1 、常用的命令及工具
1.1 常用的查看系统性能的命令及工具
(后面会有相关命令及工具的用法)
1.1.1 查看CPU使用情况
每5秒刷新一次,最右侧有CPU的占用率的数据
1 | $ vmstat 5 |
top 然后按Shift+P,按照进程处理器占用率排序
1 | $ top |
1.1.2 查看内存使用情况
用free命令查看内存占用情况
1 | $ free |
top 然后按Shift+M, 按照进程内存占用率排序
1 | $ top |
1.1.3 查看网络流量
可以用工具iptraf工具
1 | $ iptraf -g |
针对某个Interface的网络流量可以通过比较两个时间网络接口的RX和TX数据来获得
1 | $ date; ifconfig eth1 |
1.1.4 查看磁盘i/o
用iostat查看磁盘/dev/sdc3的磁盘i/o情况,每两秒刷新一次
1 | $ iostat -d -x /dev/sdc3 2 |
用vmstat查看io部分的信息
1.2 Linux 查看CPU,内存,硬盘
1.2.1 查看CPU
查看CPU个数
1 | cat /proc/cpuinfo | grep "physical id" | uniq | wc -l |
uniq命令:删除重复行;wc –l命令:统计行数
总结:该服务器有2颗CPU
查看CPU核数
1 | cat /proc/cpuinfo | grep "cpu cores" | uniq |
总结:该服务器CPU的核心数为4
查看CPU型号
1 | cat /proc/cpuinfo | grep 'model name' |uniq |
总结:该服务器有2个4核CPU,型号Intel(R) Xeon(R) CPU E5630 @ 2.53GHz
1.2.2 查看内存
查看内存总数
1 | #cat /proc/meminfo | grep MemTotal |
总结:该服务器内存大小为4G
查看内存条数
具体个数大小:dmidecode|grep -P -A5 “Memory\s+Device”|grep Size|grep -v Range
1 | dmidecode |grep -A16 "Memory Device$" |
Memory Device
Array Handle: 0x1000
Error Information Handle: Not Provided
Total Width: 72 bits
Data Width: 64 bits
Size: 2048 MB //1条2G内存
Form Factor: DIMM
Set: 1
Locator: DIMM1
Bank Locator: Not Specified
Type: DDR2
Type Detail: Synchronous
Speed: 667 MHz
Manufacturer: 7F7F7F7F7F510000
Serial Number: 0403E324
Asset Tag: 450721Part Number: 72T256220HR3SA
Memory Device
Array Handle: 0x1000
Error Information Handle: Not Provided
Total Width: 72 bits
Data Width: 64 bits
Size: 2048 MB //1条2G内存
Form Factor: DIMM
Set: 1
Locator: DIMM2
Bank Locator: Not Specified
Type: DDR2
Type Detail: Synchronous
Speed: 667 MHz
Manufacturer: 7F7F7F7F7F510000
Serial Number: 0403E324
Asset Tag: 450721Part Number: 72T256220HR3SA
Memory Device
Array Handle: 0x1000
Error Information Handle: Not Provided
Total Width: 72 bits
Data Width: 64 bits
Size: No Module Installed //1个内存空槽
Form Factor: DIMM
Set: 2
Locator: DIMM3
Bank Locator: Not Specified
Type: DDR2
Type Detail: Synchronous
Speed: Unknown
Manufacturer:
Serial Number:
Asset Tag:Part Number:
Memory Device
Array Handle: 0x1000
Error Information Handle: Not Provided
Total Width: 72 bits
Data Width: 64 bits
Size: No Module Installed //1个内存空槽
Form Factor: DIMM
Set: 2
Locator: DIMM4
Bank Locator: Not Specified
Type: DDR2
Type Detail: Synchronous
Speed: Unknown
Manufacturer:
Serial Number:
Asset Tag:Part Number:
Memory Device
Array Handle: 0x1000
Error Information Handle: Not Provided
Total Width: 72 bits
Data Width: 64 bits
Size: No Module Installed //1个内存空槽
Form Factor: DIMM
Set: 3
Locator: DIMM5
Bank Locator: Not Specified
Type: DDR2
Type Detail: Synchronous
Speed: Unknown
Manufacturer:
Serial Number:
Asset Tag:Part Number:
Memory Device
Array Handle: 0x1000
Error Information Handle: Not Provided
Total Width: 72 bits
Data Width: 64 bits
Size: No Module Installed //1个内存空槽
Form Factor: DIMM
Set: 3
Locator: DIMM6
Bank Locator: Not Specified
Type: DDR2
Type Detail: Synchronous
Speed: Unknown
Manufacturer:
Serial Number:
Asset Tag:
Part Number:
总结:该服务器有两条2G内存 ,空余4个插槽
1.2.3 查看硬盘
查看硬盘大小
1 | fdisk -l | grep Disk |
总结:硬盘大小107.4G,即厂商标称的120G
