一、Alluxio概览
1.1 什么是 Alluxio
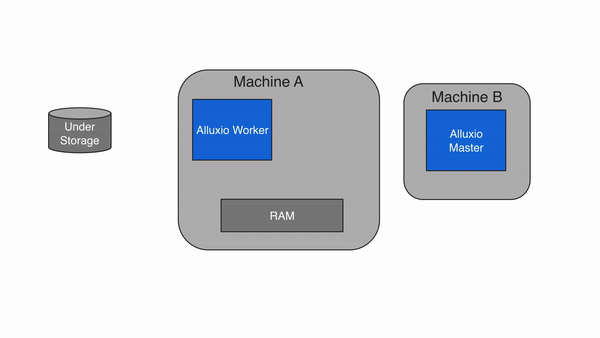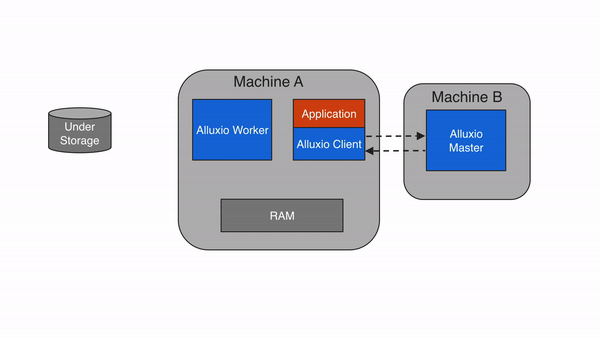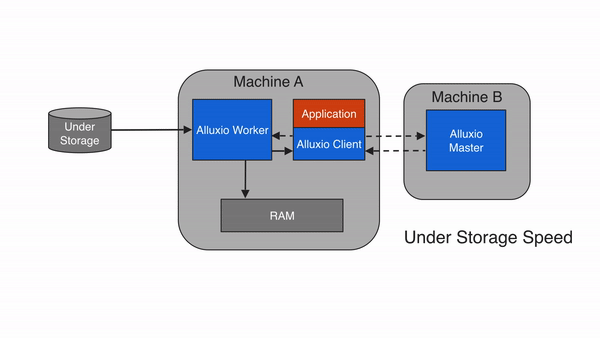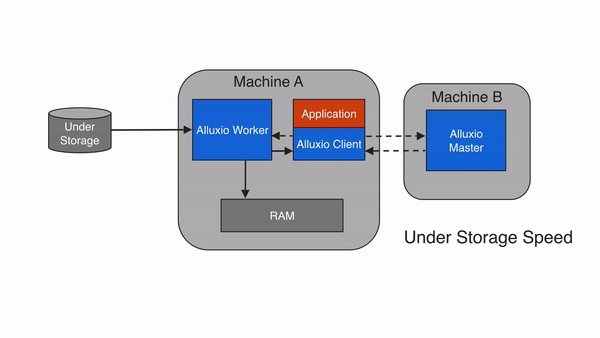
Alluxio(之前名为 Tachyon)是一个开源的具有内存级速度的虚拟分布式存储系统。它统一了数据访问的方式,为上层计算框架和底层存储系统构建了桥梁。应用只需要连接Alluxio即可访问存储在底层任意存储系统中的数据。此外,Alluxio的以内存为中心的架构使得数据的访问速度能比现有常规方案快几个数量级。
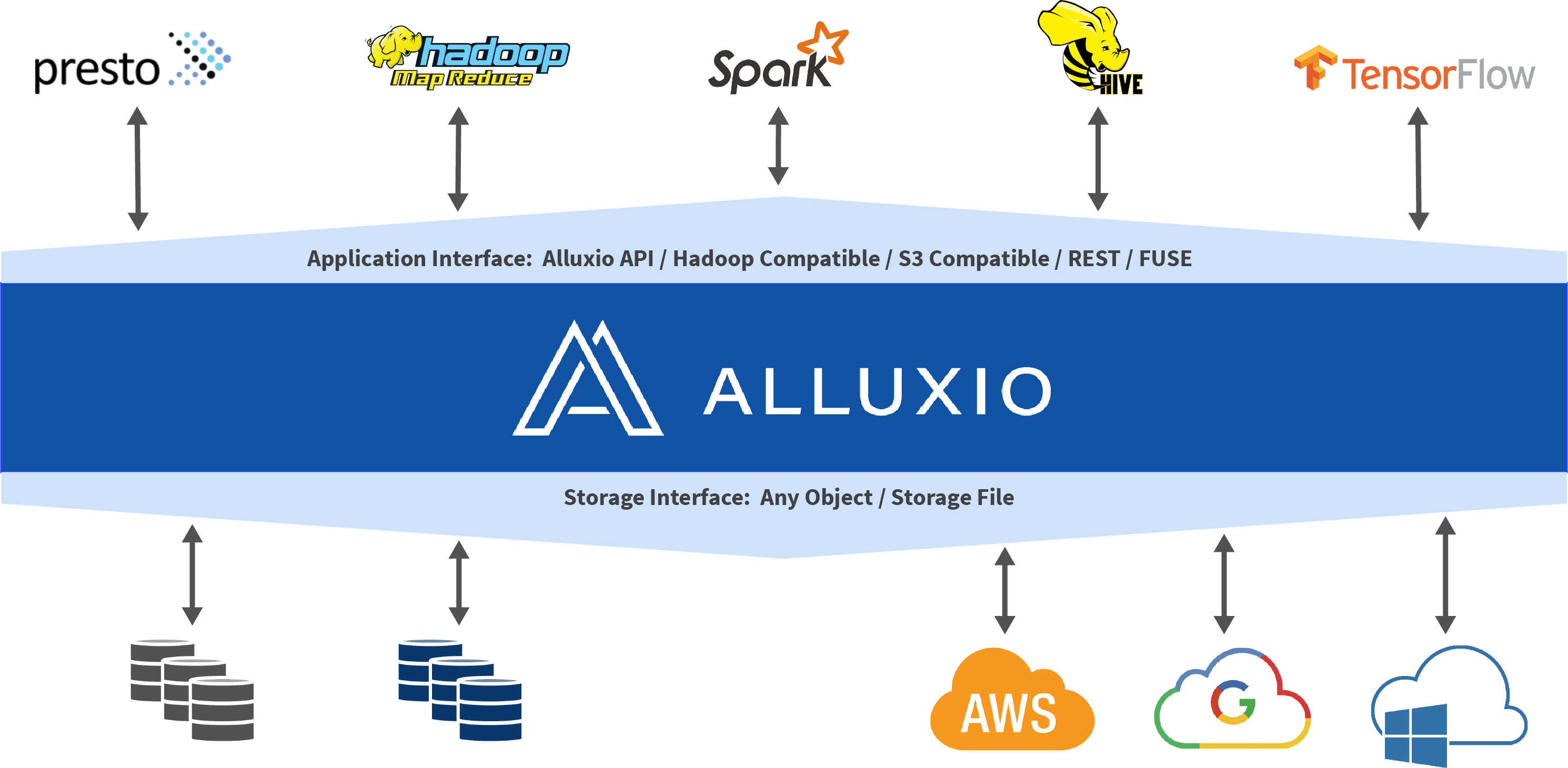
在大数据生态系统中,Alluxio 位于数据驱动框架或应用(如 Apache Spark、Presto、Tensorflow、Apache HBase、Apache Hive 或 Apache Flink)和各种持久化存储系统(如 Amazon S3、Google Cloud Storage、OpenStack Swift、HDFS、GlusterFS、IBM Cleversafe、EMC ECS、Ceph、NFS 、Minio和 Alibaba OSS)之间。 Alluxio 统一了存储在这些不同存储系统中的数据,为其上层数据驱动型应用提供统一的客户端 API 和全局命名空间。用户可以以独立集群方式(如Amazon EC2)运行Alluxio,也可以从Apache Mesos或Apache YARN上启动Alluxio。
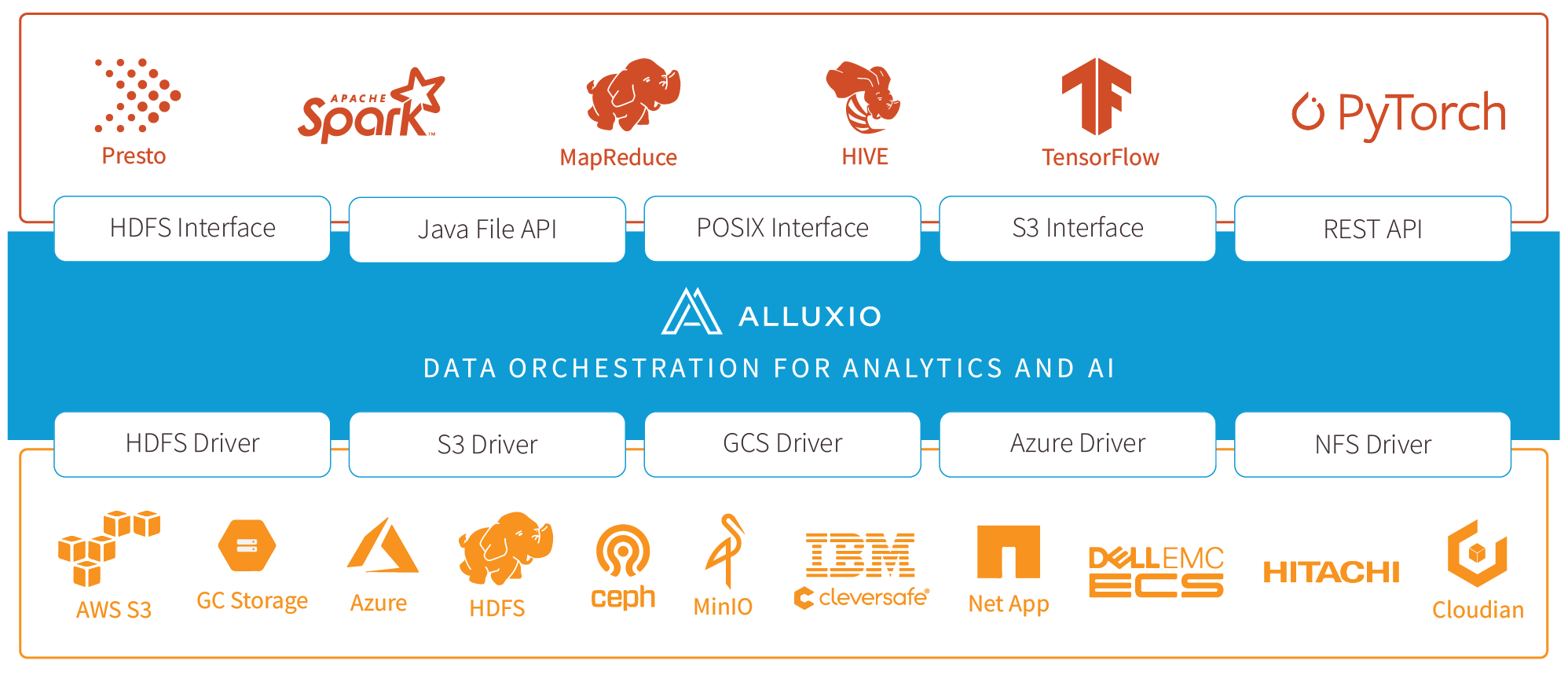
Alluxio作为一个内存级的虚拟分布式存储系统有几个常见的使用场景:
- 计算层需要反复访问远程(比如在云端,或跨机房)的数据;
- 计算层需要同时访问多个独立的持久化数据源(比如同时访问S3和HDFS中的数据);
- 多个独立的大数据应用(比如不同的Spark Job)需要高速有效的共享数据;
- 当计算层有着较为严重的内存资源、以及JVM GC压力,或者较高的任务失败率时,Alluxio作为输入输出数据的Off heap存储可以极大缓解这一压力,并使计算消耗的时间和资源更可控可预测。
Alluixo利用的是堆内内存,如果不符合典型场景,用起来就是鸡肋!
