1.引言
MP3 是一种压缩比率极高、音质失真极小的有损音频压缩格式,得到了极其广泛的应用。它使得人都可以轻而易举地几乎不用任何成本( 或免费) 地分发音乐,轻松找到音乐,已成为数字音乐时代的事实标准[1]。如今 MP3 文件数量相当巨大,用户的访问需求日益增多( 如巨鲸网已收录了 360 万个 MP3 音乐文件[2]) ,如何有效存储和管理这些海量的MP3 文件,为用户提供良好体验的下载、播放等服务已成为待解决的问题。Hadoop 的出现,为我们提供了新的思路。
Hadoop 是一个能够对大量数据进行分布式处理的软件 框架,以 一 种 可 靠、高 效、可伸缩的方式处理海量 数 据。Hadoop 包含了多个组件,其中分布式文件系统 ( Hadoop Distributed File ystem,HDFS) 是最基础的部分。HDFS 有着高容错性的特点,设计用来部署在低廉的硬件上,能够提供极高的数据吞吐量,适合那些有着超大数据集的应用程序[3]。
HDFS 本质上是一种流式分块文件系统,设计之初主要是为了处理大文件( 文件大小通常在几百兆以上) ,在处理小文件时,会产生一些问题。小文件是指文件尺寸小于 HDFS块大小( 默认为 64 MB) 的文件。这样的文件会给 Hadoop 的扩展性 和 性 能 带 来 严 重 问 题。首 先,小 文 件 过 多 会 影 响NameNode 的内存和 DataNode 的内存使用[4]。在 HDFS 中,任何 block、文件或者目录在内存中均以对象的形式存储,每个对象约占 150 B,如果有 10000000 个小文件,每个文件占用一 个 block,则 NameNode 大 约 需 要 2 GB 空 间。 这 样NameNode 内存容量严重制约了集群的扩展。其次,访问大量小文件速度远远小于访问几个大文件。如果访问大量小文件,需要不断地从一个 DataNode 跳到另一个 DataNode,严重影响性能。最后,处理大量小文件速度远远小于处理同等大小的大文件的速度。每一个小文件要占用一个 slot,而 task启动将耗费大量时间甚至大部分时间都耗费在启动 task 和释放 task 上。小文件过多时,需要多次与 NameNode 交互,增加 NameNode 负载,使得需要多次 seek,也会在 DataNode 多次跳跃。文献[5]利用HAR(adoop Archive) 技术实现小文件的合并,提高了 HDFS 中元数据的存储效率; 文献[6]和文献[7]中分别提出了适用于 WebGIS 和 PPT 文件的存储机制,提高了小文件的存储和访问效率。以上的研究工作均特定于应用,不适合海量 MP3 文件的存储。本文提出了一种基于 Hadoop 的海量 MP3 文件存储架构,充分利用 MP3 文件自身包含的丰富的描述信息,通过预处理模块,使用归类算法,将应用相关性强的文件合并到Sequence File[8]中,大大减少了 HDFS 中的文件数量; 同时,引入高效的扩展一级索引机制,能够快速定位到 MP3 文件所在的 Sequence File 以及其偏移位置关系; 另外,通过富元数据管理模块,将 MP3 文件的富元信息( ID3V1 的信息) 进行集中索引和管理,可以为各种应用场景提供支持。
2.存储架构概述
在图 1 中可以看出,该架构对传统的 HDFS 进行了扩展,在传统 HDFS 的名字节点和数据节点之外,在名字节点中引入一级索引,并引入富元数据节点,存储更为丰富的元信息,为业务应用提供更为强大的支撑。