2、常用命令及工具的用法
2.1 top
Top命令显示当天的正常运行时间、系统负载、处理器的数量、内存的使用率和哪些进程使用了大多数CPU资源(包括每个进程的大量相关信息,例如在线用户和正在执行的命令等)。默认地,TOP命令每隔五分钟自动更新一次这个数据(这个更新间隔是可设置的)。
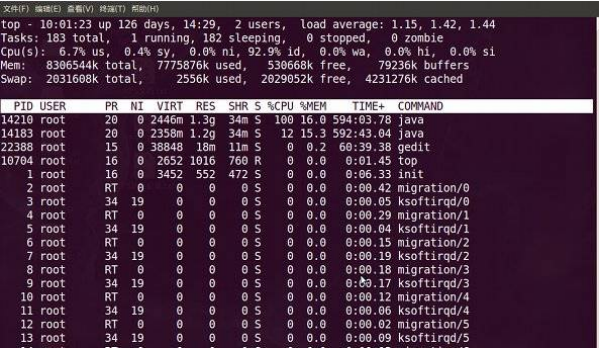
第一行:
10:01:23 当前系统时间
126 days, 14:29 系统已经运行了126天14小时29分钟(在这期间没有重启过)
2 users 当前有2个用户登录系统
load average: 1.15, 1.42, 1.44 load average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。
load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。
第二行:
Tasks 任务(进程),系统现在共有183个进程,其中处于运行中的有1个,182个在休眠(sleep),stoped状态的有0个,zombie状态(僵尸)的有0个。
第三行:cpu状态
6.7% us 用户空间占用CPU的百分比。
0.4% sy 内核空间占用CPU的百分比。
0.0% ni 改变过优先级的进程占用CPU的百分比
92.9% id 空闲CPU百分比
0.0% wa IO等待占用CPU的百分比
0.0% hi 硬中断(Hardware IRQ)占用CPU的百分比
0.0% si 软中断(Software Interrupts)占用CPU的百分比
第四行:内存状态
8306544k total 物理内存总量(8GB)
7775876k used 使用中的内存总量(7.7GB)
530668k free 空闲内存总量(530M)
79236k buffers 缓存的内存量 (79M)
第五行:swap交换分区
2031608k total 交换区总量(2GB)
2556k used 使用的交换区总量(2.5M)
2029052k free 空闲交换区总量(2GB)
4231276k cached 缓冲的交换区总量(4GB)
2.2 vmstat
vmstat是Virtual Meomory Statistics(虚拟内存统计)的缩写, 是实时系统监控工具。该命令通过使用knlist子程序和/dev/kmen伪设备驱动器访问这些数据,输出信息直接打印在屏幕。vmstat反馈的与CPU相关的信息包括:
(1)多少任务在运行
(2)CPU使用的情况
(3)CPU收到多少中断
(4)发生多少上下文切换
Vmstat命令提供给你一个当前CPU、IO、进程和内存使用率的快照。和TOP命令一样,它自动动态刷新,并且可以用下面的命令执行:
2.2.1 命令格式
代码如下:
vmstat [-a] [-n] [-S unit] [delay [ count]]
vmstat [-s] [-n] [-S unit]
vmstat [-m] [-n] [delay [ count]]
vmstat [-d] [-n] [delay [ count]]
vmstat [-p disk partition] [-n] [delay [ count]]
vmstat [-f]
vmstat [-V]
命令功能:
用来显示虚拟内存的信息
2.2.2 命令参数
-a:显示活跃和非活跃内存
-f:显示从系统启动至今的fork数量 。
-m:显示slabinfo
-n:只在开始时显示一次各字段名称。
-s:显示内存相关统计信息及多种系统活动数量。
delay:刷新时间间隔。如果不指定,只显示一条结果。
count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。
-d:显示磁盘相关统计信息。
-p:显示指定磁盘分区统计信息
-S:使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes)
-V:显示vmstat版本信息。
2.2.3 使用实例
2.2.3.1 显示虚拟内存使用情况
命令:vmstat
1 | [root@localhost ~]# vmstat 5 6 |
vmstat命令输出信息详细说明:
字段说明:
Procs(进程):
r: 运行队列中进程数量
b: 等待IO的进程数量
Memory(内存):
swpd: 使用虚拟内存大小
free: 可用内存大小
buff: 用作缓冲的内存大小
cache: 用作缓存的内存大小
Swap:
si: 每秒从交换区写到内存的大小
so: 每秒写入交换区的内存大小
IO:(现在的Linux版本块的大小为1024bytes)
bi: 每秒读取的块数
bo: 每秒写入的块数
系统:
in: 每秒中断数,包括时钟中断。
cs: 每秒上下文切换数。
CPU(以百分比表示):
us: 用户进程执行时间(user time)
sy: 系统进程执行时间(system time)
id: 空闲时间(包括IO等待时间),中央处理器的空闲时间 。以百分比表示。
wa: 等待IO时间
备注: 如果 r经常大于 4 ,且id经常少于40,表示cpu的负荷很重。如果pi,po 长期不等于0,表示内存不足。如果disk 经常不等于0, 且在 b中的队列 大于3, 表示 io性能不好。Linux在具有高稳定性、可靠性的同时,具有很好的可伸缩性和扩展性,能够针对不同的应用和硬件环境调整,优化出满足当前应用需要的最佳性能。因此企业在维护Linux系统、进行系统调优时,了解系统性能分析工具是至关重要的。
命令:vmstat 5 5
表示在5秒时间内进行5次采样。将得到一个数据汇总他能够反映真正的系统情况。
2.2.3.2 显示活跃和非活跃内存
命令:vmstat -a 2 5
1 | [root@localhost ~]# vmstat -a 2 5 |
说明:
使用-a选项显示活跃和非活跃内存时,所显示的内容除增加inact和active外,其他显示内容与例子1相同。
字段说明:
Memory(内存):
inact: 非活跃内存大小(当使用-a选项时显示)
active: 活跃的内存大小(当使用-a选项时显示)
2.3.3.3 查看系统已经fork了多少次
命令:vmstat –f
1 | [root@SCF1129 ~]# vmstat -f |
说明:
这个数据是从/proc/stat中的processes字段里取得的
2.3.3.4 查看内存使用的详细信息
命令:vmstat -s
1 | [root@localhost ~]# vmstat -s |
说明:
这些信息的分别来自于/proc/meminfo,/proc/stat和/proc/vmstat。
2.3.3.5 查看磁盘的读/写
命令:vmstat –d
1 | [root@localhost ~]# vmstat -d |
说明:
这些信息主要来自于/proc/diskstats.
merged:表示一次来自于合并的写/读请求,一般系统会把多个连接/邻近的读/写请求合并到一起来操作.
