一、概述
随着OpenStack日渐成为开源云计算的标准软件栈,Ceph也已经成为OpenStack的首选后端存储。Ceph是一种为优秀的性能、可靠性和可扩展性而设计的统一的、分布式文件系统。
ceph官方文档 http://docs.ceph.org.cn/
ceph中文开源社区 http://ceph.org.cn/
Ceph是一个开源的分布式文件系统。因为它还支持块存储、对象存储,所以很自然的被用做云计算框架openstack或cloudstack整个存储后端。当然也可以单独作为存储,例如部署一套集群作为对象存储、SAN存储、NAS存储等。
ceph支持
1、对象存储:即radosgw,兼容S3接口。通过rest api上传、下载文件。
2、文件系统:posix接口。可以将ceph集群看做一个共享文件系统挂载到本地。
3、块存储:即rbd。有kernel rbd和librbd两种使用方式。支持快照、克隆。相当于一块硬盘挂到本地,用法和用途和硬盘一样。比如在OpenStack项目里,Ceph的块设备存储可以对接OpenStack的后端存储
Ceph相比其它分布式存储有哪些优点?
1、统一存储
虽然ceph底层是一个分布式文件系统,但由于在上层开发了支持对象和块的接口。所以在开源存储软件中,能够一统江湖。至于能不能千秋万代,就不知了。
2、高扩展性
扩容方便、容量大。能够管理上千台服务器、EB级的容量。
3、可靠性强
支持多份强一致性副本,EC。副本能够垮主机、机架、机房、数据中心存放。所以安全可靠。存储节点可以自管理、自动修复。无单点故障,容错性强。
4、高性能
因为是多个副本,因此在读写操作时候能够做到高度并行化。理论上,节点越多,整个集群的IOPS和吞吐量越高。另外一点ceph客户端读写数据直接与存储设备(osd) 交互。
Ceph各组件介绍:
•Ceph OSDs: Ceph OSD 守护进程( Ceph OSD )的功能是存储数据,处理数据的复制、恢复、回填、再均衡,并通过检查其他OSD 守护进程的心跳来向 Ceph Monitors 提供一些监控信息。当 Ceph 存储集群设定为有2个副本时,至少需要2个 OSD 守护进程,集群才能达到 active+clean 状态( Ceph 默认有3个副本,但你可以调整副本数)。
•Monitors: Ceph Monitor维护着展示集群状态的各种图表,包括监视器图、 OSD 图、归置组( PG )图、和 CRUSH 图。 Ceph 保存着发生在Monitors 、 OSD 和 PG上的每一次状态变更的历史信息(称为 epoch )。
•MDSs: Ceph 元数据服务器( MDS )为 Ceph 文件系统存储元数据(也就是说,Ceph 块设备和 Ceph 对象存储不使用MDS )。元数据服务器使得 POSIX 文件系统的用户们,可以在不对 Ceph 存储集群造成负担的前提下,执行诸如 ls、find 等基本命令。
二、Ceph实验集群部署
1. 主机准备 (禁用selinux, 关闭防火墙)
ceph1 10.10.10.67 admin,osd, mon 作为管理和监控节点
ceph2 10.10.10.68 osd,mds
ceph3 10.10.10.69 osd,mds
ceph4 10.10.10.70 client
#ceph1作管理. osd. mon节点; ceph2和69作osd mds; ceph4客户端
前三台服务器增加一块硬盘/dev/sdb实验, 创建目录并挂载到/var/local/osd{0,1,2}
1 | [root@ceph1 ~]# mkfs.xfs /dev/sdb |
2. 编辑hosts文件
(规范系统主机名添加hosts文件实现集群主机名与主机名之间相互能够解析(host 文件添加主机名不要使用fqdn方式)可用hostnamectl set-hostname name设置
分别打开各节点的/etc/hosts文件,加入这四个节点ip与名称的对应关系
10.10.10.67 ceph1
10.10.10.68 ceph2
10.10.10.69 ceph3
10.10.10.70 ceph4
SSH免密码登录
在管理节点使用ssh-keygen 生成ssh keys 发布到各节点
1 | [root@ceph1 ~]# ssh-keygen #所有的输入选项都直接回车生成。 |
3. 管理节点安装ceph-deploy工具
第一步:增加 yum配置文件(各个节点都需要增加yum源)
1 | [root@ceph1 ~]# vim /etc/yum.repos.d/ceph.repo |
4.创建monitor服务
1 | [root@ceph1 ~]# mkdir /etc/ceph && cd /etc/ceph |