Ignite是堆外内存,真正加速任务
1.2 Alluxio的优势
通过简化应用程序访问其数据的方式(无论数据是什么格式或位置),Alluxio能够帮助克服从数据中提取信息所面临的困难。Alluxio的优势包括:
1.2.1 内存速度 I/O
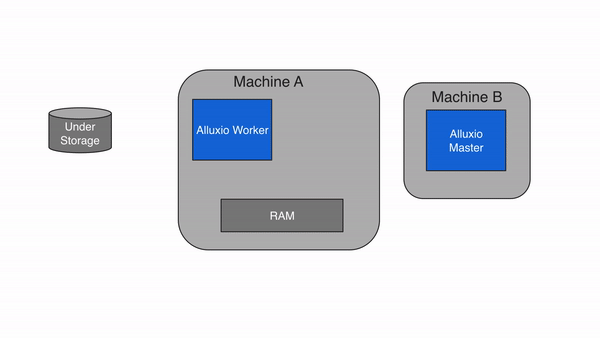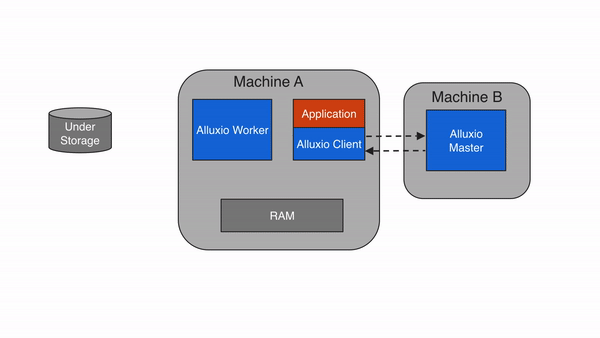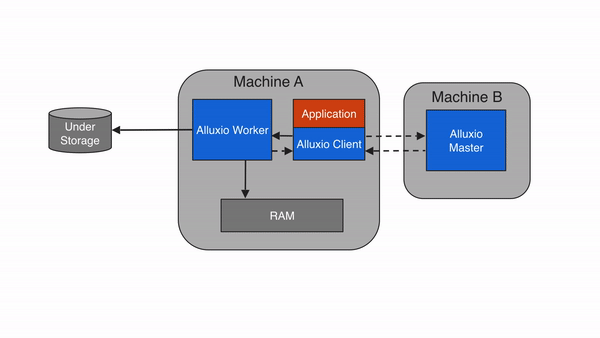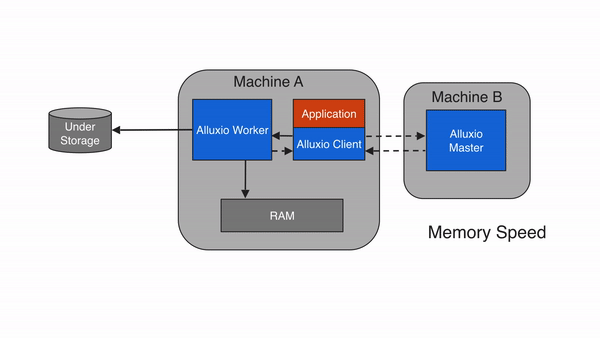
Alluxio 能够用作分布式共享缓存服务,这样与 Alluxio 通信的计算应用程序可以透明地缓存频繁访问的数据(尤其是从远程位置),以提供内存级 I/O 吞吐率。此外,Alluxio的层次化存储机制能够充分利用内存、固态硬盘或者磁盘,降低具有弹性扩张特性的数据驱动型应用的成本开销。
1.2.2 统一数据访问接口
Alluxio 能够屏蔽底层持久化存储系统在API、客户端及版本方面的差异,从而使整个系统易于扩展和管理。
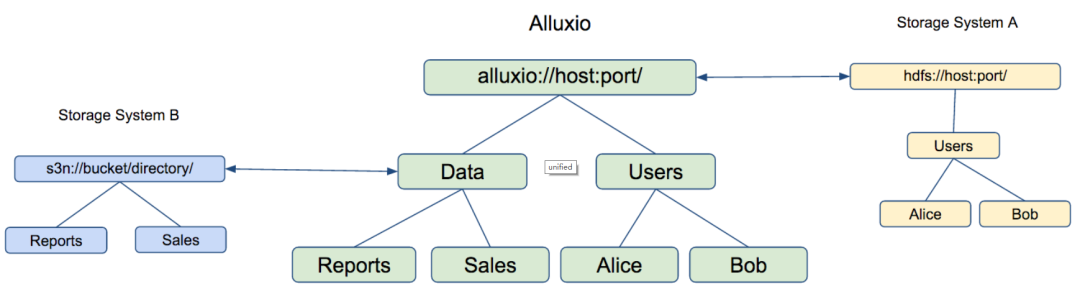
- 能够将多个数据源中的数据挂载到Alluxio中
- 多个数据源使用统一的命名空间
- 用户使用统一的路径访问
1.2.3 提升远程存储读写性能
以Hadoop为代表的存储计算紧耦合的传统架构具有优良的计算本地性。通过在邻近所需数据的节点上来部署运行计算任务,可以尽量减少通过网络传输数据,从而有效地提升性能。然而,维持这种紧耦合结构所需要付出的成本代价正逐渐让性能优势带来的意义变得微乎其微。
Alluxio通过在当前主流的存储计算分离解耦的架构中,提供与紧耦合架构相似甚至更优的性能,来解决解耦后性能降低的难题。推荐把Alluxio与集群的计算框架并置部署(co-locate),从而能够提供靠近计算的跨存储缓存来实现高效本地性。
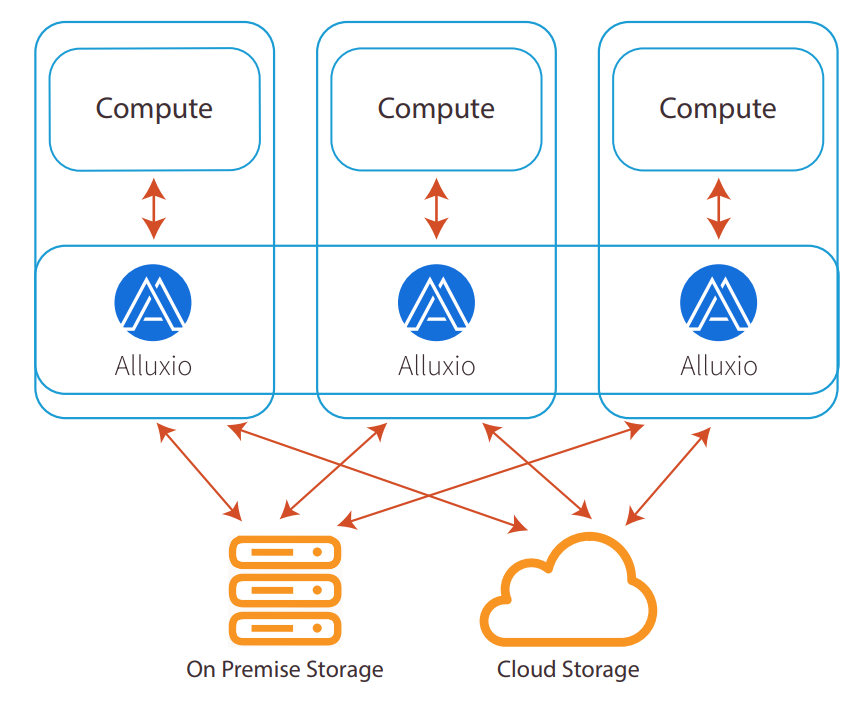 与传统的架构方案相比,用户需要注意采用Alluxio架构带来的两个关键区别。
与传统的架构方案相比,用户需要注意采用Alluxio架构带来的两个关键区别。
- Alluxio存储中不需要保存底层存储中的所有数据,它只需要保存工作集(WorkingSet)。即使全体数据的规模非常大,Alluxio也不需要大量存储空间来存储所有数据,而是可以在有限的存储空间中只缓存作业所需要的数据。
- Alluxio存储采用了一种弹性的缓存机制来管理、使用存储资源。访问热度越高的数据(如被很多作业读取的数据表),会产生越多的副本,而请求很少甚至没有复用的数据则会被逐渐替换出Alluxio存储层(其在远端存储系统中的副本不会被清除)。而以HDFS为代表的存储系统通常是采用一个固定的副本数目(如3副本),很难根据具体的数据访问热度动态调节存储资源的使用。
1.2.4 数据快速复用与共性
Alluxio可以帮助实现跨计算、作业间的数据快速复用和共享。
对于用户应用程序和大数据计算框架来说,Alluxio存储通常与计算框架并置。这种部署方式使Alluxio可以提供快速存储,促进作业之间的数据共享,无论它们是否在同一计算平台上运行。
1.2.5 集成机器学习和深度学习
机器学习和深度学习框架往往需要从Hadoop或对象存储中提取大规模数据,这通常是手动且非常耗时的过程。通过Alluxio POSIX API克服该问题。
Alluxio的FUSE功能支持POSIX兼容的API,因此通过Alluxio,TensorFlow、 Caffe等框架以及其他基于Python的模型可以使用传统文件系统的访问方式直接访问任何存储系统中的数据。
1.3 技术创新
Alluxio将三个关键领域的创新结合在一起,提供了一套独特的功能。
- 全局命名空间: Alluxio 能够对多个独立存储系统提供单点访问,无论这些存储系统的物理位置在何处。这提供了所有数据源的统一视图和应用程序的标准接口。有关详细信息,请参阅命名空间管理。
- 智能多层级缓存: Alluxio 集群能够充当底层存储系统中数据的读写缓存。可配置自动优化数据放置策略,以实现跨内存和磁盘(SSD/HDD)的性能和可靠性。缓存对用户是透明的,使用缓冲来保持与持久存储的一致性。有关详细信息,请参阅 Alluxio存储管理。
- 服务器端 API 翻译转换: Alluxio支持工业界场景的API接口,例如HDFS API, S3 API, FUSE API, REST API。它能够透明地从标准客户端接口转换到任何存储接口。Alluxio 负责管理应用程序和文件或对象存储之间的通信,从而消除了对复杂系统进行配置和管理的需求。文件数据可以看起来像对象数据,反之亦然。
1.4 功能简介
- 灵活的API
- 兼容Haddop 的HDFS文件系统接口
- 分级存储,自定义分配和回收策略
- 统一命名空间
- 完整的命令行
- Web UI
二、系统架构
2.1 概述
Alluxio作为大数据和机器学习生态系统中的一个新的数据访问层,配置在任何持久性存储系统(如Amazon S3、Microsoft Azure对象存储、Apache HDFS或OpenStack Swift)和计算框架(如Apache Spark、Presto或Hadoop MapReduce)之间。请注意,Alluxio不是一个持久化存储系统。使用Alluxio作为数据访问层有如下好处:
- 对于用户应用程序和计算框架,Alluxio提供了快速存储,促进了作业之间的数据共享和局部性,而不管使用的是哪种计算引擎。因此,当数据位于本地时,Alluxio可以以内存速度提供数据;当数据位于Alluxio时,Alluxio可以以计算集群网络的速度提供数据。第一次访问数据时,只从存储系统上读取一次数据。为了得到更好的性能,Alluxio推荐部署在计算集群上。
- 对于存储系统,Alluxio弥补了大数据应用与传统存储系统之间的差距,扩大了可用的数据工作负载集。当同时挂载多个数据源时,Alluxio可以作为任意数量的不同数据源的统一层。
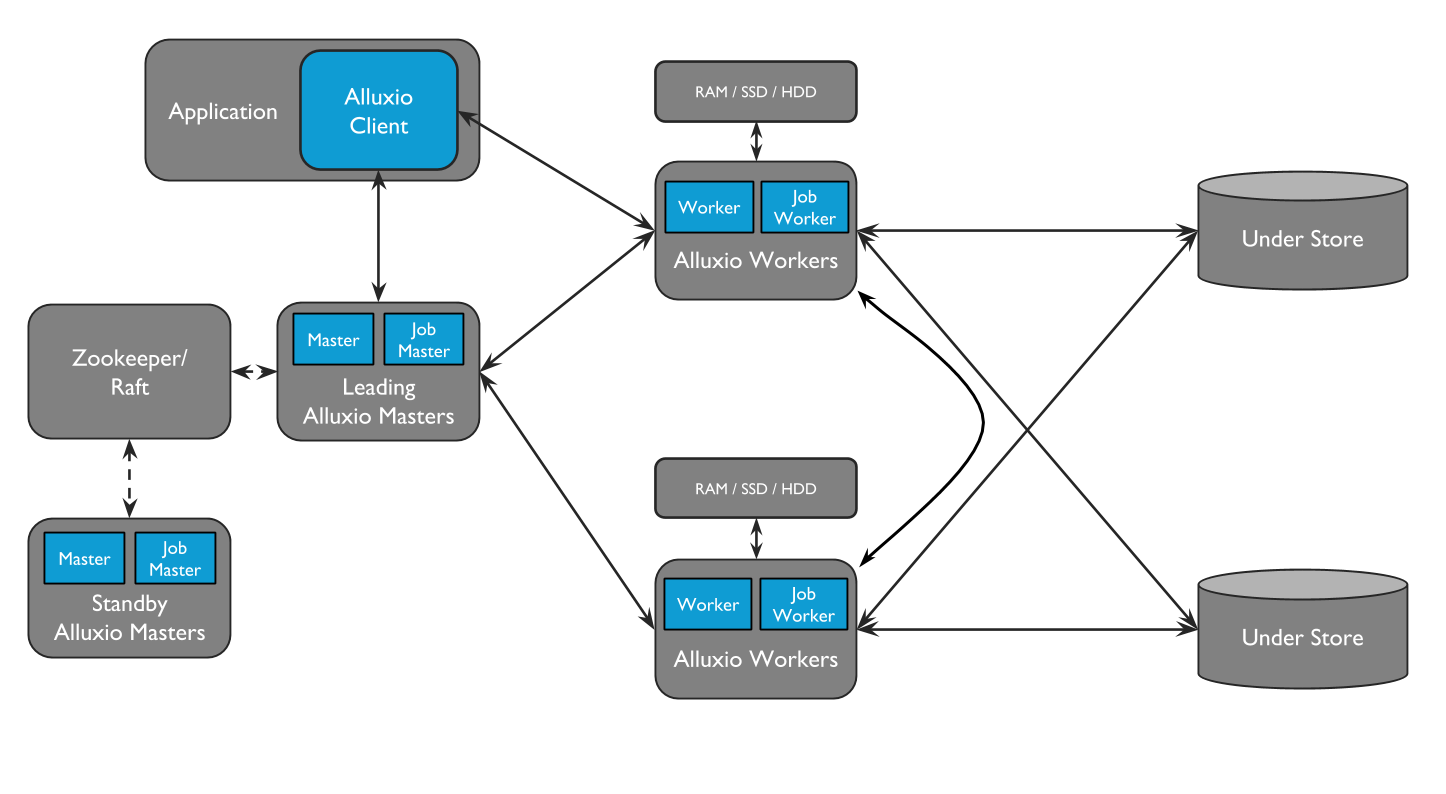
Alluxio可以分为三个组件:masters、worker和clients。一个典型的集群由一个单一的主要主节点leading masters、备用主节点job master、一个作业主节点standby job masters、备用作业主节点standby job masters、工作节点workers和作业工作节点job workers组成。master 和 worker 进程构成了 Alluxio 服务器,它们是系统管理员需要维护的组件。客户端用于通过 Spark 或 MapReduce 作业、Alluxio CLI 或 Alluxio FUSE 层等应用程序与 Alluxio 服务器通信。
Alluxio Job Masters 和 Job Workers 可以分离成一个单独的功能,称为 Job Service。Alluxio Job Service 是一个轻量级的任务调度框架,负责为 Job Workers 分配许多不同类型的操作。这些任务包括
- 从 UFS 加载数据到 Alluxio