2.3.3.6 查看/dev/sda1磁盘的读/写
命令:vmstat -p /dev/sda1
1 | [root@SCF1129 ~]# df |
文件系统 1K-块 已用 可用 已用% 挂载点
/dev/sda3 1119336548 27642068 1034835500 3% /tmpfs 32978376 0 32978376 0% /dev/shm
/dev/sda1 1032088 59604 920056 7% /boot
1 | [root@SCF1129 ~]# vmstat -p /dev/sda1 |
说明:
这些信息主要来自于/proc/diskstats。
reads:来自于这个分区的读的次数。
read sectors:来自于这个分区的读扇区的次数。
writes:来自于这个分区的写的次数。
requested writes:来自于这个分区的写请求次数。
2.3.3.7 查看系统的slab信息
命令:vmstat –m
1 | [root@localhost ~]# vmstat -m |
这组信息来自于/proc/slabinfo。
slab:由于内核会有许多小对象,这些对象构造销毁十分频繁,比如i-node,dentry,这些对象如果每次构建的时候就向内存要一个页(4kb),而其实只有几个字节,这样就会非常浪费,为了解决这个问题,就引入了一种新的机制来处理在同一个页框中如何分配小存储区,而slab可以对小对象进行分配,这样就不用为每一个对象分配页框,从而节省了空间,内核对一些小对象创建析构很频繁,slab对这些小对象进行缓冲,可以重复利用,减少内存分配次数。
2.3 iostat
IOSTAT命令(在UBUNTU、红帽和FEDORA系统中都是由SYSSTAT软件包提供的)可以提供三个报告:CPU使用率、设备使用率和网络文件系统使用率。如果你不加任何参数地运行该命令,它会显示所有这三个报告,你可以通过加参数-c、-d和-h来单独显示它们中的一种。
2.3.1 iostat 的命令格式
iostat 用于输出CPU和磁盘I/O相关的统计信息。命令格式为:
iostat [ -c | -d ] [ -k | -m ] [ -t ] [ -V ] [ -x ] [ device [ … ] | ALL ]
[ -p [ device | ALL ] ] [ interval [ count ] ]
其中:
interval : 为取样时间间隔
count : 为输出次数,若指定了取样时间间隔且省略此项,将不断产生统计信息
常用选项:
选项 说明
-c 仅显示CPU统计信息。与-d选项互斥。
-d 仅显示磁盘统计信息。与-c选项互斥。
-k 以KB为单位显示每秒的磁盘请求数。默认单位块。
-m 以MB为单位显示每秒的磁盘请求数。默认单位块。
-p {device|ALL} 用于显示块设备及系统分区的统计信息。与-x选项互斥。
-t 在输出数据时,打印搜集数据的时间。
-V 打印版本号信息。
-x 输出扩展信息。
2.3.2 iostat 使用举例
下面给出几个例子:
2.3.2.1 显示一条包括所有的CPU和设备吞吐率的统计信息
1 | [root@localhost ~]# iostat |
2.3.2.2 每隔5秒显示一次设备吞吐率的统计信息(单位为 块/s)
1 | [root@localhost ~]# iostat -d 5 |
2.3.2.3 每隔5秒显示一次设备吞吐率的统计信息(单位为 KB/s),共输出3次
1 | [root@localhost ~]# iostat -dk 5 3 |
2.3.2.4 每隔2秒显示一次 sda 及上面所有分区的统计信息,共输出5次
1 | [root@localhost ~]# iostat -p sda 2 5 |
2.3.2.5 每隔2秒显示一次 sda 和 sdb 两个设备的扩展统计信息,共输出6次
1 | [root@localhost ~]# iostat -x sda sdb 2 6 |
iostat 的输出项说明
avg-cpu 部分输出项说明:
%user 在用户级别运行所使用的 CPU 的百分比。
%nice nice 操作所使用的 CPU 的百分比。
%system 在核心级别(kernel)运行所使用 CPU 的百分比。
%iowait CPU 等待硬件 I/O 所占用 CPU 的百分比。
%steal 当管理程序(hypervisor)为另一个虚拟进程提供服务而等待虚拟 CPU 的百分比。
%idle CPU 空闲时间的百分比。
Device 部分基本输出项说明:
tps 每秒钟物理设备的 I/O 传输总量。
Blk_read 读入的数据总量,单位为块。
Blk_wrtn 写入的数据总量,单位为块。
kB_read 读入的数据总量,单位为KB。
kB_wrtn 写入的数据总量,单位为KB。
MB_read 读入的数据总量,单位为MB。
MB_wrtn 写入的数据总量,单位为MB。
Blk_read/s 每秒从驱动器读入的数据量,单位为 块/s。
Blk_wrtn/s 每秒向驱动器写入的数据量,单位为 块/s。
kB_read/s 每秒从驱动器读入的数据量,单位为KB/s。
kB_wrtn/s 每秒向驱动器写入的数据量,单位为KB/s。
MB_read/s 每秒从驱动器读入的数据量,单位为MB/s。
MB_wrtn/s 每秒向驱动器写入的数据量,单位为MB/s。
Device 部分扩展输出项说明:
rrqm/s 将读入请求合并后,每秒发送到设备的读入请求数。
wrqm/s 将写入请求合并后,每秒发送到设备的写入请求数。
r/s 每秒发送到设备的读入请求数。
w/s 每秒发送到设备的写入请求数。
rsec/s 每秒从设备读入的扇区数。
wsec/s 每秒向设备写入的扇区数。
rkB/s 每秒从设备读入的数据量,单位为 KB/s。
wkB/s 每秒向设备写入的数据量,单位为 KB/s。
rMB/s 每秒从设备读入的数据量,单位为 MB/s。
wMB/s 每秒向设备写入的数据量,单位为 MB/s。
avgrq-sz 发送到设备的请求的平均大小,单位为扇区。
avgqu-sz 发送到设备的请求的平均队列长度。
await I/O请求平均执行时间。包括发送请求和执行的时间。单位为毫秒。
svctm 发送到设备的I/O请求的平均执行时间。单位为毫秒。
%util 在I/O请求发送到设备期间,占用CPU时间的百分比。用于显示设备的带宽利用率。当这个值接近100%时,表示设备带宽已经占满。
2.4 free
可以显示主内存和交换内存的统计量。

你可以通过添加-t参数来显示总的内存,或者通过添加-b参数和-m参数来用字节数显示(默认情况是用千字节为单位)。
FREE命令还可以通过使用-s参数来使其以某个间隔时间持续刷新地运行:
1 | [root@localhost ~]# free -s 5 |
这个命令是以每隔5秒钟刷新一次的方式运行FREE命令并输出结果。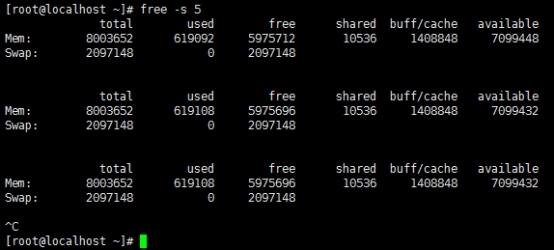
2.5 sar
要判断一个系统瓶颈问题,有时需要几个 sar 命令选项结合起来使用,例如:怀疑CPU存在瓶颈,可用 sar -u 和 sar -q deng 等来查看 怀疑内存存在瓶颈,可用 sar -B、sar -r 和 sar -W 等来查看 怀疑I/O存在瓶颈,可用 sar -b、sar -u 和 sar -d 等来查看。它比我们见过的任何类似工具都更强大,并且可以收集和显示长时间段的数据。在红帽和UBUNTU上,它通过SYSSTAT包来安装。
sysstat 是 Linux 系统中的常用工具包。它的主要用途是观察服务负载,比如CPU和内存的占用率、网络的使用率以及磁盘写入和读取速度等。
2.5.1 sysstat 工具包中包含两类工具:
- 即时查看工具:iostat、mpstat、sar
- 累计统计工具:sar
也就是说,sar 具有这两种功能。因此,sar 是 sysstat 中的核心工具。
为了实现 sar 的累计统计,系统必须周期地记录当时的信息,这是通过调用 /usr/lib/sa/ 中的三个工具实现的:
- sa1 :收集并存储每天系统动态信息到一个二进制的文件中,用作 sadc 的前端程序
- sa2 :收集每天的系统活跃信息写入总结性的报告,用作 sar 的前端程序
- sadc :系统动态数据收集工具,收集的数据被写入一个二进制的文件中,它被用作 sar 工具的后端
2.5.2 CentOS 系统的默认设置中,以如下的方式使用这三个工具:
5.2-1) 在守护进程 /etc/rc.d/init.d/sysstat 中使用 /usr/lib/sa/sadc
-F
-L
命令创建当日记录文件,文件为 /var/log/sa/saDD,其中 DD 为当天的日期。当系统重新启动后,会向文件 /var/log/sa/saDD 输出类似 11:37:16
AM LINUX
RESTART 这样的行信息。
5.2-2) 在 cron 任务 /etc/cron.d/sysstat 中每隔10分钟执行一次 /usr/lib/sa/sa1
1 1 命令,将信息写入文件 /var/log/sa/saDD
5.2-3) 在 cron 任务 /etc/cron.d/sysstat 中每天 23:53 执行一次 /usr/lib/sa/sa2
-A 命令,将当天的汇总信息写入文件 /var/log/sa/saDD
您可以修改 /etc/cron.d/sysstat 以适合您的需要。
另外,文件 /var/log/sa/saDD 为二进制文件,不能使用 more、less 等文本工具查看,必须用 sar 或 sadf 命令查看。
2.5.3 sar命令格式
在使用 Linux 系统时,常常会遇到各种各样的问题,比如系统容易死机或者运行速度突然变慢,这时我们常常猜测:是否硬盘空间不足,是否内存不足,是否 I/O 出现瓶颈,还是系统的核心参数出了问题?这时,我们应该考虑使用 sar 工具对系统做一个全面了解,分析系统的负载状况。
sar(System Activity Reporter)是系统活动情况报告的缩写。sar 工具将对系统当前的状态进行取样,然后通过计算数据和比例来表达系统的当前运行状态。它的特点是可以连续对系统取样,获得大量的取样数据;取样数据和分析的结果都可以存入文件,所需的负载很小。 sar 是目前 Linux 上最为全面的系统性能分析工具之一,可以从多方面对系统的活动进行报告,包括:文件的读写情况、系统调用的使用情况、磁盘I/O、CPU效率、内存使用状况、进程活动及IPC有关的活动等。为了提供不同的信息,sar 提供了丰富的选项、因此使用较为复杂。
sar 的命令格式
sar 的命令格式为:
sar [ -A ] [ -b ] [ -B ] [ -c ] [ -d ] [ -i interval ] [ -p ] [ -q ]