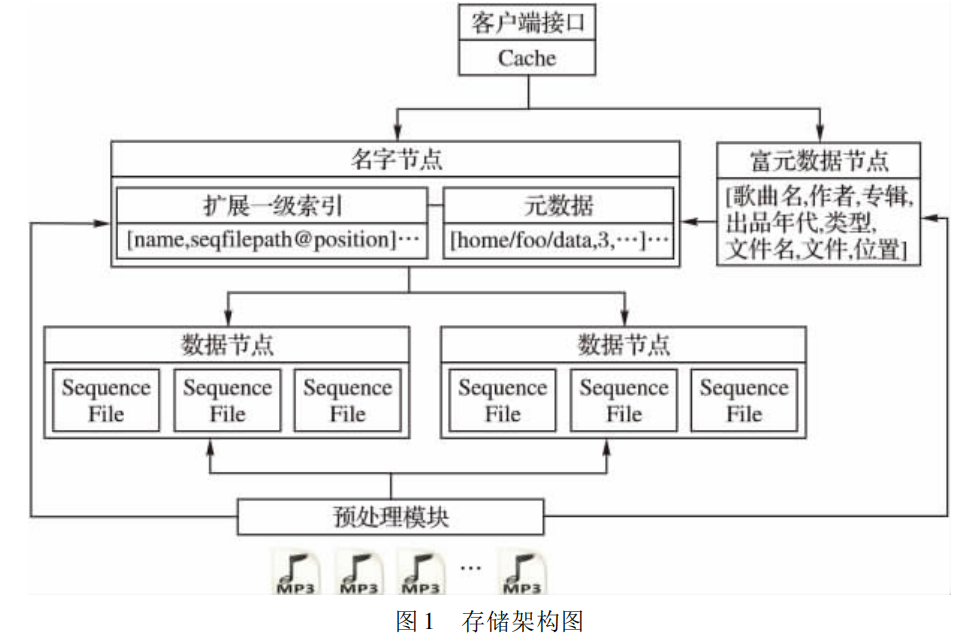
2.1 MP3 富元信息
MP3 文件大体分为三部分: ID3V2、Frame 和 ID3V1。ID3V1 比较简单,它存放在 MP3 文件的末尾,包含了作者、作曲、专辑等信息; ID3V2 存放在 MP3 头部,长度不固定,扩展了 ID3V1 的信息量; Frame 中存放了实际的音频数据。鉴于ID3V2 中的处理较复杂,而且多数 MP3 文件中不包含 ID3V2信息,本文采用 ID3V1 中的信息作为富元数据。ID3V1 数据结构[9]如下:
1 | typedef struct tagID3V1 |
2.2 文件写入
MP3 文件经过预处理之后,除了将归并后的序列文件写入标准的 HDFS 文件系统名字节点和数据节点之外,也会将MP3 文件与序列文件的对应关系存入扩展一级索引,同时,会将 MP3 文件更丰富的元信息( ID3V1) 写入富元数据节点。
2.3 文件访问
访问某 MP3 文件时,首先在扩展一级索引中找到其对应的序列文件名和该 MP3 文件在此序列文件中的起始位置,之后通过 HDFS 元数据找到此序列文件的信息,客户端从数据节点中该起始位置读取对应的 MP3 文件,同时,将一级索引和元数据缓存到 Cache 中,以备下次使用。
3.模块实现
3.1 预处理模块
专辑是现代音乐最主要的发行方式,通常由 3~15 首歌组成,长度大多在 12 min~74 min,对应的 MP3 文件大小总和一般不超过 64 MB( HDFS 默认块大小) 。用户对 MP3 的访问通常具备局部性的特点,即访问的 MP3 之间有相当的关联,同一作者,或同一专辑,或同一年代,或同一类型的歌曲经常会被同时访问。根据以上特点,使用归类算法进行预处理,算法步骤如下:
1) 将所有 MP3 的富元信息( IDV3) 存入数据库;
2) 从库中读取属于同一专辑的文件,合并生成一个 Sequence File,将分类结果信息记录入库,并将对应关系存入扩展一级索引;
3) 将未能分类的文件,依据作者进行二次分类,将同一类的 MP3 文件合并生成一个 Sequence File,将分类结果信息记录入库,并将对应关系存入扩展一级索引;
4) 将未能分类的文件,依据年代进行三次分类,将同一类的 MP3 文件合并生成一个 Sequence File,将分类结果信息记录入库,并将对应关系存入扩展一级索引;
5) 对于经过 2) 、3) 、4) 三个步骤仍然不能有效归类的文件,则根据 MP3 文件名的拼音顺序进行分类。
3.2 一级索引模块
将[MP3 歌曲名,序列文件路径@ 起始位置]存入名字节点中,使用与元数据相同的机制,初始时装载到名字节点的内存中,同时,客户端使用 cache 机制缓存访问过的[MP3 歌曲名,序列 文 件 路 径 @ 起 始 位 置],以 便 快 速 查 找,减 少 与NameNode 的通信次数。其中序列文件路径直接从 HDFS 的根目录开始,使用 6 个字符来表示顺序生成的文件名( 每位可以使用 a~z 和 0~9,共可以表示 21 亿个文件) ,歌曲名的平均长度在 5 个汉字( 10 个字节) ,起始位置使用 36 进制( Java 语言默认支持的最大进制数) 表示,共需要 6 B,因此,每个 MP3 文件共需要 23( 10 + 6 + 1 + 6) B 来存放此索引,2GB 内存能存放 1 亿个文件。