- 将数据持久化到 UFS
- 在 Alluxio 中复制文件
- 在 UFS 或 Alluxio 位置之间移动或复制数据
Job Service的设计使得所有与作业相关的进程不一定需要位于 Alluxio 集群的其余部分。但是,我们确实建议job worker 与相应的 Alluxio worker 位于同一位置,因为它为 RPC 和数据传输提供了更低的延迟。
2.2 Mstaers
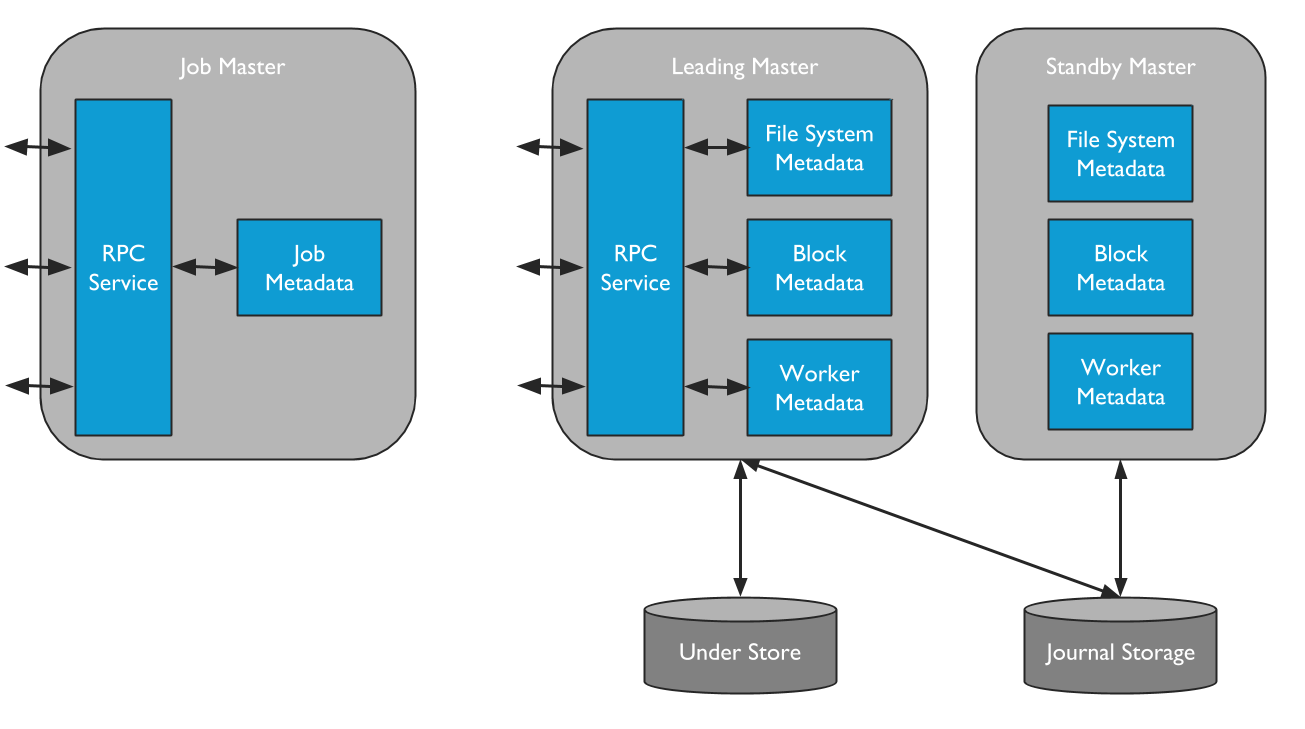
Alluxio 包含两种不同类型的主进程。Alluxio Master 为所有用户请求和日志文件系统元数据更改提供服务。Alluxio Job Master是作为文件系统操作的轻量级调度程序。
为了容错,Alluxio Master可以部署为一个主master和多个备用master。当主master节点宕机时,会选举一个备用master节点成为新的主master节点。
2.2.1 主master
Alluxio中只有一个master进程为主master。主master用于管理全局的元数据。这里面包含文件系统元数据(文件系统 inode 树)、数据块元数据(数据块位置)、以及worker的容量元数据(空闲或已占用空间)。Alluxio clients与主master通信用来读取或修改元数据。所有的worker都会定期的向主master发送心跳。主master会在一个分布式的持久化系统上记录所有的文件系统事务,这样可以恢复主master的信息。这组日志被称为journal。
2.2.2 备用master
备用master读取主master写入的journal日志,以保持与主master的状态同步。它们会对journal日志写入检查点,用于快速恢复。它们不处理来自Alluxio组件的任何请求。
2.2.3 Secondary Masters (for UFS journal)
当使用 UFS 日志在没有 HA 模式的情况下运行单个 Alluxio master 时,可以在与主要 master 相同的服务器上启动辅助 master 来写入日志检查点。请注意,辅助 master 并非旨在提供高可用性,而是从主要 master 卸载工作以实现快速恢复。与备用 Master 不同,从属 Master 永远无法升级为领先的 Master。
2.2.4 Job Masters
Alluxio Job Master 是一个独立的进程,负责在 Alluxio 中异步调度多个重量级文件系统操作。通过分离领先的 Alluxio Master 在同一进程中执行这些操作,Alluxio Master 使用更少的资源,并能够在更短的时间内为更多的客户端提供服务。此外,它还为将来添加更复杂的操作提供了一个可扩展的框架。
2.3 Workers
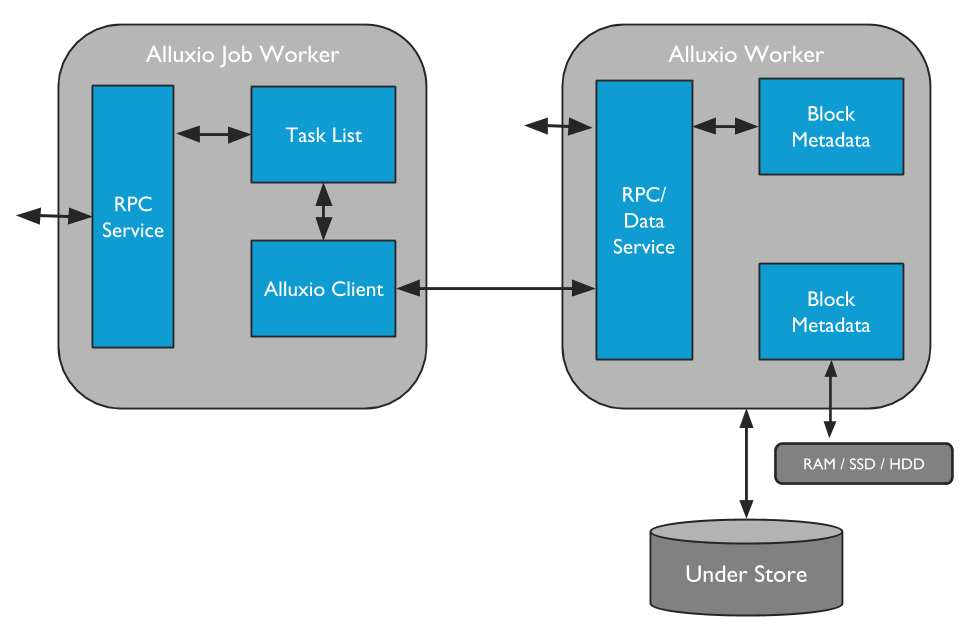
2.3.1 Alluxio Workers
Alluxio Workers 负责管理分配给 Alluxio 的用户可配置的本地资源(例如内存、SSD、HDD)。Alluxio Worker将数据存储为块,并通过在其本地资源中读取或创建新块来响应 client 请求。Workers 只用于管理数据块;从文件到块的实际映射仅由 master 存储。
Worker 在底层存储上执行数据操作。这带来了两个重要的好处:
- 从底层存储读取的数据可以存储在 worker 中,并立即可供其他 client 使用。
- client 可以是轻量级的,并且不依赖于底层存储连接器。
由于 RAM 通常提供的容量有限,因此当空间已满时,可以逐出 worker 中的块。工作人员采用驱逐策略来决定将哪些数据保留在 Alluxio 空间中。有关此主题的更多信息,请查看分层存储的文档。
2.3.2 Alluxio Job Workers
Alluxio Job Workers 是 Alluxio 文件系统的客户端。他们负责运行 Alluxio Job Master 交给他们的任务。Job Workers 接收指令以在任何给定的文件系统位置上运行加载、持久化、复制、移动或复制操作。
Alluxio job workers 不一定要与普通 workers 位于同一位置,但建议两者在同一个物理节点上。
2.4 Client
Alluxio Client 为用户提供了一个与 Alluxio 服务器交互的网关。它发起与 leading master 通信以执行元数据操作,并与 worker 通信以读取和写入存储在 Alluxio 中的数据。Alluxio 支持 Java 中的本机文件系统 API 和多种语言(包括 REST、Go 和 Python)。Alluxio 还支持与 HDFS API 和 Amazon S3 API 兼容的 API。
请注意,Alluxio Client 从不直接访问底层存储系统。数据通过 Alluxio Workers 传输。
alluxio服务的几个组件功能总结
组件名称 作用 Master 1.管理全局的元数据信息(包括目录树(inode tree),块信息(block),worker的容量信息);2.worker发送心跳;3.client获取元数据 SecondaryMaster 1.读取主master写入的journal日志,以保持与主master的状态同步;2.对journal日志写入检查点,用于快速恢复;3.不处理来自Alluxio组件的任何请求 JobMaster 1.负责在Alluxio中异步调度许多重量级文件系统操作,提高master吞吐量;2.为后期复杂操作提供扩展性 Worker 1.底层数据存储在worker中供客户端使用;2.alluxio客户端不依赖底层存储 JobWorker 执行job master分配的任务,建议与worker放在同一节点上 Client 集成到其他计算框架中,调用Alluxio leading master以执行元数据操作,与 workers 通信以读取和写入存储在 Alluxio 中的数据
2.5 读数据流
Alluxio 位于底层存储和计算框架之间,充当数据读取的缓存层。
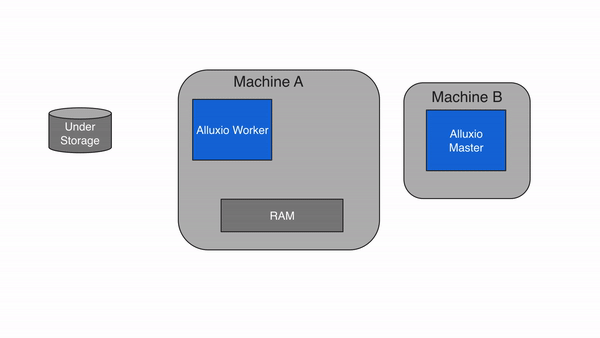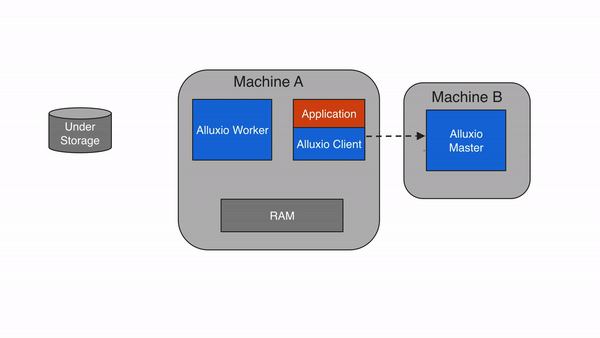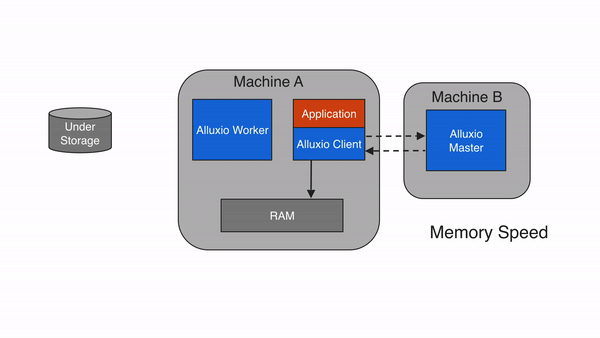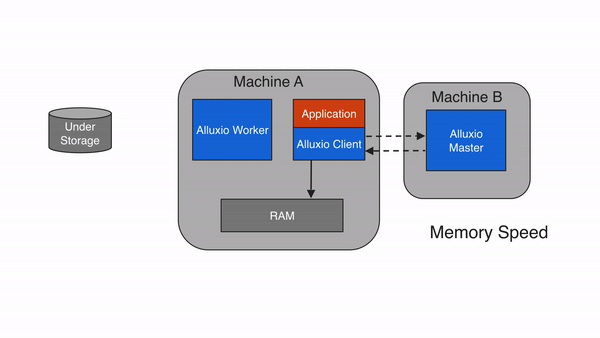
2.5.1 本地缓存命中
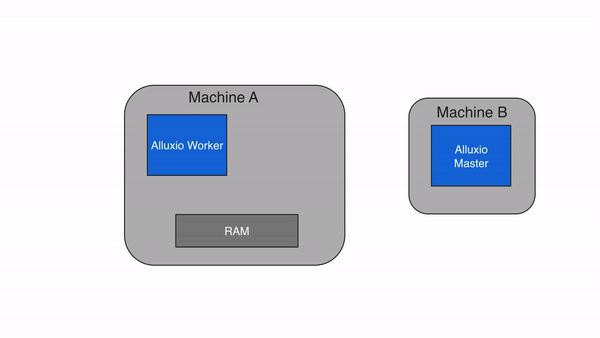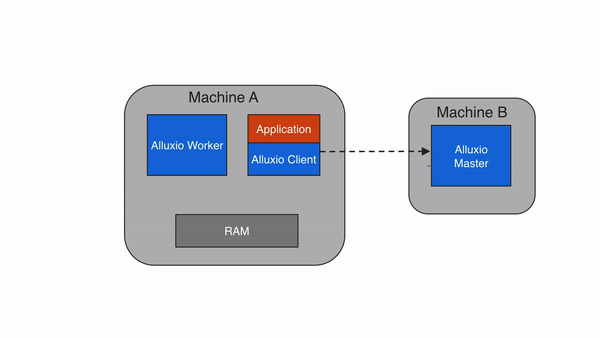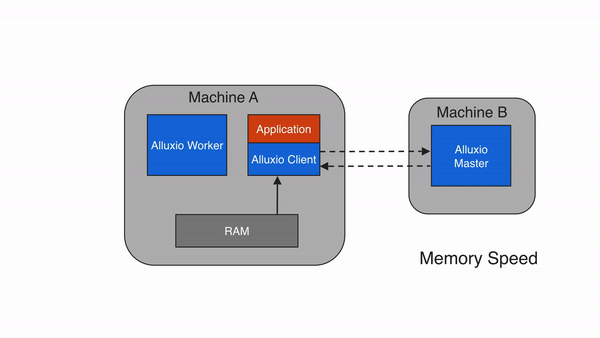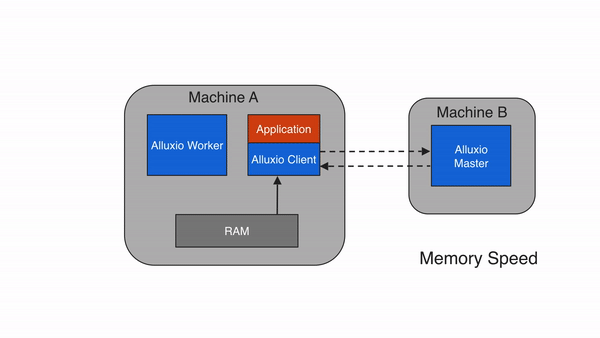
本地缓存命中发生在请求数据位于本地Alluxio worker。举例说明,如果一个应用通过Alluxio client请求数据,client向Alluxio master请求数据所在的worker。如果数据在本地可用,Alluxio client使用短路读取来绕过Alluxio worker,并直接通过本地文件系统读取文件。短路读取避免通过TCP套接字传输数据,并提供数据的直接访问。