[ -r ] [ -R ] [ -t ] [ -u ] [ -v ] [ -V ] [ -w ] [ -W ] [ -y ]
[ -n { DEV | EDEV | NFS | NFSD | SOCK | ALL } ]
[ -x { pid | SELF | ALL } ] [ -X { pid | SELF | ALL } ]
[ -I { irq | SUM | ALL | XALL } ] [ -P { cpu | ALL } ]
[ -o [ filename ] | -f [ filename ] ]
[ -s [ hh:mm:ss ] ] [ -e [ hh:mm:ss ] ]
[ interval [ count ] ]
其中:
- interval : 为取样时间间隔
- count : 为输出次数,若省略此项,默认值为 1
常用选项:
选项 说明
-A 等价于 -bBcdqrRuvwWy -I SUM -I XALL -n ALL -P ALL
-b 显示I/O和传送速率的统计信息
-B 输出内存页面的统计信息
-c 输出进程统计信息,每秒创建的进程数
-d 输出每一个块设备的活动信息
-i interval 指定间隔时长,单位为秒
-p 显示友好设备名字,以方便查看,也可以和-d 和-n 参数结合使用,比如 -dp 或-np
-q 输出进程队列长度和平均负载状态统计信息
-r 输出内存和交换空间的统计信息
-R 输出内存页面的统计信息
-t 读取 /var/log/sa/saDD 的数据时显示其中记录的原始时间,如果没有这个参数使用用户的本地时间
-u 输出CPU使用情况的统计信息
-v 输出inode、文件和其他内核表的统计信息
-V 输出版本号信息
-w 输出系统交换活动信息
-W 输出系统交换的统计信息
-y 输出TTY设备的活动信息
-n {DEV|EDEV|NFS|NFSD|SOCK|ALL} 分析输出网络设备状态统计信息。
DEV 报告网络设备的统计信息
EDEV 报告网络设备的错误统计信息
NFS 报告 NFS 客户端的活动统计信息
NFSD 报告 NFS 服务器的活动统计信息
SOCK 报告网络套接字(sockets)的使用统计信息
ALL 报告所有类型的网络活动统计信息
-x {pid|SELF|ALL} 输出指定进程的统计信息。
pid 用 pid 指定特定的进程
SELF 表示 sar 自身
ALL 表示所有进程
-X {pid|SELF|ALL} 输出指定进程的子进程的统计信息
-I {irq|SUM|ALL|XALL} 输出指定中断的统计信息。
irq 指定中断号
SUM 指定输出每秒接收到的中断总数
ALL 指定输出前16个中断
XALL 指定输出全部的中断信息
-P {cpu|ALL} 输出指定 CPU 的统计信息
-o filename 将输出信息保存到文件 filename
-f filename 从文件 filename 读取数据信息。filename 是使用-o 选项时生成的文件。
-s hh:mm:ss 指定输出统计数据的起始时间
-e hh:mm:ss 指定输出统计数据的截至时间,默认为18:00:00
2.5.4 sar 使用举例
从 /var/log/sa/saDD 中读取累计统计信息
2.5.4.1 输出CPU使用情况的统计信息
1 | [root@cnetos ~]# sar |
输出项说明:
CPU all 表示统计信息为所有 CPU 的平均值。
%user 显示在用户级别(application)运行使用 CPU 总时间的百分比。
%nice 显示在用户级别,用于nice操作,所占用 CPU 总时间的百分比。
%system 在核心级别(kernel)运行所使用 CPU 总时间的百分比。
%iowait 显示用于等待I/O操作占用 CPU 总时间的百分比。
%steal 管理程序(hypervisor)为另一个虚拟进程提供服务而等待虚拟 CPU 的百分比。
%idle 显示 CPU 空闲时间占用 CPU 总时间的百分比。
注:
1.若 %iowait 的值过高,表示硬盘存在I/O瓶颈
2.若 %idle 的值高但系统响应慢时,有可能是 CPU 等待分配内存,此时应加大内存容量
3.若 %idle 的值持续低于 10,则系统的 CPU 处理能力相对较低,表明系统中最需要解决的资源是 CPU。
2.5.4.2 显示I/O和传送速率的统计信息
1 | [root@cnetos ~]# sar -b |
输出项说明:
tps 每秒钟物理设备的 I/O 传输总量
rtps 每秒钟从物理设备读入的数据总量
wtps 每秒钟向物理设备写入的数据总量
bread/s 每秒钟从物理设备读入的数据量,单位为 块/s
bwrtn/s 每秒钟向物理设备写入的数据量,单位为 块/s
2.5.4.3 输出内存页面的统计信息
1 | [root@cnetos ~]# sar -B |
输出项说明:
pgpgin/s 每秒钟从磁盘读入的系统页面的 KB 总数
pgpgout/s 每秒钟向磁盘写出的系统页面的 KB 总数
fault/s 系统每秒产生的页面失效(major + minor)数量
majflt/s 系统每秒产生的页面失效(major)数量
2.5.4.4 输出每秒创建的进程数的进程统计信息
1 | [root@cnetos ~]# sar -c |
输出项说明:
proc/s 每秒钟创建的进程数
2.5.4.5 输出网络设备状态的统计信息