3.3 富元数据管理模块
由于 NameNode 中的元数据是为了完成通用的文件管理而用,不能处理更为丰富的元数据,因此本文引入富元数据管理模块,对整个系统内所有 MP3 的元数据( ID3V1) 进行集中索引和管理。元数据管理模块对 NameNode 进行扩展,采用Key-Value 存储的文档数据库 CouchDB[10],为了提高性能,采用 Memcach[11]作为缓存,构建结构为: { 文件名,歌曲名,作者,专辑,出品年代,类型} 的对象,并在歌曲名、作者、专辑上分别添加索引。基于这些丰富的元数据,可以为上层应用提供有力的支撑。
4.性能评估
4.1 实验环境
实验平台为 5 台 IBM X3200M3 PC 服务器构成的 Hadoop 集群,每 个 节 点 均 为 4 核 Intel Xeon X3430 CPU,频 率 为2.4 GHz,4 GB 内存,2 TB SATA 硬盘。操作系统均为 64 位CentOS 5.5( 内核版本为 2.6.18) 。Hadoop 版本是 0.20.1,JDK 版本为 1.6.0。
在 5 台服务器中,其中 1 台为名字节点,3 台为数据节点,另外 1 台为富元数据节点。测试中使用 10 万首 MP3 文件,模拟 100 个并发用户访问场景,每次测试后均重启各节点。
4.2 实验结果
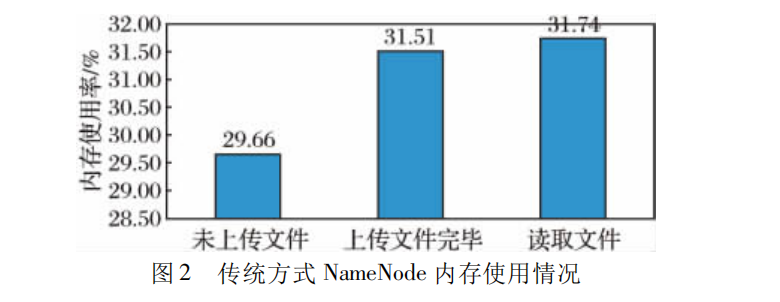
4.2.1 传统方式( Hadoop 直接管理 MP3 文件)
将 10 万首 MP3 直接存入 Hadoop 中,NameNode 的内存占用情况图 2。
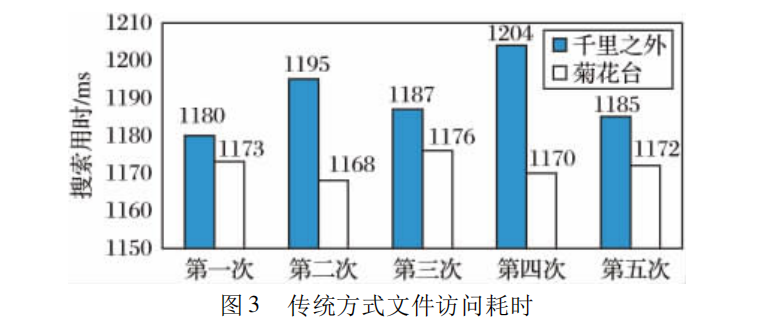
依次读取同一张专辑的两首歌曲: 《菊花台》和《千里之外》,需要的时间( 100 位并发用户的平均时间) 如图 3 所示。
4.2.2 改进后使用 SequenceFile 方式
使用本文提出的架构,NameNode 的内存使用情况与传统方式下的对比如图 4 所示。
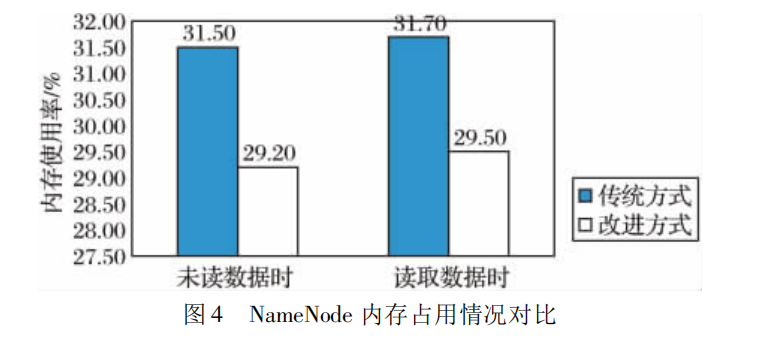
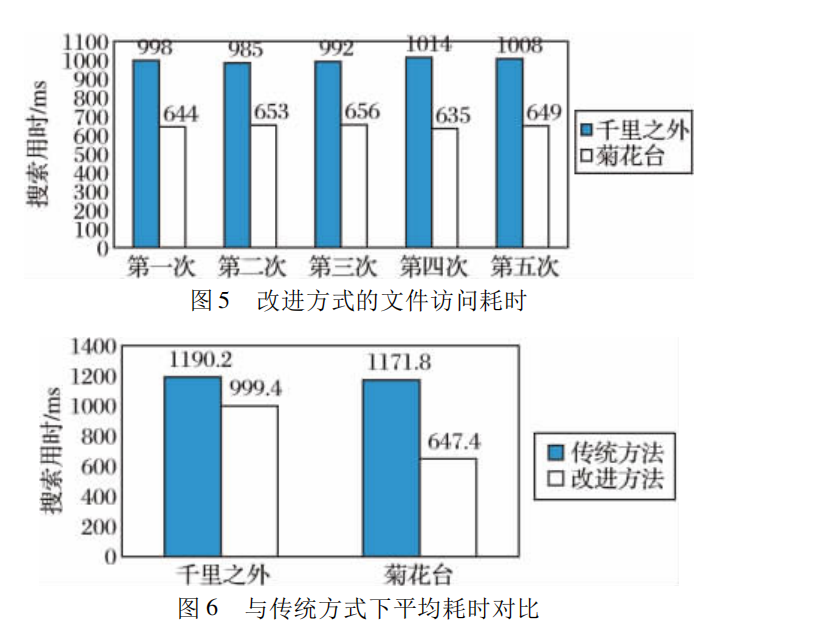
由图 4 可 以 看 出,使用本文提出的改进方式后,NameNode 的内存占用显著下降,也就意味着同样的硬件配置下,Hadoop 可以管理的文件数量更多。依次读取同一专辑内的两首歌曲: 《菊花台》和《千里之外》,通过预处理,这两首歌曲已归并到同一个 SequenceFile中,5 次访问的耗时情况( 100 位并发用户的平均时间) 如图 5所示。与传统方式下的平均耗时对比如图 6 所示。由图 6 可以看出,改进方式下,并不会由于一级索引的引入带来性能的影响,而且,由于两次访问的歌曲属于同一个SequenceFile,操作系统会对该文件进行缓存[12],所以第二次访问时性能有较明显的提升。
5.结语
本文从实际应用场景出发,采用“自顶向下”的设计方法,充分利用 MP3 文件自身丰富的元信息,提出了一种基于Hadoop 的海量 MP3 文件存储模型。经实际验证,此方法能够很好地解决 Hadoop 处理小文件时的 NameNode 内存瓶颈问题,同时具备良好的性能,能够支撑大规模用户的并发访问。
参考文献:
[1] 王福林.新技术对音乐产业的冲击[J].辽宁行政学院学报,2008,10(1):185-186.