还要注意,Alluxio可以管理除了内存之外还可以管理其他存储介质(例如SSD、HDD),因此本地数据访问速度可能会因本地存储介质的不同而有所不同。
2.5.2 远程缓存命中
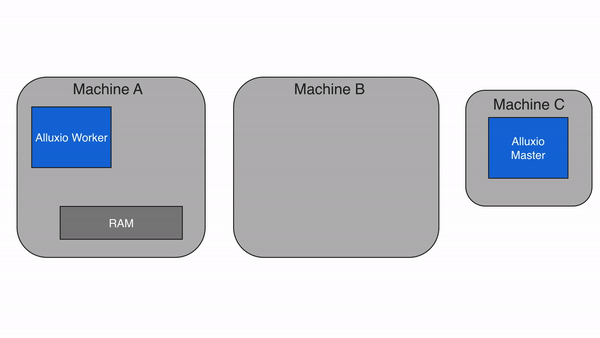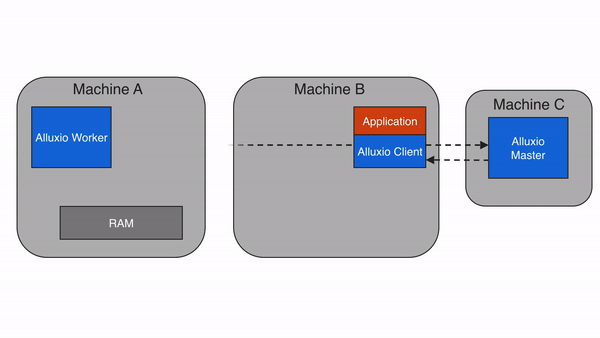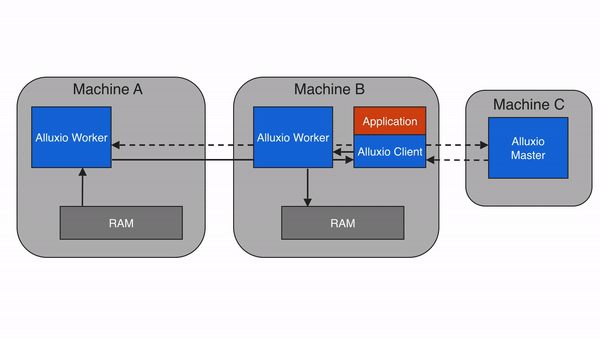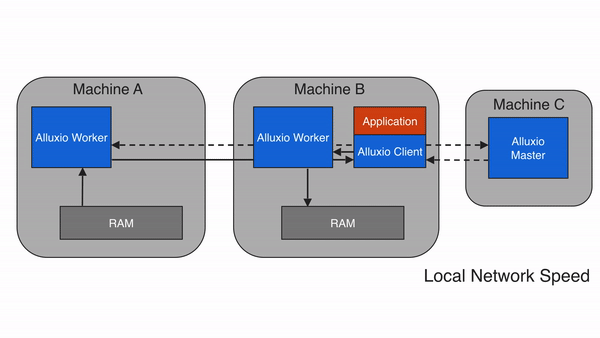
当请求的数据存储在Alluxio中,而不是存储在client的本地worker上时,client将对具有数据的worker进行远程读取。client完成读取后,会要求本地的worker(如果存在)创建一个copy,这样以后读取的时候可以在本地读取相同的数据。远程缓存命中提供了网络级别速度的数据读取。Alluxio优先从远程worker读取数据,而不是从底层存储,因为Alluxio workers之间的速度一般会快过Alluxio workers和底层存储的速度。
2.5.3 缓存Miss
如果数据在 Alluxio 中找不到,则会发生缓存未命中,应用程序将不得不从底层存储中读取数据。Alluxio client 将读取从 UFS 委托给worker(有限本地worker)。该worker从底层存储中读取和缓存数据。缓存未命中通常会导致最大的延迟,因为必须从底层存储中获取数据。首次读取数据时预计会发生缓存未命中。
当 client 仅读取块的一部分或非顺序读取块时,client 将指示worker异步缓存完整个块。这称为异步缓存。异步缓存不会阻塞client,但如果 Alluxio 和底层存储系统之间的网络带宽成为瓶颈,仍然可能会影响性能。您可以通过alluxio.worker.network.async.cache.manager.threads.max对worker进行设置来调整异步缓存的影响 。默认值为8。
2.5.4 缓存跳过
可以通过将alluxio.user.file.readtype.default client中的属性设置为 NO_CACHE 来关闭 Alluxio 中的缓存。
2.6 写数据流
用户可以通过选择不同的写入类型来配置数据的写入方式。写入类型可以通过 Alluxio API 或通过配置属性 alluxio.user.file.writetype.default 来设置写入类型。
2.6.1 仅写入 Alluxio ( MUST_CACHE)
当写类型设置为MUST_CACHE,Alluxio client将数据写入本地Alluxio worker,而不会写入到底层存储。如果短路写可用,Alluxio client直接写入到本地RAM的文件,绕过Alluxio worker 避免网络传输。由于数据没有持久存储在under storage中,因此如果机器崩溃或需要释放数据以进行更新的写操作,数据可能会丢失。当可以容忍数据丢失时,MUST_CACHE 设置可用于写入临时数据。
2.6.2 直写到 UFS ( CACHE_THROUGH)
使用CACHE_THROUGH写类型,数据同步写入Alluxio worker和底层存储系统。Alluxio client将写操作委托给本地worker,而worker同时将对本地内存和底层存储。由于底层存储的写入速度通常比本地存储慢,所以client的写入速度将与底层存储的速度相匹配。当需要数据持久化时,建议使用CACHE_THROUGH写类型。在本地还存了一份副本,以便可以直接从本地内存中读取数据。
2.6.3 写回 UFS ( ASYNC_THROUGH)
Alluxio 提供了一种写类型ASYNC_THROUGH. 使用ASYNC_THROUGH,数据首先被同步写入一个 Alluxio worker,并在后台持久化到 under storage。ASYNC_THROUGH可以以接近 MUST_CACHE 的速度提供数据写入,同时仍然能够持久保存数据。从 Alluxio 2.0 开始, ASYNC_THROUGH是默认的写入类型。
为了提供容错,使用的一个重要属性ASYNC_THROUGH是 alluxio.user.file.replication.durable 该属性设置了Alluxio在写入完成后数据持久化到under storage之前的新数据的目标复制级别,默认值为1。Alluxio将在后台持久化进程完成之前保持文件的目标复制级别,并且之后回收Alluxio中的空间,因此数据只会写入UFS一次。
如果您正在写入副本ASYNC_THROUGH并且所有具有副本的worker在您保存数据之前崩溃,那么您将导致数据丢失。
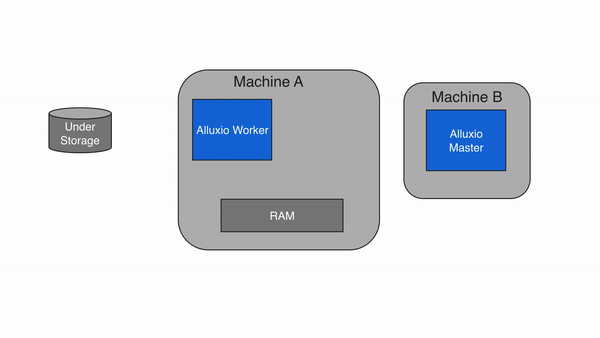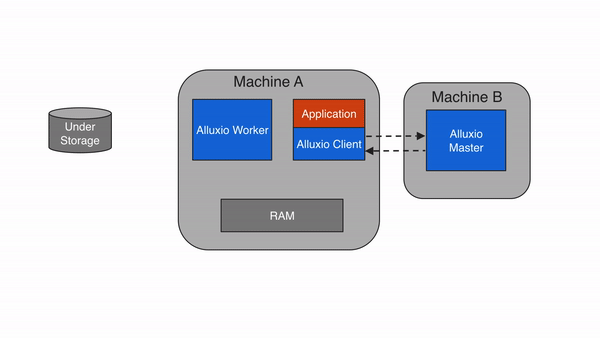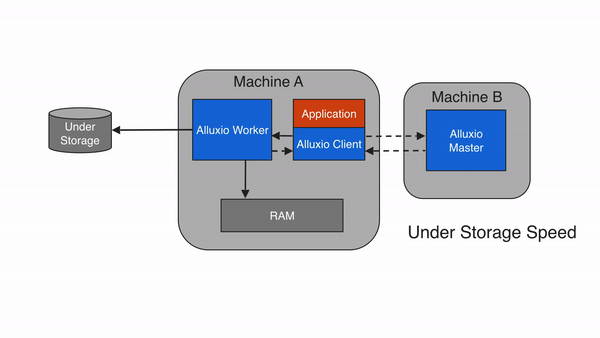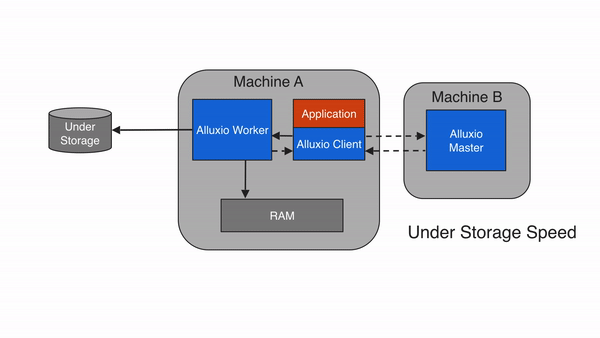
2.6.4 仅写入 UFS ( THROUGH)
使用THROUGH,数据被同步写入under storage,而不会缓存到Alluxio worker。这种写类型保证了写完成后数据会持久化,但是速度受限于under storage的吞吐量。
2.6.5 数据一致性
无论写入类型如何,Alluxio 空间中的文件/目录始终是强一致的,因为所有这些写入操作都将首先通过 Alluxio master 并在将成功返回给客户端/应用程序之前修改 Alluxio 文件系统。因此,只要其对应的写操作成功完成,不同的 Alluxio 客户端将始终看到最新的更新。
但是,对于考虑 UFS 中状态的用户或应用程序,它可能因写入类型而异:
MUST_CACHE不向 UFS 写入数据,因此 Alluxio 空间永远不会与 UFS 保持一致。- CACHE_THROUGH 在将成功返回给应用程序之前,将数据同步写入 Alluxio 和 UFS。
- 如果写入UFS也是强一致性(例如HDFS),如果UFS中没有其他带外更新,Alluxio空间将始终与UFS一致;
- 如果写入 UFS 最终一致(例如 S3),则文件可能成功写入 Alluxio,但稍后会显示在 UFS 中。在这种情况下,Alluxio 客户端仍然会看到一致的文件系统,因为他们总是会咨询强一致性的 Alluxio master;因此,尽管不同的 Alluxio 客户端仍然在 Alluxio 空间中看到一致的状态,但在数据最终传播到 UFS 之前可能会有一个不一致的窗口。
ASYNC_THROUGH将数据写入 Alluxio 并返回到应用程序,让 Alluxio 将数据异步传播到 UFS。从用户的角度来看,该文件可以成功写入Alluxio,但稍后会在UFS中持久化。THROUGH直接将数据写入 UFS,无需在 Alluxio 中缓存数据,但是,Alluxio 知道文件及其状态。因此元数据仍然是一致的。