5.修改副本数
1 | [root@ceph1 ceph]# vim ceph.conf 配置文件的默认副本数从3改成2,这样只有两个osd也能达到active+clean状态,把下面这行加入到[global]段(可选配置) |
6.在所有节点安装ceph
(如果网络源安装失败,手工安装epel-release 然后安装yum –yinstall cep-release再yum –y install ceph ceph-radosgw)
1 | [root@ceph1 ceph]# ceph-deploy install ceph1 ceph2 ceph3 ceph4 |
7.部署osd服务
添加osd节点 (所有osd节点执行)
我们实验准备时已经创建目录/var/local/osd{id}
8.创建激活osd
1 | #创建osd |
如果报错:

解决:在各个节点上给/var/local/osd1/和/var/local/osd2/添加权限
如下:
1 | [root@ceph1 ceph]# chmod 777 -R /var/local/osd1/ |
查看状态:
1 | [root@ceph1 ceph]# ceph-deploy osd list ceph1 ceph2 ceph3 |
9.统一配置
用ceph-deploy把配置文件和admin密钥拷贝到所有节点,这样每次执行Ceph命令行时就无需指定monitor地址和ceph.client.admin.keyring了
1 | [root@ceph1 ceph]# ceph-deploy admin ceph1 ceph2 ceph3 |
各节点修改ceph.client.admin.keyring权限:
1 | [root@ceph1 ceph]#chmod +r /etc/ceph/ceph.client.admin.keyring |
10.查看osd状态
1 | [root@ceph1 ceph]# ceph health 或 ceph -s |
11.部署mds服务
1 | [root@ceph1 ceph]# ceph-deploy mds create ceph2 ceph3 #我们MDS安装2台 |
12.集群状态
1 | [root@ceph1 ceph]# ceph -s |
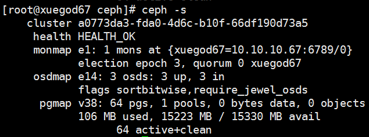
以上基本上完成了ceph存储集群的搭建。
三 、创建ceph文件系统
1 | [root@ceph1 ceph]# ceph fs ls #创建之前 |
其中:
关于创建存储池
确定 pg_num 取值是强制性的,因为不能自动计算。下面是几个常用的值:
*少于 5 个 OSD 时可把 pg_num 设置为 128
*OSD 数量在 5 到 10 个时,可把 pg_num 设置为 512
*OSD 数量在 10 到 50 个时,可把 pg_num 设置为 4096
*OSD 数量大于 50 时,你得理解权衡方法、以及如何自己计算 pg_num 取值
*自己计算 pg_num 取值时可借助 pgcalc 工具
随着 OSD 数量的增加,正确的 pg_num 取值变得更加重要,因为它显著地影响着集群的行为、以及出错时的数据持久性(即灾难性事件导致数据丢失的概率)。
1. 创建文件系统
创建好存储池后,你就可以用 fs new 命令创建文件系统了
1 | [root@ceph1 ceph]# ceph fs new <fs_name> cephfs_metadata cephfs_data |
2.挂载Ceph文件系统
有不同挂载方式
A.内核驱动挂载Ceph文件系统
1 | [root@ceph4 ceph]# mkdir /opt #创建挂载点 |
B.用户控件挂载Ceph文件系统
1 | 安装ceph-fuse |
ceph在开源社区还是比较热门的,但是更多的是应用于云计算的后端存储。所以大多数在生产环境中使用ceph的公司都会有专门的团队对ceph进行二次开发,ceph的运维难度也比较大。但是经过合理的优化之后,ceph的性能和稳定性都是值得期待的。
关于其他:
清理机器上的ceph相关配置:
停止所有进程: stop ceph-all
卸载所有ceph程序:ceph-deploy uninstall [{ceph-node}]
删除ceph相关的安装包:ceph-deploy purge {ceph-node} [{ceph-data}]
删除ceph相关的配置:ceph-deploy purgedata {ceph-node} [{ceph-data}]
删除key:ceph-deploy forgetkeys
卸载ceph-deploy管理:yum -y remove ceph-deploy