1 | [root@cnetos ~]# sar -n DEV |grep eth0 |
输出项说明:
IFACE 网络设备名
rxpck/s 每秒接收的包总数
txpck/s 每秒传输的包总数
rxbyt/s 每秒接收的字节(byte)总数
txbyt/s 每秒传输的字节(byte)总数
rxcmp/s 每秒接收压缩包的总数
txcmp/s 每秒传输压缩包的总数
rxmcst/s 每秒接收的多播(multicast)包的总数
2.5.4.6 输出网络设备状态的统计信息(查看网络设备故障)
1 | [root@cnetos ~]# sar -n EDEV |egrep 'eth0|IFACE' |
输出项说明:
IFACE 网络设备名
rxerr/s 每秒接收的坏包总数
txerr/s 传输包时每秒发生错误的总数
coll/s 传输包时每秒发生冲突(collision)的总数
rxdrop/s 接收包时,由于缺乏缓存,每秒丢弃(drop)包的数量
txdrop/s 传输包时,由于缺乏缓存,每秒丢弃(drop)包的数量
txcarr/s 传输包时,每秒发生的传输错误(carrier-error)的数量
rxfram/s 接收包时,每秒发生帧校验错误(frame alignment error)的数量
rxfifo/s 接收包时,每秒发生队列(FIFO)一出错误的数量
txfifo/s 传输包时,每秒发生队列(FIFO)一出错误的数量
2.5.4.7 输出进程队列长度和平均负载状态统计信息
1 | [root@cnetos ~]# sar -q |
输出项说明:
runq-sz 运行队列的长度(等待运行的进程数)
plist-sz 进程列表中进程(processes)和线程(threads)的数量
ldavg-1 最后1分钟的系统平均负载(System load average)
ldavg-5 过去5分钟的系统平均负载
ldavg-15 过去15分钟的系统平均负载
2.5.4.8 输出内存和交换空间的统计信息
1 | [root@cnetos ~]# sar -r |
输出项说明:
kbmemfree 可用的空闲内存数量,单位为 KB
kbmemused 已使用的内存数量(不包含内核使用的内存),单位为 KB
%memused 已使用内存的百分数
kbbuffers 内核缓冲区(buffer)使用的内存数量,单位为 KB
kbcached 内核高速缓存(cache)数据使用的内存数量,单位为 KB
kbswpfree 可用的空闲交换空间数量,单位为 KB
kbswpused 已使用的交换空间数量,单位为 KB
%swpused 已使用交换空间的百分数
kbswpcad 交换空间的高速缓存使用的内存数量
2.5.4.9 输出内存页面的统计信息
1 | [root@cnetos ~]# sar -R |
输出项说明:
frmpg/s 每秒系统中空闲的内存页面(memory page freed)数量
bufpg/s 每秒系统中用作缓冲区(buffer)的附加内存页面(additional memory page)数量
campg/s 每秒系统中高速缓存的附加内存页面(additional memory pages cached)数量
2.5.4.10 输出inode、文件和其他内核表的信息
1 | [root@cnetos ~]# sar -v |
输出项说明:
dentunusd 目录高速缓存中未被使用的条目数量
file-sz 文件句柄(file handle)的使用数量
inode-sz i节点句柄(inode handle)的使用数量
super-sz 由内核分配的超级块句柄(super block handle)数量
%super-sz 已分配的超级块句柄占总超级块句柄的百分比
dquot-sz 已经分配的磁盘限额条目数量
%dquot-sz 分配的磁盘限额条目数量占总磁盘限额条目的百分比
rtsig-sz 已排队的 RT 信号的数量
%rtsig-sz 已排队的 RT 信号占总 RT 信号的百分比
2.5.4.11 输出系统交换活动信息
1 | [root@cnetos ~]# sar -w |
输出项说明:
cswch/s 每秒的系统上下文切换数量
2.5.4.12 输出系统交换的统计信息
1 | [root@cnetos ~]# sar -W |
输出项说明:
pswpin/s 每秒系统换入的交换页面(swap page)数量
pswpout/s 每秒系统换出的交换页面(swap page)数量
2.5.4.13 输出TTY设备的活动信息
1 | [root@cnetos ~]# sar -y |
输出项说明:
TTY TTY 串行设备号
rcvin/s 每秒接收的中断数量
xmtin/s 每秒传送的中断数量
framerr/s 每秒发生的帧错误数(frame error)量
prtyerr/s 每秒发生的奇偶校验错误(parity error)数量
brk/s 每秒发生的暂停(break)数量
ovrun/s 每秒发生的溢出错误(overrun error)数量
2.5.4.14 显示全面的累计统计信息
1 | sar -A |
2.5.4.15 默认配置不提供的累计统计信息
1 | [root@cnetos ~]# sar -d |
默认情况下,为了防止统计数据文件 /var/log/sa/saDD 迅速增大,/usr/lib/sa/sadc 没有记录每个块设备的统计信息。