策略 注释 MUST_CACHE 只写入缓存 CACHE_THROUGH 同步写入缓存和底层存储系统 ASYNC_THROUGH 异步写入缓存和底层存储系统,调用jobmaster和jobworker完成 THROUGH 只写入底层存储
三、核心功能
3.1 Alluxio存储概述
Alluxio在帮助统一跨各种平台用户数据的同时还有助于为用户提升总体I/O吞吐量。 Alluxio是通过把存储分为两个不同的类别来实现这一目标的。
- UFS(底层文件存储,也称为底层存储)该存储空间代表不受Alluxio管理的空间。 UFS存储可能来自外部文件系统,包括如HDFS或S3。 Alluxio可能连接到一个或多个UFS并在一个命名空间中统一呈现这类底层存储。 -通常,UFS存储旨在相当长一段时间持久存储大量数据。
- Alluxio存储
- Alluxio做为一个分布式缓存来管理Alluxio workers本地存储,包括内存。这个在用户应用程序与各种底层存储之间的快速数据层带来的是显著提高的I/O性能;
- Alluxio存储主要用于存储热数据,暂态数据,而不是长期持久数据存储;
- 每个Alluxio节点要管理的存储量和类型由用户配置决定;
- 即使数据当前不在Alluxio存储中,通过Alluxio连接的UFS中的文件仍然对Alluxio客户可见。当客户端尝试读取仅可从UFS获得的文件时数据将被复制到Alluxio存储中。
Alluxio存储通过将数据存储在计算节点内存中来提高性能。 Alluxio存储中的数据可以被复制来形成“热”数据,更易于I/O并行操作和使用。
Alluxio中的数据副本独立于UFS中可能已存在的副本。 Alluxio存储中的数据副本数是由集群活动动态决定的。 由于Alluxio依赖底层文件存储来存储大部分数据, Alluxio不需要保存未使用的数据副本。
Alluxio还支持让系统存储软件可感知的分层存储,使类似L1/L2 CPU缓存一样的数据存储优化成为可能。
3.2 配置Alluxio存储
3.2.1 单层存储
配置Alluxio存储的最简单方法是使用默认的单层模式。
请注意,此部分是讲本地存储,诸如mount之类的术语指在本地存储文件系统上挂载,不要与Alluxio的外部底层存储的mount概念混淆。
在启动时,Alluxio将在每个worker节点上发放一个ramdisk并占用一定比例的系统的总内存。 此ramdisk将用作分配给每个Alluxio worker的唯一存储介质。
通过Alluxio配置中的alluxio-site.properties来配置Alluxio存储。 详细信息见configuration settings。
对默认值的常见修改是明确设置ramdisk的大小。 例如,设置每个worker的ramdisk大小为16GB:
1 | =16GB |
另一个常见更改是指定多个存储介质,例如ramdisk和SSD。 需要 更新alluxio.worker.tieredstore.level0.dirs.path以指定想用的每个存储介质 为一个相应的存储目录。 例如,要使用ramdisk(挂载在/mnt/ramdisk上)和两个SSD(挂载在/mnt/ssd1和/mnt/ssd2):
1 | =/mnt/ramdisk,/mnt/ssd1,/mnt/ssd2 |
请注意,介质类型的顺序必须与路径的顺序相符。 MEM和SSD是Alluxio中的两种预配置存储类型。 alluxio.master.tieredstore.global.mediumtype是包含所有可用的介质类型的配置参数,默认情况下设置为MEM,SSD,HDD。 如果用户有额外存储介质类型可以通过修改这个配置来增加。
提供的路径应指向挂载适当存储介质的本地文件系统中的路径。 为了实现短路操作,对于这些路径,应允许客户端用户在这些路径上进行读取,写入和执行。 例如,对于与启动Alluxio服务的用户组同组用户应给予770权限。
更新存储介质后,需要指出每个存储目录分配了多少存储空间。 例如,如果要在ramdisk上使用16 GB,在每个SSD上使用100 GB:
1 | =16GB,100GB,100GB |
注意存储空间配置的顺序一定与存储目录的配置相符。
Alluxio在通过Mount或SudoMount选项启动时,配置并挂载ramdisk。 这个ramdisk大小是由alluxio.worker.ramdisk.size确定的。 默认情况下,tier 0设置为MEM并且管理整个ramdisk。 此时alluxio.worker.tieredstore.level0.dirs.quota的值同alluxio.worker.ramdisk.size一样。 如果tier0要使用除默认的ramdisk以外的设备,应该显式地设置alluxio.worker.tieredstore.level0.dirs.quota选项。
3.2.2 多层存储
通常建议异构存储介质也使用单个存储层。 在特定环境中,工作负载将受益于基于I/O速度存储介质明确排序。 Alluxio假定根据按I/O性能从高到低来对多层存储进行排序。 例如,用户经常指定以下层:
- MEM(内存)
- SSD(固态存储)
- HDD(硬盘存储)
3.2.2.1 写数据
用户写新的数据块时,默认情况下会将其写入顶层存储。如果顶层没有足够的可用空间, 则会尝试下一层存储。如果在所有层上均未找到存储空间,因Alluxio的设计是易失性存储,Alluxio会释放空间来存储新写入的数据块。 根据块注释策略,空间释放操作会从work中释放数据块。 块注释策略。 如果空间释放操作无法释放新空间,则写数据将失败。
注意:新的释放空间模型是同步模式并会代表要求为其要写入的数据块释放新空白存储空间的客户端来执行释放空间操作。 在块注释策略的帮助下,同步模式释放空间不会引起性能下降,因为总有已排序的数据块列表可用。 然而,可以将alluxio.worker.tieredstore.free.ahead.bytes(默认值:0)配置为每次释放超过释放空间请求所需字节数来保证有多余的已释放空间满足写数据需求。
用户还可以通过configuration settings来指定写入数据层。
3.2.2.2 读取数据
如果数据已经存在于Alluxio中,则客户端将简单地从已存储的数据块读取数据。 如果将Alluxio配置为多层,则不一定是从顶层读取数据块, 因为数据可能已经透明地挪到更低的存储层。
用ReadType.CACHE_PROMOTE读取数据将在从worker读取数据前尝试首先将数据块挪到顶层存储。也可以将其用作为一种数据管理策略 明确地将热数据移动到更高层存储读取。
3.2.2.3 配置分层存储
可以使用以下方式在Alluxio中启用分层存储 配置参数。 为Alluxio指定额外存储层,使用以下配置参数:
1 | alluxio.worker.tieredstore.levels |
例如,如果计划将Alluxio配置为具有两层存储,内存和硬盘存储, 可以使用类似于以下的配置:
1 | # configure 2 tiers in Alluxio |
可配置层数没有限制 但是每个层都必须使用唯一的别名进行标识。 典型的配置将具有三层,分别是内存,SSD和HDD。 要在HDD层中使用多个硬盘存储,需要在配置alluxio.worker.tieredstore.level{x}.dirs.path时指定多个路径。
