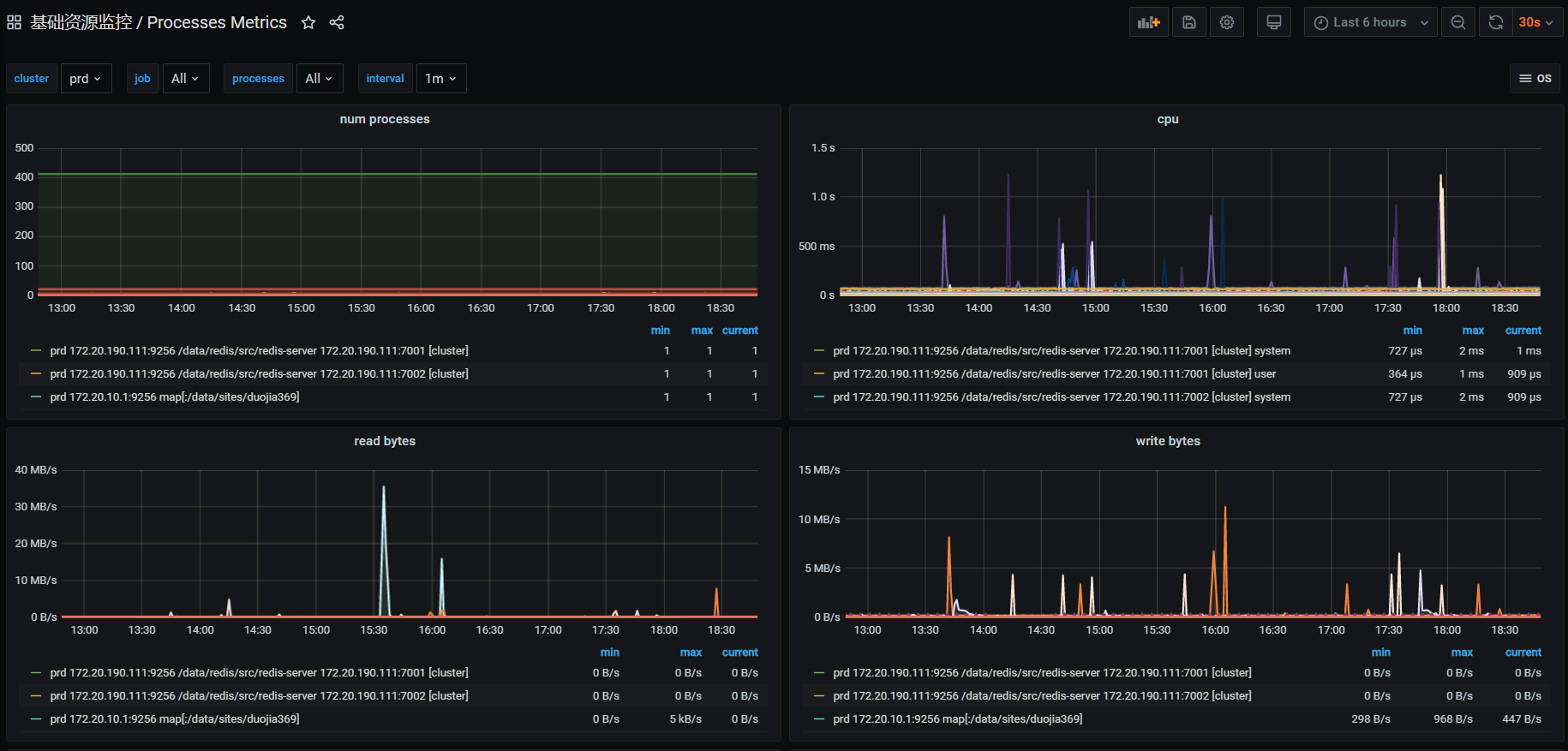
四、常用监控规则
进程数
1 | alert: 进程告警 |
僵尸进程数
1 | alert: 进程告警 |
进程重启
1 | alert: 进程重启告警 |
进程退出
1 | alert: 进程退出告警 |