可以在 -d -x -X 参数后添加取样参数获得即时统计信息。
带有 -x -X 选项的 sar 命令从来不能记录到二进制统计数据文件 。
2.5.5 查看即时统计信息
2.5.5.1 使用取样选项查看即时统计信息
例如:每30秒取样一次,连续取样5次
1 | # sar -n DEV 30 5 |
2.5.5.2 输出和读取统计信息文件
例如:
1 | # sar -u 30 5 -o sar-dump-001 |
2.5.5.3 输出每一个块设备的活动信息
1 | # sar -dp 5 2 |
输出项说明:
DEV 正在监视的块设备
tps 每秒钟物理设备的 I/O 传输总量
rd_sec/s 每秒从设备读取的扇区(sector)数量
wr_sec/s 每秒向设备写入的扇区(sector)数量
avgrq-sz 发给设备请求的平均扇区数
avgqu-sz 发给设备请求的平均队列长度
await 设备 I/O 请求的平均等待时间(单位为毫秒)
svctm 设备 I/O 请求的平均服务时间(单位为毫秒)
%util 在 I/O 请求发送到设备期间,占用 CPU 时间的百分比。用于体现设备的带宽利用率。
注:
avgqu-sz 的值较低时,设备的利用率较高。
当 %util 的值接近 100% 时,表示设备带宽已经占满。
你还可以长时间运行sar命令然后将输出数据导入一个文件中来收集数据。要达到这个效果,需要使用参数-o和一个文件名称,要运行该命令的时间间隔(记得收集数据会导致性能变差,所以最好确保这个间隔不要太短)和循环的次数-你要记录的间隔次数。如果你不输入循环次数,则sar命令会一直运行下去,例如:
[root@localhost ~]# sar -A -o /var/log/sar/sar.log 600 >/dev/null 2>&1 &
这里我们将收集所有数据(-A),记录到文件/var/log/sar/sar.log中,每隔600秒(或者5分钟)收集一次,持续在后台运行。如果接下来我们想要显示这个数据我们可以用sar命令加上-f参数,例如:
1 | [root@localhost ~]# sar -A -f /var/log/sar/sar.log |
2.6 iptraf –g
iptraf是一个基于ncurses开发的IP局域网监控工具,它可以实时地监视网卡流量,可以生成各种网络统计数据,包括TCP信息、UDP统计、ICMP和OSPF信息、以太网负载信息、节点统计、IP校验和错误和其它一些信息。
iptraf的参数列表
iptraf后面加上不同的参数,可以起到不同的作用,下面是iptraf的参数命令列表:
参数命令 作用
-i iface 网络接口:立即在指定网络接口上开启IP流量监视,iface为all指监视所有的网络接口,iface指相应的interface
-g 立即开始生成网络接口的概要状态信息
-d iface 网络接口:在指定网络接口上立即开始监视明细的网络流量信息,iface指相应的interface
-s iface 网络接口:在指定网络接口上立即开始监视TCP和UDP网络流量信息,iface指相应的interface
-z iface 网络接口:在指定网络接口上显示包计数,iface指相应的interface
-l iface 网络接口:在指定网络接口上立即开始监视局域网工作站信息,iface指相应的interface
-t timeout 时间:指定iptraf指令监视的时间,timeout指监视时间的minute数
-B 将标注输出重新定向到“/dev/null”,关闭标注输入,将程序作为后台进程运行
-L logfile 指定一个文件用于记录所有命令行的log,默认文件是地址:/var/log/iptraf
-I interval 指定记录log的时间间隔(单位是minute),不包括IP traffic monitor
-u 允许使用不支持的接口作为以太网设备
-f 清空所有计数器
-h 显示帮助信息
使用iptraf之后的菜单选项
首先,输入iptraf出现如下图所示界面:
点击“Enter”键继续,进入下图内容:
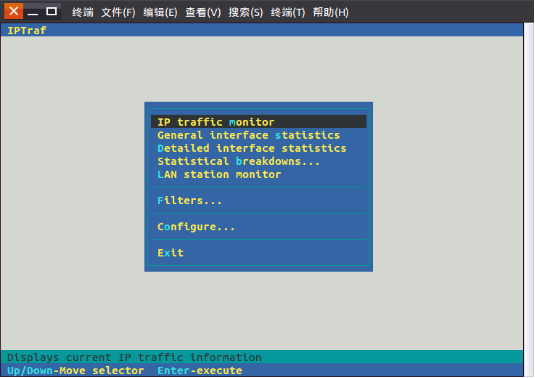
2.6.1 Configure
在总菜单命令中点击“Configure” menu,即进入如下命令菜单:
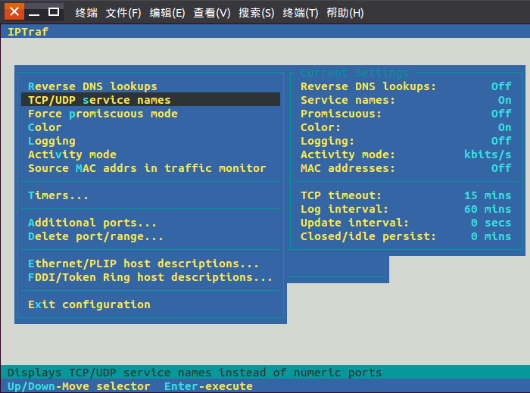
这个非常重要,进行适当的配置可以让统计的结果更直观,信息更丰富。
1)Reverse DNS lookups:查看连接的ip所对应的域名,在IP traffic monitor的pkt captured对话框中就可以看到域名结果,这个不是很直观,开启后会有点点影响抓包性能。
2)TCP/UDP service names:在有端口的地方都会把端口号换成相应的服务名,非常有用,很直观。
3)Activity mode:显示流量是按Kbits/s还是Kbytes/s,建议改成后面的更符合习惯。
4)Additional ports:按端口号监控所额外需要监控的端口,默认只监控小于1024的。
2.6.2 Filters
这个默认就行了,除非你有特殊需要。
点击“Filter”进入如下图所示界面:
2.6.3 IP traffic monitor
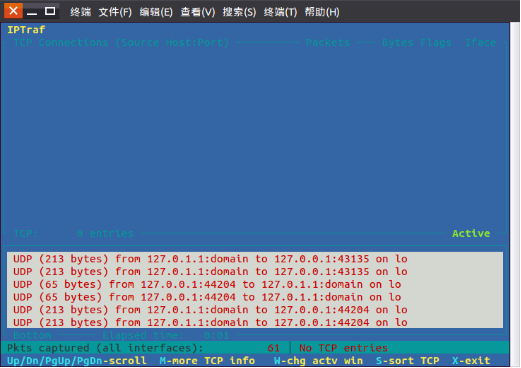