3.2.3 块注释策略
Alluxio从v2.3开始使用块注释策略来维护存储中数据块的严格顺序。 注释策略定义了跨层块的顺序,并在以下操作过程中进行用来参考: -释放空间 -动态块放置。
与写操作同步发生的释放空间操作将尝试根据块注释策略强制顺序删除块并释放其空间给写操作。注释顺序的最后一个块是第一个释放空间候选对象,无论它位于哪个层上。
开箱即用的注释策略实施包括:
- LRUAnnotator:根据最近最少使用的顺序对块进行注释和释放。 这是Alluxio的默认注释策略。
- LRFUAnnotator:根据配置权重的最近最少使用和最不频繁使用的顺序对块进行注释。
- 如果权重完全偏设为最近最少使用,则行为将 与LRUAnnotator相同。
- 适用的配置属性包括
alluxio.worker.block.annotator.lrfu.step.factoralluxio.worker.block.annotator.lrfu.attenuation.factor。
workers选择使用的注释策略由Alluxio属性 alluxio.worker.block.annotator.class决定。 该属性应在配置中指定完全验证的策略名称。当前可用的选项有:
alluxio.worker.block.annotator.LRUAnnotatoralluxio.worker.block.annotator.LRFUAnnotator
3.2.3.1 释放空间模拟
旧的释放空间策略和Alluxio提供的实施现在已去掉了,并用适当的注释策略替换。 配置旧的Alluxio释放空间策略将导致worker启动失败,并报错java.lang.ClassNotFoundException。 同样,旧的基于水位标记配置已失效。因此,以下配置选项是无效的:
alluxio.worker.tieredstore.levelX.watermark.low.ratioalluxio.worker.tieredstore.levelX.watermark.high.ratio
然而,Alluxio支持基于自定义释放空间实施算法数据块注释的仿真模式。该仿真模式假定已配置的释放空间策略创建一个基于某种顺序释放空间的计划,并通过定期提取这种自定义顺序来支持块注释活动。
旧的释放空间配置应进行如下更改。 (由于旧的释放空间实施已删除,如未能更改基于旧实施的以下配置就会导致class加载错误。)
-LRUEvictor-> LRUAnnotator -GreedyEvictor-> LRUAnnotator -PartialLRUEvictor-> LRUAnnotator -LRFUEvictor-> LRFUAnnotator
3.2.4 分层存储管理
因为块分配/释放不再强制新的写入必须写到特定存储层,新数据块可能最终被写到任何已配置的存储层中。这样允许写入超过Alluxio存储容量的数据。但是,这就需要Alluxio动态管理块放置。 为了确保层配置为从最快到最慢的假设,Alluxio会基于块注释策略在各层存储之间移动数据块。
每个单独层管理任务都遵循以下配置:
alluxio.worker.management.task.thread.count:管理任务所用线程数。 (默认值:CPU核数)alluxio.worker.management.block.transfer.concurrency.limit:可以同时执行多少个块传输。 (默认:CPU核数/2)
3.2.4.1 块对齐(动态块放置)
Alluxio将动态地跨层移动数据块,以使块组成与配置的块注释策略一致。
为辅助块对齐,Alluxio会监视I/O模式并会跨层重组数据块,以确保 较高层的最低块比下面层的最高块具有更高的次序。
这是通过“对齐”这个管理任务来实现的。此管理任务在检测到层之间 顺序已乱时,会通过在层之间交换块位置来有效地将各层与已配置的注释策略对齐以消除乱序。 有关如何控制这些新的后台任务对用户I/O的影响,参见管理任务推后部分。
用于控制层对齐:
alluxio.worker.management.tier.align.enabled:是否启用层对齐任务。 (默认:true)alluxio.worker.management.tier.align.range:单个任务运行中对齐多少个块。 (默认值:100)alluxio.worker.management.tier.align.reserved.bytes:配置多层时,默认情况下在所有目录上保留的空间大小。 (默认:1GB) 用于内部块移动。alluxio.worker.management.tier.swap.restore.enabled:控制一个特殊任务,该任务用于在内部保留空间用尽时unblock层对齐。 (默认:true) 由于Alluxio支持可变的块大小,因此保留空间可能会用尽,因此,当块大小不匹配时在块对齐期间在层之间块交换会导致一个目录保留空间的减少。
3.2.4.2 块升级
当较高层具有可用空间时,低层的块将向上层移动,以便更好地利用较快的磁盘介质,因为假定较高的层配置了较快的磁盘介质。
用于控制动态层升级:
alluxio.worker.management.tier.promote.enabled:是否启用层升级任务。 (默认:true)alluxio.worker.management.tier.promote.range:单个任务运行中升级块数。 (默认值:100)alluxio.worker.management.tier.promote.quota.percent:每一层可以用于升级最大百分比。 一旦其已用空间超过此值,向此层升级将停止。 (0表示永不升级,100表示总是升级。)
3.2.4.3 管理任务推后
层管理任务(对齐/升级)会考虑用户I/O并在worker/disk重载情况下推后运行。 这是为了确保内部管理任务不会对用户I/O性能产生负面影响。
可以在alluxio.worker.management.backoff.strategy属性中设置两种可用的推后类型,分别是Any和DIRECTORY。
ANY; 当有任何用户I/O时,worker管理任务将推后。 此模式将确保较低管理任务开销,以便提高即时用户I/O性能。 但是,管理任务要取得进展就需要在worker上花更长的时间。DIRECTORY; 管理任务将从有持续用户I/O的目录中推后。 此模式下管理任务更易取得进展。 但是,由于管理任务活动的增加,可能会降低即时用户I/O吞吐量。
影响这两种推后策略的另一个属性是alluxio.worker.management.load.detection.cool.down.time,控制多长时间的用户I/O计为在目标directory/worker上的一个负载。
3.3 Alluxio中数据生命周期管理
用户需要理解以下概念,以正确利用可用资源:
- free:释放数据是指从Alluxio缓存中删除数据,而不是从底层UFS中删除数据。 释放操作后,数据仍然可供用户使用,但对Alluxio释放文件后尝试访问该文件 的客户端来讲性能可能会降低。
- load:加载数据意味着将其从UFS复制到Alluxio缓存中。如果Alluxio使用基于内存的存储,加载后用户可能会看到I/O性能的提高。
