1、简介
为了扩展单个 Prometheus 的采集能力和存储能力,Prometheus 引入了“联邦”的概念。
多个 Prometheus节点组成两层联邦结构,如图所示。
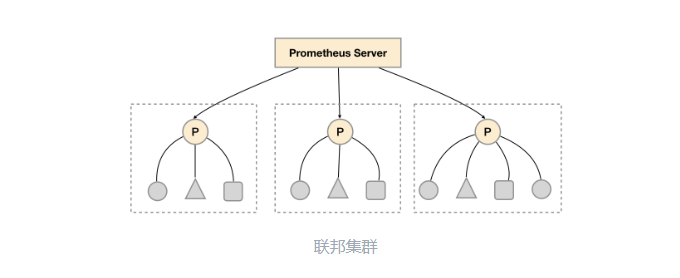
在每个数据中心部署单独的Prometheus Server,用于采集当前数据中心监控数据。并由一个中心的Prometheus Server负责聚合多个数据中心的监控数据。这一特性在Promthues中称为联邦集群。
1.1 分层联邦
分层联邦允许 Prometheus 能够扩展到十几个数据中心和上百万的节点。在此场景下,联邦拓扑类似一个树形拓扑结构,上层的 Prometheus 服务器从大量的下层 Prometheus 服务器中收集和汇聚的时序数据。
例如,一个联邦设置可能由多个数据中心中的 Prometheus 服务器和一套全局 Prometheus 服务器组成。每个数据中心中部署的 Prometheus 服务器负责收集本区域内细粒度的数据(实例级别),全局 Prometheus 服务器从这些下层 Prometheus 服务器中收集和汇聚数据(任务级别),并存储聚合后的数据。这样就提供了一个聚合的全局视角和详细的本地视角。
1.2 跨服务联邦
在跨服务联邦中,一个服务的 Prometheus 服务器被配置来提取来自其他服务的 Prometheus 服务器的指定的数据,以便在一个 Prometheus 服务器中对两个数据集启用告警和查询。
例如,一个运行多种服务的集群调度器可以暴露在集群上运行的服务实例的资源使用信息(例如内存和 CPU 使用率)。另一方面,运行在集群上的服务只需要暴露指定应用程序级别的服务指标。通常,这两种指标集分别被不同的 Prometheus 服务器抓取。利用联邦,监控服务级别指标的 Prometheus 服务器也可以从集群中 Prometheus 服务器拉取其特定服务的集群资源使用率指标,以便可以在该 Prometheus 服务器中使用这两组指标集
2、配置联邦集群
在 Prometheus 服务器中,/federate 节点允许获取服务中被选中的时间序列集合的值。至少一个 match[] URL 参数必须被指定为要暴露的序列。每个 match[] 变量需要被指定为一个不变的维度选择器像 up 或者 {job=~"prometheus.*"}。如果有多个 match[] 参数,则所有符合的时序数据的集合都会被选择。
从一个 Prometheus 服务器联邦指标到另一个 Prometheus 服务器,配置你的目标 Prometheus 服务器从源服务器的 /federate 节点抓取指标数据,同时也使用 honor_lables 抓取选项(不重写源 Prometheus 服务暴露的标签)并且传递需要的 match[] 参数。
例如:下面的 scrape_configs 联邦三台 Prometheus 服务器,上层 Prometheus 抓取并汇总他们暴露的任何匹配下面 job="" 标签的序列或名称的指标。
1 | - job_name: 'prometheus_support' |