[2] 巨鲸网[EB/OL].[2011-11-08].http://top100.cn/
[3] WHITE T.Hadoop: The definitive guide[M].[S.l.]:O’Reilly Media,2009.
[4] Small files problem[EB/OL].[2011-11-10].http://www.cloud-era.com/blog/2009/02/the-small-files-problem/
[5] MACKEY G, SEHRISH S,WANG JUN. Improving metadata man-agement for small files in HDFS[C] // Proceedings of 2009 IEEE In-ternational Conference on Cluster Computing and Workshops.Piscat- away: IEEE Press,2009:1-4.
[6] LIU XUHUI,HAN JIZHONG,ZHONG YUNQIN,et al. Implemen-ting WebGIS on Hadoop: A case study of improving small file I/O performance on HDFS[C]//2009 IEEE International Conference on Cluster Computing and Workshops. Piscataway: IEEE Press,2009:1-8.
[7] DONG BO,QIU JIE,ZHENG QINGHUA,et al. A novel approach to improving the efficiency of storing and accessing small files on Ha- doop: a case study by PowerPoint files [C]//Proceedings of the 2010 IEEE International Conference on Services Computing. Wash- ington, DC: IEEE Computer Society, 2010:65-72.
[8] Hadoop sequence file[EB/OL].[2011-11-12] http://hadoop.a-pache.org/common/docs/current/api/org/apache/hadoop/io/Se-quenceFile.htm.
[9] MP3 文件格式[EB/OL].2011-11-13].http://en.wikipedia.org/wiki/MP3.
[10] CouchDB[EB/OL].[2011-11-14].http://couchdb.apache.org/docs/overview.html.
[11] Memcached[EB/OL].[2011-11-15].http://memcached.org/
[12] GHEMAWAT S, GOBIOFF H, LEUNG S T. The Google file sys-tem[C]//Proceedings of the 19th ACM Symposium on Operating Systems Principles. New York: ACM,2009:29-43.