- persist:持久数据是指将Alluxio存储中可能被修改过或未被修改过的数据写回UFS。 通过将数据写回到UFS,可以保证如果Alluxio节点发生故障数据还是可恢复的。
- TTL(Time to Live):TTL属性设置文件和目录的生存时间,以在数据超过其生存时间时将它们从Alluxio空间中删除。还可以配置 TTL来删除存储在UFS中的相应数据。
3.3.1 从Alluxio存储中释放数据
为了在Alluxio中手动释放数据,可以使用./bin/alluxio文件系统命令 行界面。
1 | ./bin/alluxio fs free ${PATH_TO_UNUSED_DATA} |
这将从Alluxio存储中删除位于给定路径的数据。如果数据是持久存储到UFS的则仍然可以访问该数据。有关更多信息,参考 命令行界面文档
注意,用户通常不需要手动从Alluxio释放数据,因为配置的注释策略将负责删除未使用或旧数据。
3.3.2 将数据加载到Alluxio存储中
如果数据已经在UFS中,使用 alluxio fs load
1 | ./bin/alluxio fs load ${PATH_TO_FILE} |
要从本地文件系统加载数据,使用命令 alluxio fs copyFromLocal。 这只会将文件加载到Alluxio存储中,而不会将数据持久保存到UFS中。 将写入类型设置为MUST_CACHE写入类型将不会将数据持久保存到UFS, 而设置为CACHE和CACHE_THROUGH将会持久化保存。不建议手动加载数据,因为,当首次使用文件时Alluxio会自动将数据加载到Alluxio缓存中。
3.3.3 在Alluxio中持久化保留数据
命令alluxio fs persist 允许用户将数据从Alluxio缓存推送到UFS。
1 | ./bin/alluxio fs persist ${PATH_TO_FILE} |
如果您加载到Alluxio的数据不是来自已配置的UFS,则上述命令很有用。 在大多数情况下,用户不必担心手动来持久化保留数据。
3.3.4 设置生存时间(TTL)
Alluxio支持命名空间中每个文件和目录的”生存时间(TTL)”设置。此功能可用于有效地管理Alluxio缓存,尤其是在严格保证数据访问模式的环境中。例如,如果对上一周提取数据进行分析, 则TTL功能可用于明确刷新旧数据,从而为新文件释放缓存空间。
Alluxio具有与每个文件或目录关联的TTL属性。这些属性将保存为日志的一部分,所以集群重启后也能持久保持。活跃master节点负责当Alluxio提供服务时将元数据保存在内存中。在内部,master运行一个后台线程,该线程定期检查文件是否已达到其TTL到期时间。
注意:后台线程按配置的间隔运行,默认设置为一个小时。 在检查后立即达到其TTL期限的数据不会马上删除, 而是等到一个小时后下一个检查间隔才会被删除。
如将间隔设置为10分钟,在alluxio-site.properties添加以下配置:
1 | =10m |
请参考配置页 CN以获取有关设置Alluxio配置的更多详细信息。
3.3.4.1 API
有两种设置路径的TTL属性的方法。
- 通过Alluxio shell命令行
- 每个元数据加载或文件创建被动设置
TTL API如下:
1 | SetTTL(path,duration,action) |
3.3.4.2 命令行用法
了解如何使用setTtl命令在Alluxio shell中修改TTL属性参阅详细的 命令行文档。
3.3.4.3 Alluxio中文件上的被动TTL设置
Alluxio客户端可以配置为只要在Alluxio命名空间添加新文件时就添加TTL属性。 当预期用户是临时使用文件情况下,被动TTL很有用 ,但它不灵活,因为来自同一客户端的所有请求将继承 相同的TTL属性。
被动TTL通过以下选项配置:
alluxio.user.file.create.ttl:在Alluxio中文件上设置的TTL持续时间。 默认情况下,未设置TTL持续时间。alluxio.user.file.create.ttl.action:对文件设置的TTL到期后的操作 在Alluxio中。注意:默认情况下,此操作为“DELETE”,它将导致文件永久被删除。
TTL默认情况下处于不使用状态,仅当客户有严格数据访问模式才启用。
例如,要3分钟后删除由runTests创建的文件:
1 | ./bin/alluxio runTests -Dalluxio.user.file.create.ttl=3m \ |
对于这个例子,确保alluxio.master.ttl.checker.interval被设定为短间隔,例如一分钟,以便master能快速识别过期文件。
3.4 在Alluxio中管理数据复制
3.4.1 被动复制
与许多分布式文件系统一样,Alluxio中的每个文件都包含一个或多个分布在集群中存储的存储块。默认情况下,Alluxio可以根据工作负载和存储容量自动调整不同块的复制级别。例如,当更多的客户以类型CACHE或CACHE_PROMOTE请求来读取此块时Alluxio可能会创建此特定块更多副本。当较少使用现有副本时,Alluxio可能会删除一些不常用现有副来为经常访问的数据征回空间(块注释策略)。 在同一文件中不同的块可能根据访问频率不同而具有不同数量副本。
默认情况下,此复制或征回决定以及相应的数据传输对访问存储在Alluxio中数据的用户和应用程序完全透明。
3.4.2 主动复制
除了动态复制调整之外,Alluxio还提供API和命令行 界面供用户明确设置文件的复制级别目标范围。 尤其是,用户可以在Alluxio中为文件配置以下两个属性:
alluxio.user.file.replication.min是此文件的最小副本数。 默认值为0,即在默认情况下,Alluxio可能会在文件变冷后从Alluxio管理空间完全删除该文件。 通过将此属性设置为正整数,Alluxio 将定期检查此文件中所有块的复制级别。当某些块的复制数不足时,Alluxio不会删除这些块中的任何一个,而是主动创建更多副本以恢复其复制级别。alluxio.user.file.replication.max是最大副本数。一旦文件该属性设置为正整数,Alluxio将检查复制级别并删除多余的副本。将此属性设置为-1为不设上限(默认情况),设置为0以防止在Alluxio中存储此文件的任何数据。注意,alluxio.user.file.replication.max的值必须不少于alluxio.user.file.replication.min。
例如,用户可以最初使用至少两个副本将本地文件/path/to/file复制到Alluxio:
1 | ./bin/alluxio fs -Dalluxio.user.file.replication.min=2 \ |
接下来,设置/file的复制级别区间为3到5。需要注意的是,在后台进程中完成新的复制级别范围设定后此命令将马上返回,实现复制目标是异步完成的。
1 | ./bin/alluxio fs setReplication --min 3 --max 5 /file |
设置alluxio.user.file.replication.max为无上限。