根据连接查看网络流量,这个最好让他跑一段时间看统计总量的结构,如果单个连接占用大量带宽,就很容易看出来。同时根据IP还可以很容易分辨是和内网还是外网服务器进行交互。pkt captured可以看到mac地址。
点击“IP traffic monitor”进入下图select界面,
点击可选项,进入视图界面:
2.6.4 General interface statistics
查看每个网卡上的流量,注意一下,这个是网卡流量,包括内网和外网,单机是无法分辨内外网。
点击“General interface statistics”进入如下图界面:
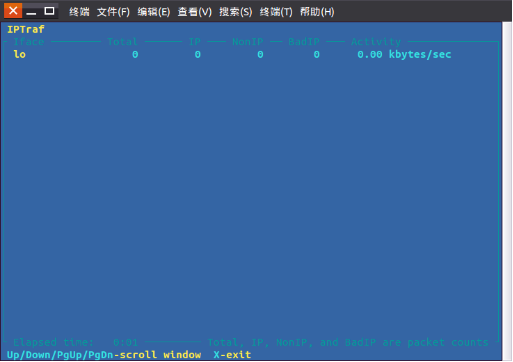
2.6.5 Detailed interface statistics
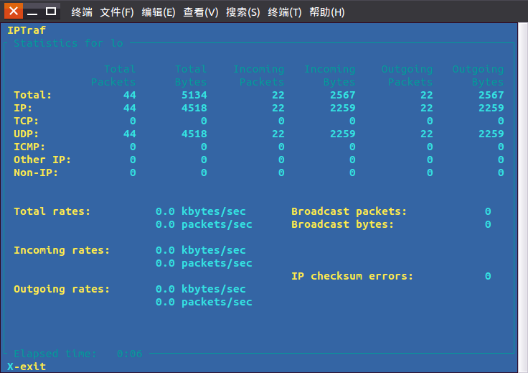
根据协议进行统计,就只有IP, TCP, UDP等几个,感觉用处不大。
点击“Detailed interface statistics”进入下图select界面,
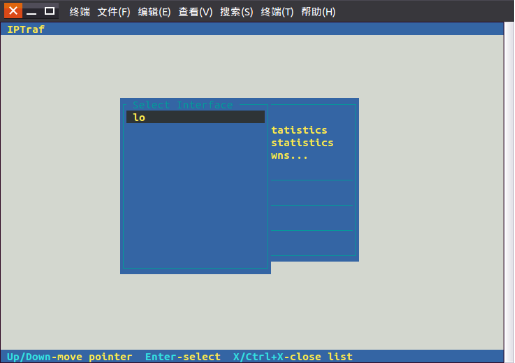
点击可选项,进入视图界面:
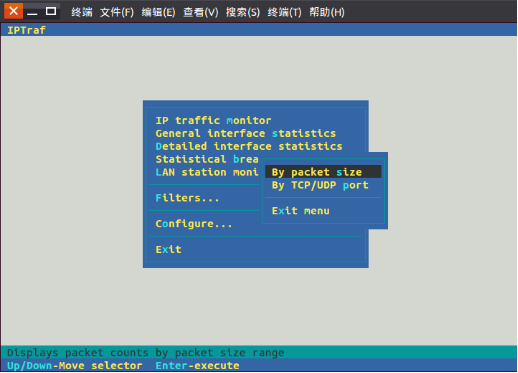
2.6.6 Statistical breakdowns
1) By packet size:根据传输包的大小进行统计。
2) By TCP/UDP port:根据应用协议进行统计,比Detailed interface statistics更实用。
点击“Statistical breakdowns”出现可选菜单:
2.6.7 LAN station monitor
根据mac地址统计。
点击“LAN station monitor”出现可选菜单:
2.7 mpstat
2.7.1 mpstat 的命令格式
mpstat 输出每一个 CPU 的运行状况,为多处理器系统中的 CPU 利用率提供统计信息。命
令格式为:
mpstat [ -P { cpu | ALL } ] [ -V ] [ interval [ count ] ]
其中:
- interval : 为取样时间间隔。指定0则输出自系统启动后的一个统计信息。
- count : 为输出次数。若指定了取样时间间隔且省略此项,将不断产生统计信息。
常用选项:
选项 说明
-P {cpu|ALL} 指定 CPU。用 CPU-ID 指定,CPU-ID 是从0开始的,即第一个CPU为0。ALL 表示所有CPU。
-V 输出版本号信息。
2.7.2 mpstat 使用举例
下面给出几个例子:
2.7.2.1 输出所有 CPU 使用情况的统计信息。
1 | [root@localhost ~]# mpstat |
2.7.2.2 输出第一个 CPU 使用情况的统计信息。
1 | [root@localhost ~]# mpstat -P 0 |
2.7.2.3 每隔2秒输出所有CPU的统计信息,共输出5次。
1 | [root@localhost ~]# mpstat 2 5 |
2.7.2.4 每隔2秒输出一次所有CPU的统计信息,共输出5次。
1 | [root@localhost ~]# mpstat -P ALL 2 5 |
2.7.2.5 每隔2秒输出一次第二个CPU的统计信息,共输出5次。
1 | [root@localhost ~]# mpstat -P 1 2 5 |
mpstat 输出项说明
CPU 在多CPU系统里,每个CPU有一个ID号,第一个CPU为0。all表示统计信息为所有CPU的平均值。
%user 显示在用户级别运行所占用CPU总时间的百分比。
%nice 显示在用户级别,用于nice操作,所占用CPU总时间的百分比。
%sys 显示在kernel级别运行所占用CPU总时间的百分比。注意:这个值并不包括服务中断和softirq。
%iowait 显示用于等待I/O操作时,占用CPU总时间的百分比。
%irq 显示用于中断操作,占用CPU总时间的百分比。
%soft 显示用于softirq操作,占用CPU总时间的百分比。
%steal 管理程序(hypervisor)为另一个虚拟进程提供服务而等待虚拟 CPU 的百分比。
%idle 显示CPU在空闲状态,占用CPU总时间的百分比。
intr/s 显示CPU每秒接收到的中断总数。
2.8 其它查看性能相关命令
Linux系统出现问题时,我们不仅需要查看系统日志信息,而且还要使用大量的性能监测工
具来判断究竟是哪一部分(内存、CPU、硬盘……)出了问题。在Linux系统中,所有的运行
参数保存在虚拟目录/proc中,换句话说,我们使用的性能监控工具取到的数据值实际上就
是源自于这个目录,当涉及到系统高估时,我们就可以修改/proc目录中的相关参数了,当
然有些是不能乱改的。下面就让我们了解一下这些常用的性能监控工具。工具功能描述uptime—-系统平均负载率
dmesg—-硬件/系统信息
top—–进程进行状态
iostat——–CPU和磁盘平均使用率
vmstat———系统运行状态
sar———实时收集系统使用状态
KDESystemGuard—图形监控工具
free—————内存使用率
traffic-vis————网络监控(只有SUSE有)
pmap————-进程内存占用率
strace———追踪程序运行状态
limit———系统资源使用限制
mpstat————-多处理器使用率