1 | ./bin/alluxio fs setReplication --max -1 /file |
重复递归复制目录/dir下所有文件复制级别(包括其子目录)使用-R:
1 | ./bin/alluxio fs setReplication --min 3 --max -5 -R /dir |
要检查的文件的目标复制水平,运行
1 | ./bin/alluxio fs stat /foo |
并在输出中查找replicationMin和replicationMax字段。
3.5 检查Alluxio缓存容量和使用情况
Alluxio shell命令fsadmin report提供可用空间的简短摘要以及其他有用的信息。输出示例如下:
1 | ./bin/alluxio fsadmin report |
Alluxio shell还允许用户检查Alluxio缓存中多少空间可用和在用。
获得Alluxio缓存总使用字节数运行:
1 | ./bin/alluxio fs getUsedBytes |
获得Alluxio缓存以字节为单位的总容量
1 | ./bin/alluxio fs getCapacityBytes |
Alluxio master web界面为用户提供了集群的可视化总览包括已用多少存储空间。可以在http:/{MASTER_IP}:${alluxio.master.web.port}/中找到。 有关Alluxio Web界面的更多详细信息可以在 相关文档 中找到。
四、Alluxio 高可用集群部署
服务规划
| 主机名 | Alluxio 角色 | 依赖服务 |
|---|---|---|
| hadoop1 | master、worker | JDK1.8、zookeeper |
| hadoop2 | master、worker | JDK1.8、zookeeper |
| hadoop3 | worker | JDK1.8、zookeeper |
前置条件
服务器免密登录(确保master可以免密登录到worker节点)
zk环境是可用的Hadoop HDFS是可用的,保存master检查点信息用于HA快速恢复
4.1 安装 jdk
1 | [hadoop@hadoop1 ~]$ tar xf downloads/jdk-8u301-linux-x64.tar.gz |
4.2 配置 Alluxio
准备Alluxio ,在各节点分别下载
1 | [hadoop@hadoop1 ~/downloads]$ wget https://downloads.alluxio.io/downloads/files/2.6.2/alluxio-2.6.2-bin.tar.gz |
编辑 alluxio-site.properties 配置文件
1 | [hadoop@hadoop1 ~/alluxio-2.6.2]$ cp conf/alluxio-site.properties.template conf/alluxio-site.properties |
编辑 masters 配置文件
1 | [hadoop@hadoop2 ~/alluxio-2.6.2]$ vim conf/masters |
编辑 masters 配置文件
1 | [hadoop@hadoop2 ~/alluxio-2.6.2]$ vim conf/workers |
编辑 alluxio-env.sh 配置文件,添加java环境变量
1 | [hadoop@hadoop1 ~/alluxio-2.6.2]$ vim conf/alluxio-env.sh |
将配置颁发到其它alluxio节点上
1 | [hadoop@hadoop1 ~/alluxio-2.6.2]$ scp conf/* hadoop@hadoop2:~/alluxio-2.6.2/conf/ |
确保master节点的
alluxio.master.hostname配置为该节点的本机地址(hadoop2节点的alluxio.master.hostname=hadoop2)
4.3 启动 Alluxio HA 集群
格式 Alluxio,Alluxio 集群在其中一个主节点中使用以下命令
1 | [hadoop@hadoop1 ~/alluxio-2.6.2]$ ./bin/alluxio format |
启动 Alluixo,在可以进行免密登录的机器上执行
1 | [hadoop@hadoop1 ~/alluxio-2.6.2]$ ./bin/alluxio-start.sh all SudoMount |
参数
SudoMount表示使用sudo特权将 RamFS 挂载到每个 worker 上(如果尚未挂载)
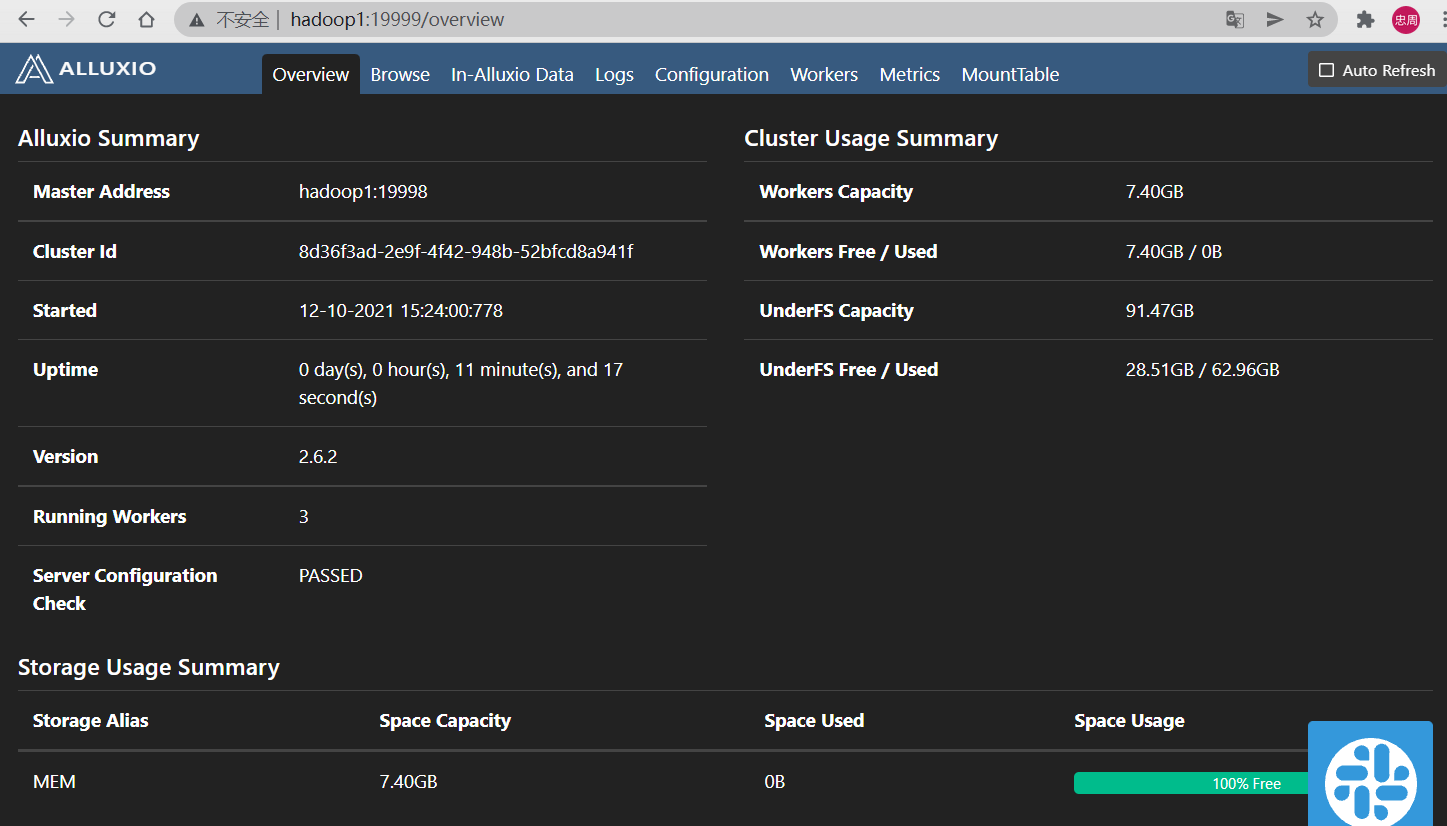
验证 Alluxio 集群
要验证 Alluxio 是否正在运行,您可以访问主master 的 web UI。要确定主master可在任意节点使用 alluxio fs masterInfo 查询
1 | [hadoop@hadoop3 ~/alluxio-2.6.2]$ ./bin/alluxio fs masterInfo |
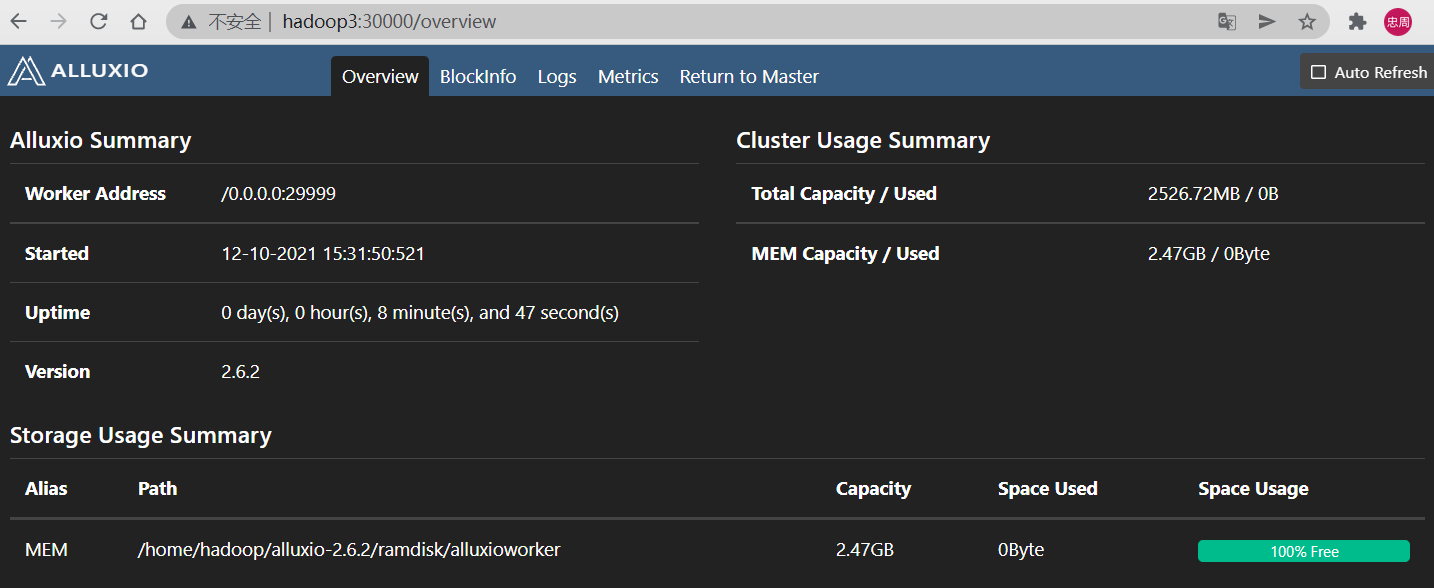
访问 web UI,master和worker都拥有各自的Web UI页面。master Web界面的默认 端口是19999,worker的端口是30000。
4.4 挂载 HDFS 存储
4.4.1 配置文件挂载
编辑Master节点的 alluxio-site.properties 配置文件,添加以下配置
1 | [hadoop@hadoop2 ~/alluxio-2.6.2]$ vim conf/alluxio-site.properties |
Alluxio默认使用本地文件作为文件系统
alluxio.master.mount.table.root.ufs=${alluxio.work.dir}/underFSStorage
重启 Master 服务
1 | [hadoop@hadoop1 ~/alluxio-2.6.2]$ ./bin/alluxio-stop.sh master |
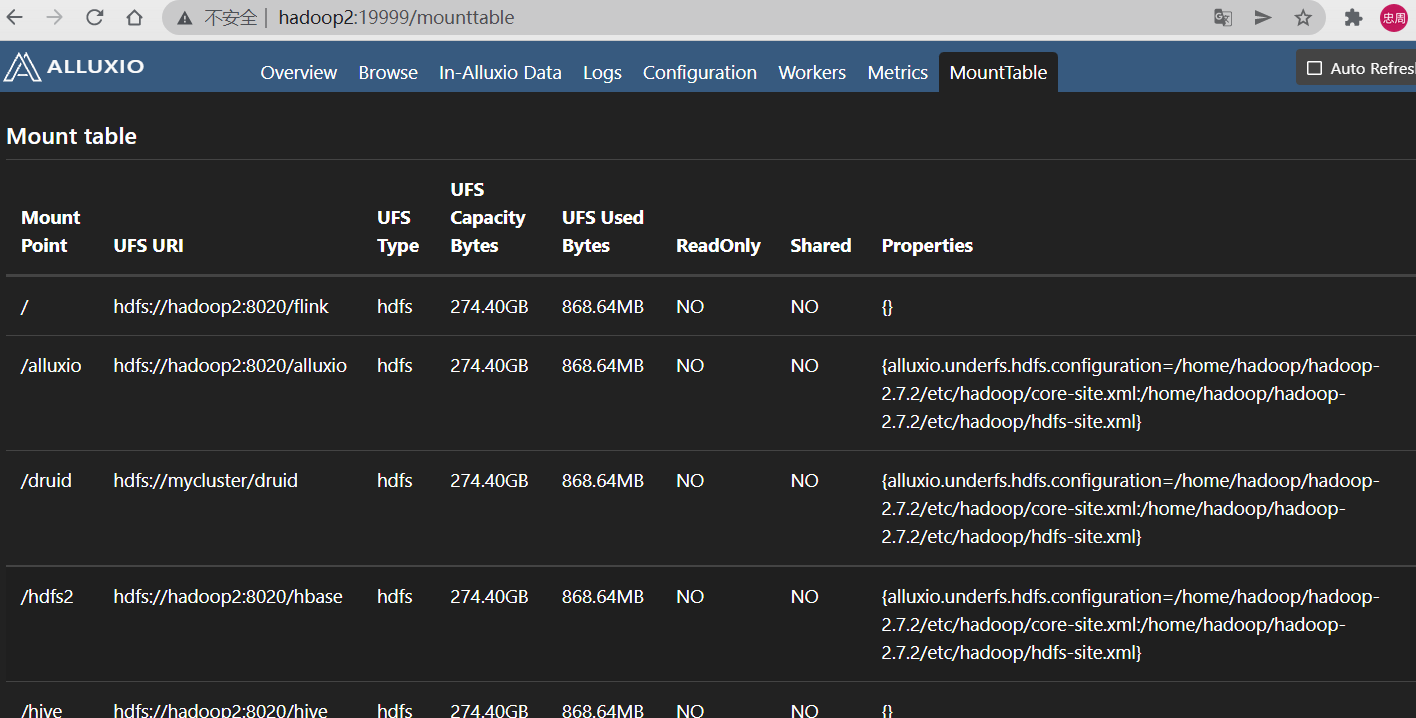
查看挂载的hdfs存储
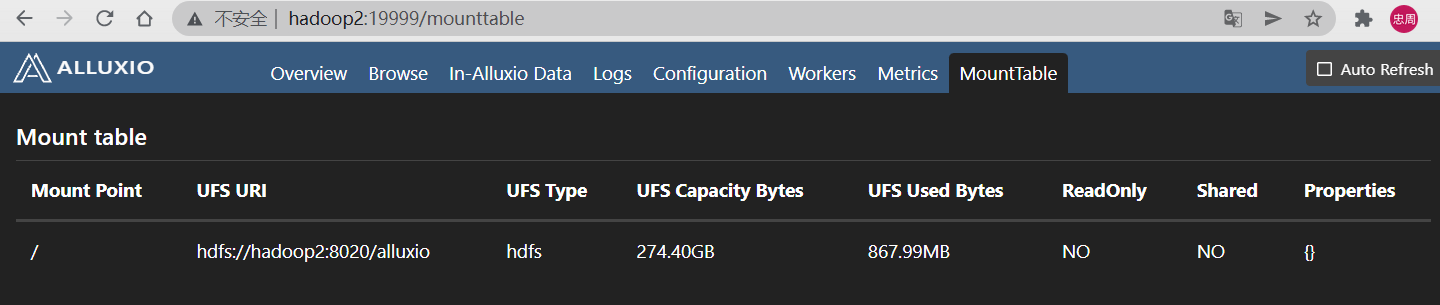
现在已经把hdfs的alluxio目录挂载为alluxio的根目录,接下来我们运行alluxio自带的示例程序
1 | [hadoop@hadoop2 ~/alluxio-2.6.2]$ ./bin/alluxio runTests |
创建完示例文件后可以在alluxio和hdfs查看到了
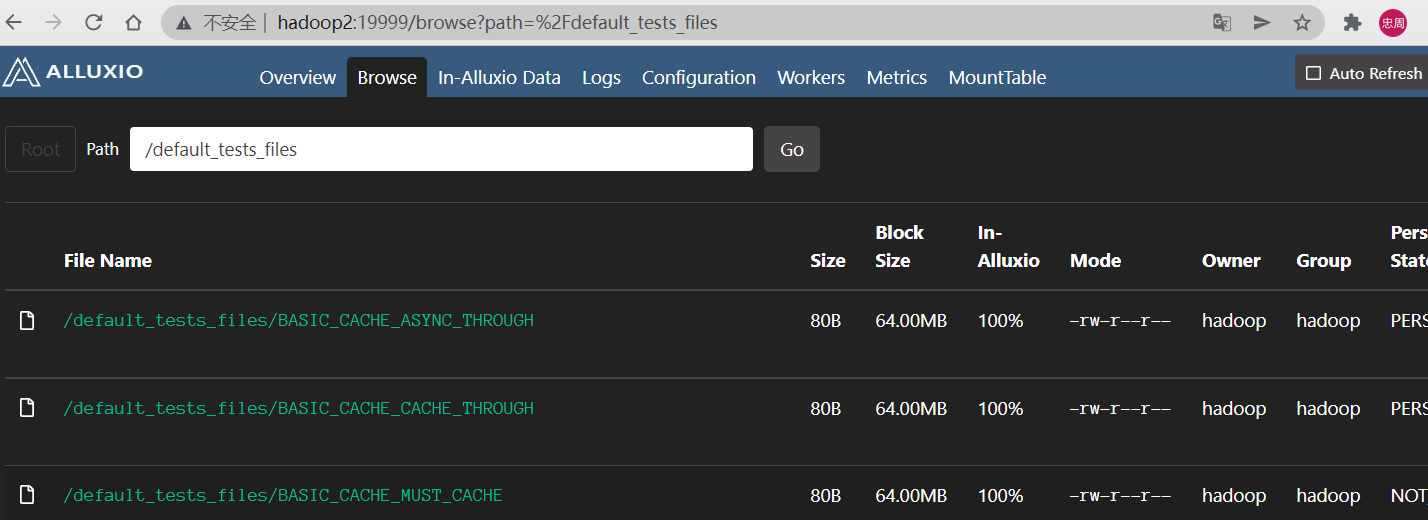
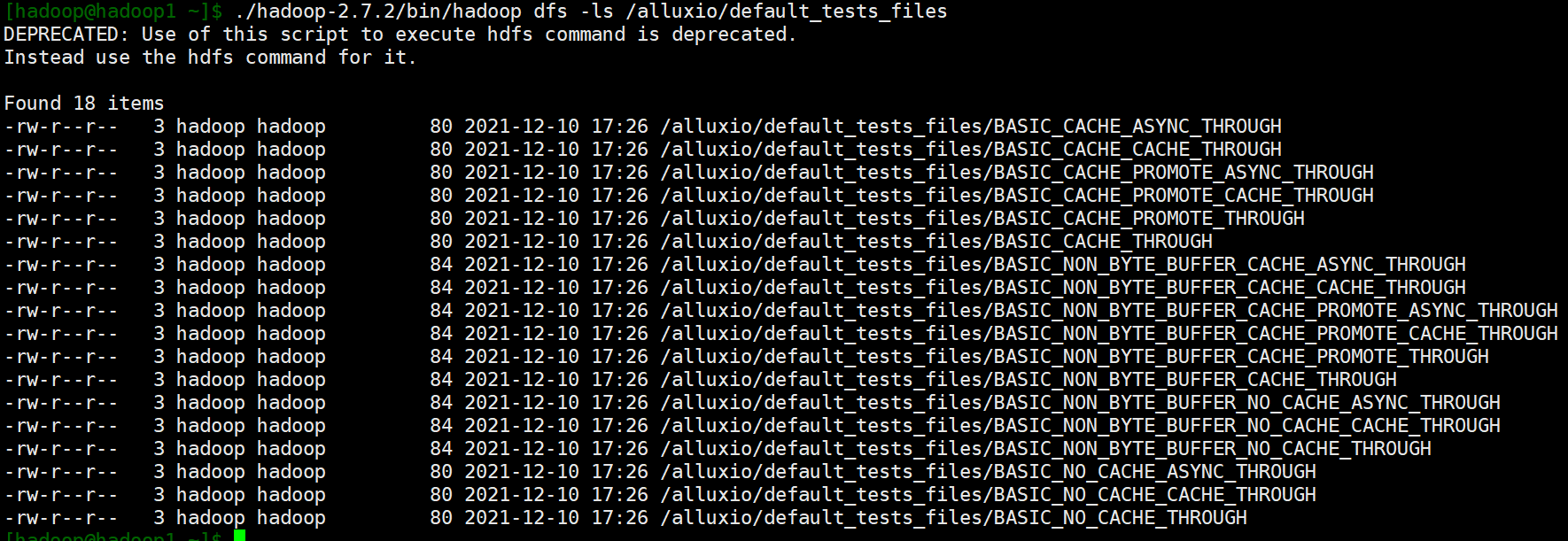
4.4.2 命令行挂载
配置文件挂载,只能挂载到/根目录,如果需要挂载多个hdfs目录或多个hdfs集群,只能通过命令行进行挂载了
1 | 挂载多个hdfs目录 |
查看挂载的hdfs存储